锁住你的记录:sqlserver锁定数据库中的一行记录
关于锁这一块一直没弄懂,刚好今天发现一个比较有意思的帖子,连接为http://bbs.csdn.net/topics/390797757
跟我对锁的疑惑差不多,就是,如何锁定一条记录,防止并发
说是存储过程插入了两条相同的记录,
存储过程的脚本如下:
ALTER PROC [dbo].[Insert]
@Tid Int
AS
BEGIN
IF NOT EXISTS(SELECT 1 FROM Table WHERE TId = @Tid)
BEGIN
INSERT INTO Table (INSERTDATE,TID ) VALUES (GETDATE(), @Tid);
END
END看了一下他的存储过程,也做了是否存在的判断,但这种判断在并发执行下是远远不够的,因为可能有多个会话判断到某一条记录不存在,然后同时插入,所以,出现帖子中描述的问题就不足为奇了,这个测试起来也很简单,接触sqlquerystress这个工具,开启多个线程,每个线程多次循环插入
首先,建立一张表,类似这个一个存储过程,表上建立非唯一的索引
if exists(select 1 from sys.objects where type='U' and name ='testlock1')
drop table testlock1
--建表
create table testlock1
(
id int,
Createdate datetime,
)
--建立索引
create index index_1 on testlock1(id)
--建立存储过程插入数据
create proc ups_TestLock
@i int
as
begin
begin try
begin tran
if not exists(select 1 from t where id=@i )
begin
insert into testlock1 values (@i,GETDATE());
end
commit
end try
begin catch
rollback
end catch
end
关于并发测试,我们借助于sqlquerystress这个工具,下面会有截图,测试脚本如下
declare @i int
set @i=cast( rand()*100000 as int)--生成一个100000以内的随机数
exec test_p @i
在sqlquerystress这个工具中,开启30个线程,每个现成循环插入2000条数据
如截图
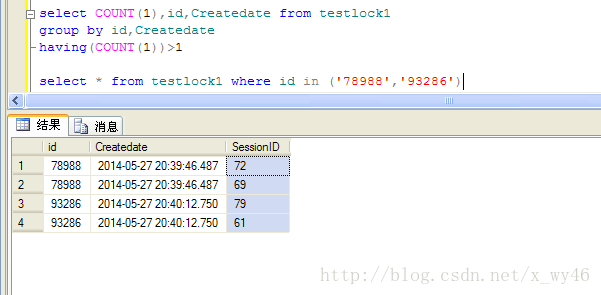
好了,记录插入完成(本文不是性能测试,不用太关注时间指标),有没有重复的数据呢?
直接上图,有图有真相,重复记录还真不少
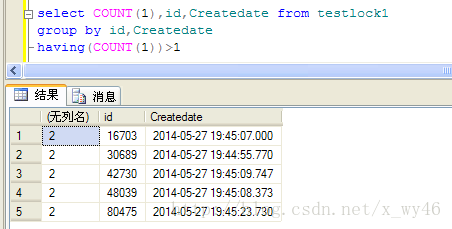
原因在哪里?上面说了,因为可能有多个回话判断到某一条记录不存在,然后同时插入,这样就造成了插入重复数据的情况
那么,改如何做判断才能防止类似的并发造成的问题呢?
于是我想到锁,其实想到锁的时候我心里是没谱的,一直没太弄明白那些显式的锁提示,到底行不行,有没有问题,于是就测试吧
于是我把存储过程改成这样
alter proc ups_TestLock
@i int
as
begin
begin try
begin tran
if not exists(select 1 from t with(xlock,rowlock) where id=@i )--注意这里加上xlock,rowlock,行级排它锁
begin
insert into testlock1 values (@i,GETDATE());
end
commit
end try
begin catch
rollback
end catch
end
令人不解的是这次还有重复记录,虽然比一开始少了一些,但是锁定的问题归总还是没有解决
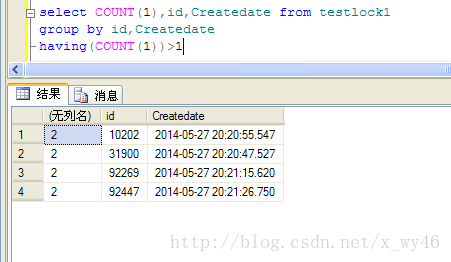
想来想想去不知道问题出在哪里,用sp_lock @@spid查看回话的锁信息的时候,确实有一个key级的排它锁,但是为什么没有锁定记录呢?
如图
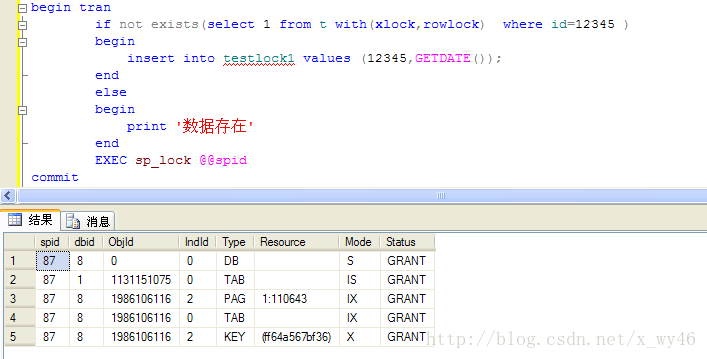
后来上网查,有人说要建立唯一索引,才能锁定一行记录,将索引改成唯一索引后
如下脚本
drop index index_1 on testlock1create unique index index_1 on testlock1(id)在测试,发现确实没有重复记录了,想想是不是巧合呢?
又反反复复测了即便,确实没有重复的,证明在查询条件上建立唯一索引后,然后加上xlock,rowlock后,确实“锁住”记录了,解决了并发问题
事情到这里还没有结束,为什么呢?下班时候,在公交车上还在想这个问题……
后来想想,非唯一索引无法“锁定”记录,出现重复的问题,唯一索引解决了并发,
问题肯定还是并发时候,因为是多线程并行插入的,会不会是不同线程同时插入的,
就是说:A,B两个线程同时插入一条id为12345的数据,他们在插入之前判断的时候,数据库那个时刻中,确实没有id为12345的数据
所以就同时插入了,那么根据这里的推理,重复数据肯定是不同回话插入的,
想起来真令人兴奋,测测看吧
于是我将表结构修改为如下,增加一个插入的回话ID列
if exists(select 1 from sys.objects where type='U' and name ='testlock1')
drop table testlock1
--建表
create table testlock1
(
id int,
Createdate datetime,
SessionID varchar(50)
)
--建立索引
create index index_1 on testlock1(id)
alter proc ups_TestLock
@i int
as
begin
begin try
begin tran
if not exists(select 1 from testlock1 with(xlock,rowlock) where id=@i )
begin
insert into testlock1 values (@i,GETDATE(),@@spid);--这里插入一列回话ID
end
commit
end try
begin catch
rollback
end catch
end
继续用sqlquerystress测试,线程还是30个,每个线程循环插入2000次
再次用该脚本查询
select COUNT(1),id,Createdate from testlock1
group by id,Createdate
having(COUNT(1))>1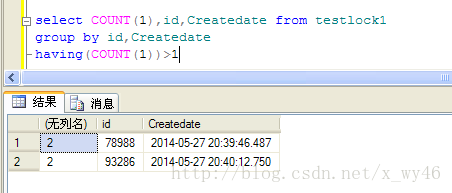
有两条重复的,那么我们就看看这两条重复数据的回话ID吧
果然不出所料!!!
是不同的回话插入的,这也就解释了为么在判断时候加了行级排它锁,却仍然锁不住记录的原因
并发插入的时候,因为各个回话是取数据库中检测记录,数据库中不存在就插入,却忽视了各个会话之间可能存在的重复值
假如是唯一索引,会话之间也是需要等待的,确保索引的唯一性。
这也就解释了,用行级排它锁“锁定”一行记录的时候,在锁定的条件上建议唯一索引的原因。