- Hadoop学习笔记
wyn20001128
hadoop学习笔记
(1)Hadoop概述Hadoop是一个开源的分布式计算和存储框架,用于处理大规模数据集(大数据)的并行处理。它由Apache基金会开发,核心设计灵感来自Google的MapReduce和Google文件系统(GFS)论文。Hadoop的核心优势在于其高容错性、横向扩展能力(可通过增加普通服务器扩展集群)以及低成本(2)Hadoop核心部件(3)一些其他的和Hadoop配合的东西
- [Hadoop学习笔记 1] Hadoop伪分布式环境部署(OpenSUSE 15.6 + Oracle JDK 8)
狼鸭-使银狼永远伟大
Hadoop学习笔记分布式hadoop学习java大数据hdfsyarn
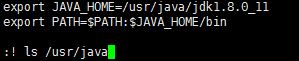
一、安装JDK本文所搭建Hadoop伪分布式环境将使用OracleJDK8,将从OracleJavaSE8ArchiveDownloads页面中下载Linux版本的JDK,下载地址如下:JavaArchiveDownloads-JavaSE8u211andlater建议下载.tar.gz格式的压缩包,以便于对JDK版本做出更为便利的管理,可根据实际需求将JDK压缩包放置到合适的位置,本文将压缩包放
- 探索 Hadoop:学习思路与超强实用性全解析
20210320043-wjw
hadoop学习大数据
在大数据风起云涌的时代,Hadoop已然成为了数据处理领域的中流砥柱。如果你也渴望踏入这个充满机遇的大数据世界,掌握Hadoop绝对是关键一步。今天,就来和大家分享一下学习Hadoop的思路以及它究竟为何如此实用。一、开启学习之旅:步步为营的Hadoop学习思路(一)夯实基础:Java与Linux先行Java功底修炼:Hadoop是基于Java构建的,扎实的Java基础就如同基石般重要。花时间去吃
- 探索 Hadoop:构建大数据处理的基石
大数据 王秀权
hadoop大数据分布式
摘要:本文深入且全面地探讨Hadoop这一强大的大数据处理框架。从其核心概念与架构剖析入手,详细阐述了HDFS、MapReduce和YARN的工作机制与协同关系。通过实际案例展示了Hadoop在数据存储、处理以及分析方面的卓越能力,同时探讨了其在不同行业领域的广泛应用和未来发展趋势,旨在为大数据从业者和爱好者提供一份系统且有深度的Hadoop学习指南。目录一、引言二、Hadoop核心架构解析三、H
- 【hadoop学习之路】Hive HQL 语句实现查询
新世纪debug战士
hadoop学习之路hive
目录表数据表1students_data.txt表2course.txt实验步骤结论表数据表1students_data.txt21434,Sara,F,21,20,73,classC41443,Mary,M,19,30,90,classA43333,Dery,F,20,40,85,classB45454,Mary,F,22,10,91,classA14634,Henry,M,18,50,56,c
- Hadoop3.3.4伪分布式环境搭建
凡许真
分布式hadoop伪分布式hadoop3.3.4
文章目录前言一、准备1.下载Hadoop2.配置环境变量3.配置免密二、Hadoop配置1.hadoop-env.sh2.hdfs-site.xml3.core-site.xml4.mapred-site.xml5.yarn-site.xml三、格式化四、启动五、访问web页面前言hadoop学习——伪分布式环境——普通用户搭建一、准备1.下载Hadoop2.配置环境变量vi~/.bash_pro
- Hadoop学习笔记 --- YARN执行流程与工作原理
杨鑫newlfe
数据仓库大数据挖掘与大数据应用案例YARNHadoop大数据资源调度数据仓库
一、YARN简述首先介绍一下YARN在Hadoop2.0版本引进的资源管理系统,直接从MapReduceV1演化而来(由于引擎的功能缺陷);原因是将MapReduce1中的JobTracker的资源管理和作业调度两个功能分开,分别由ResourceManager和ApplicationMaster进行实现;ResourceManager:负责整个集群的资源管理和调度ApplicationMaste
- Hadoop学习第三课(HDFS架构--读、写流程)
小小程序员呀~
数据库hadoop架构bigdata
1.块概念举例1:一桶水1000ml,瓶子的规格100ml=>需要10个瓶子装完一桶水1010ml,瓶子的规格100ml=>需要11个瓶子装完一桶水1010ml,瓶子的规格200ml=>需要6个瓶子装完块的大小规格,只要是需要存储,哪怕一点点,也是要占用一个块的块大小的参数:dfs.blocksize官方默认的大小为128M官网:https://hadoop.apache.org/docs/r3.
- Python大数据之Hadoop学习——day06_hive学习02
笨小孩124
大数据hadoop学习
一.hive内外表操作1.建表语法create[external]table[ifnotexists]表名(字段名字段类型,字段名字段类型,...)[partitionedby(分区字段名分区字段类型)]#分区表固定格式[clusteredby(分桶字段名)into桶个数buckets]#分桶表固定格式[sortedby(排序字段名asc|desc)][rowformatdelimitedfiel
- C# Hadoop学习笔记
第八个猴子
大数据
记录一下学习地址http://www.360doc.com/content/14/0607/22/3218170_384675141.shtml转载于:https://www.cnblogs.com/TF12138/p/4170558.html
- hadoop学习笔记
草琳情
hadoop学习笔记
下载安装伪分布式:1.国内源下载地址:https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/Indexof/apache/hadoop/commonhttps://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/https://mirrors.tuna.tsinghua.edu.cn/
- Hadoop分布式计算实验踩坑实录及小结
小童同学_
HIThadoop分布式ubuntujava
目录Hadoop分布式计算实验踩坑实录及小结踩坑实录Hadoop学习Hadoop简介HDFSSomeconceptsMapReduce主要配置文件集群搭建来源与引用Hadoop分布式计算实验踩坑实录及小结踩坑实录单机jdk配置Ubuntu下安装jdk11,不熟悉apt-get的默认目录及目录配置,直接在Oracle找了Linux的压缩包在虚拟机上解压,解压到指定目录后配一下java环境变量。/et
- Hadoop:学习HDFS,看完这篇就够了!
爱写代码的July
大数据与云计算hadoop学习hdfs大数据云计算
HDFS(HadoopDistributedFileSystem)是ApacheHadoop生态系统中的分布式文件系统,用于存储和处理大规模数据集。由于其具有高容错性、高可靠性和高吞吐量等特点,因此广泛应用于大数据处理和分析场景。一认识Hadoop学习HDFS之前,让我们先来简单认识一下Hadoop是什么?Hadoop是Apache软件基金会旗下的一个开源分布式计算平台,为用户提供了系统底层细节透
- 手把手教Hadoop环境搭建,学不会你咬我~
程序IT圈
hadoopjdklinuxcentoshdfs
之前后台小伙伴私信我想了解hadoop的单机环境安装,以方便用于hadoop学习,今天给大家安排上了,废话不多说,直接上干货。目录前置条件配置SSH免密登录Hadoop(HDFS)环境搭建Hadoop(YARN)环境搭建1、前置条件Hadoop的运行依赖JDK,需要预先安装,安装步骤见:1.1下载并解压在官网下载所需版本的JDK,这里我下载的版本为JDK1.8,下载后进行解压:[root@ jav
- Hadoop学习之路(七) MapReduce框架Partitioner分区
shine_rainbow
Partitioner分区的作用是什么?在进行MapReduce计算时,有时候需要把最终输出数据分到不同的文件中,比如按照省份划分的话,需要把同一省份的数据放到一个文件中;按照性别划分的话,需要把同一性别的数据放到一个文件中。我们知道最终的输出数据是来自于Reducer任务。那么如果要得到多个文件,意味着有相同数量的Reducer任务在运行。Reducer任务的数据来自于Mapper任务,也就是M
- 《Hadoop大数据技术原理与运用》知识点总结
呆小黎
大数据hadoop数据库分布式
Hadoop学习过程中的一些笔记参考书籍《Hadoop大数据技术原理与应用》清华大学出版社黑马程序员/编著1.什么是大数据?大数据的四个特征是什么?答:一种规模大到在获取、存储、管理、分析方面大大超出了传统数据库软件工具能力范围的数据集合具有海量数据规模、快速数据流转、多样数据类型一级价值密度四大特征。2.另外,在Hadoop架构里面,元数据的含义是什么?答:文件的大小、位置、权限3.本书里面使用
- 第一章 大数据Hadoop学习笔记(一)
Thanks.
hadoop学习大数据
一、存储单位按顺序给出数据存储单位:bit、Byte、KB、MB、GB、TB、PB、EB、ZB、YB、BB、NB、DB。一般TB、PB、EB为单位的数据为大数据。1Byte=8bit1K=1024Byte1MB=1024K1G=1024M1T=1024G1P=1024T二、大数据主要解决海量数据的采集、存储和分析计算问题。三、大数据特点(4V)Volume(大量)、Velocity(高速)、Var
- Hadoop学习之路(四)HDFS 读写流程详解
shine_rainbow
1.HDFS写操作1.1图解HDFS读过程hdfs写操作流程图.pngimage.png1.2数据写入过程详解1、使用HDFS提供的客户端Client,向远程的NameNode发起RPC请求;2、NameNode会检查要创建的文件是否已经存在,创建者是否有权限进行操作,成功则会为文件创建一个记录,否则会让客户端抛出异常;3、当客户端开始写入文件的时候,客户端会将文件切分为多个packets,并在内
- 【大数据进阶第三阶段之Hive学习笔记】Hive安装
伊达
Hive大数据大数据hive学习
1、环境准备安装hadoop以及zookeeper、mysql【大数据进阶第二阶段之Hadoop学习笔记】Hadoop运行环境搭建-CSDN博客《zookeeper的安装与配置》自行百度《Linux环境配置MySQL》自行百度2、下载安装CSDN下载:https://download.csdn.net/download/liguohuaty/88702104Hive官网下载:Downloads(a
- 大数据高级开发工程师——Hadoop学习笔记(4)
讲文明的喜羊羊拒绝pua
大数据hadoopmapreduce
文章目录Hadoop进阶篇MapReduce:Hadoop分布式并行计算框架MapReduce的理解MapReduce的核心思想MapReduce编程模型MapReduce编程指导思想【八大步骤】Map阶段2个步骤shuffle阶段4个步骤reduce阶段2个步骤MapReduce编程入门——单词统计hadoop当中常用的数据类型词频统计MapReduce的运行模式1.本地模式2.集群运行模式Ma
- 【大数据进阶第二阶段之Hadoop学习笔记】Hadoop 概述
伊达
Hadoop大数据大数据学习hadoop
【大数据进阶第二阶段之Hadoop学习笔记】Hadoop概述-CSDN博客【大数据进阶第二阶段之Hadoop学习笔记】Hadoop运行环境搭建-CSDN博客【大数据进阶第二阶段之Hadoop学习笔记】Hadoop运行模式-CSDN博客1、Hadoop是什么(1)Hadoop是一个由Apache基金会所开发的分布式系统基础架构(2)主要解决海量数据的存储和海量数据的分析计算问题(3)广义上来说,Ha
- 【大数据进阶第二阶段之Hadoop学习笔记】Hadoop 运行环境搭建
伊达
大数据Hadoop大数据hadoop学习
【大数据进阶第二阶段之Hadoop学习笔记】Hadoop概述-CSDN博客【大数据进阶第二阶段之Hadoop学习笔记】Hadoop运行环境搭建-CSDN博客【大数据进阶第二阶段之Hadoop学习笔记】Hadoop运行模式-CSDN博客1、模板虚拟机环境准备1.1、hadoop100虚拟机配置要求如下(1)使用yum安装需要虚拟机可以正常上网,yum安装前可以先测试下虚拟机联网情况[root@had
- 【大数据进阶第二阶段之Hadoop学习笔记】Hadoop 运行模式
伊达
大数据hadoop学习
【大数据进阶第二阶段之Hadoop学习笔记】Hadoop概述-CSDN博客【大数据进阶第二阶段之Hadoop学习笔记】Hadoop运行环境搭建-CSDN博客【大数据进阶第二阶段之Hadoop学习笔记】Hadoop运行模式-CSDN博客目录1、Hadoop运行模式2、编写集群分发脚本xsync2.1、scp(securecopy):安全拷贝2.2、rsync远程同步工具2.3、xsync集群分发脚本
- 大数据Hadoop入门学习线路图
千_锋小小千
Hadoop是系统学习大数据的必会知识之一,Hadoop里面包括几个组件HDFS、MapReduce和YARN,HDFS是存储数据的地方就像我们电脑的硬盘一样文件都存储在这个上面,MapReduce是对数据进行处理计算的。YARN是一种新的Hadoop资源管理器,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。如何入门Hadoop学习,不妨
- Hadoop学习笔记[6]-MapReduce与Yarn安装部署流程
kinglinch
大数据mapreduceyarnhadoop大数据
Hadoop学习笔记[6]-MapReduce与Yarn安装部署流程 前面的文章已经对MR和Yarn做了基本介绍,本文主要介绍MR和Yarn的安装部署流程1、角色划分 NodeManager和DataNode一般都是1:1,主要是为了计算向数据移动,如果NM和DN分开,就得用网路拷贝数据,在Yarn的体系里NM也是从节点,既然其和DN是1:1的关系,所以配置中和HDFS共用一个slaves文件
- 【Hadoop学习笔记】(二)——Hive的原理及使用
wanger61
大数据开发hadoophive大数据
一、Hive概述Hive是一个在Hadoop中用来处理结构化数据的数据仓库基础工具。它架构在Hadoop之上,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。Hive数据仓库工具能为HDFS上的数据提供类似SQL的查询语言(HiveQL),并将SQL语句转变成MapReduce任务来执行。Hive明显降低了Hadoop的使用门槛,任何熟悉SQL的用
- 四、Hadoop学习笔记————各种工具用法
weixin_30528371
大数据数据库
hive基本hql语法Sqoop(发音:skup)是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql...)间进行数据的传递,可以将一个关系型数据库(例如:MySQL,Oracle,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。数据传递转载于:https://www.cnblogs.com/
- Hadoop学习笔记(17)Hive的数据类型和文件编码
柏冉看世界
hadoop
一、Hive的常用内部命令1、有好几种方式可以与Hive进行交互。此处主要是命令行界面(CLI)。2、$HIVE_HOME/bin目录下包含了可以执行各种各样Hive服务的可执行文件,包括hive命令行界面(CLI是使用Hive的最常用方式)。[admin@master~]$cdapache-hive-1.2.2-bin/bin[admin@masterbin]$lsbeelineexthiveh
- 大数据高级开发工程师——Hadoop学习笔记(7)
讲文明的喜羊羊拒绝pua
大数据hadoopbigdatamapreduceyarn
文章目录Hadoop进阶篇YARN:Hadoop资源调度系统什么是YARNYARN架构剖析1.ResourceManager2.NodeManager3.Container4.ApplicationMaster5.JobHistoryServer6.TimelineServerYARN应用运行原理1.YARN应用提交过程2.MapReduceonYARN提交作业初始化作业Task任务分配Task任
- Hadoop学习笔记(一)分布式文件存储系统 —— HDFS
zhang35
大数据技术栈大数据分布式Hadoop入门hdfs
概念HDFS(HadoopDistributedFileSystem),Hadoop分布式文件系统,用来存超大文件的。HDFS遵循主/从架构,由单个NameNode(NN)和多个DataNode(DN)组成:NameNode:负责执行有关文件系统命名空间的操作,例如打开,关闭、重命名文件和目录等。它同时还负责集群元数据的存储,记录着文件中各个数据块的位置信息。管理员,负责协调。DataNode:负
- Enum用法
不懂事的小屁孩
enum
以前的时候知道enum,但是真心不怎么用,在实际开发中,经常会用到以下代码:
protected final static String XJ = "XJ";
protected final static String YHK = "YHK";
protected final static String PQ = "PQ";
- 【Spark九十七】RDD API之aggregateByKey
bit1129
spark
1. aggregateByKey的运行机制
/**
* Aggregate the values of each key, using given combine functions and a neutral "zero value".
* This function can return a different result type
- hive创建表是报错: Specified key was too long; max key length is 767 bytes
daizj
hive
今天在hive客户端创建表时报错,具体操作如下
hive> create table test2(id string);
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. MetaException(message:javax.jdo.JDODataSto
- Map 与 JavaBean之间的转换
周凡杨
java自省转换反射
最近项目里需要一个工具类,它的功能是传入一个Map后可以返回一个JavaBean对象。很喜欢写这样的Java服务,首先我想到的是要通过Java 的反射去实现匿名类的方法调用,这样才可以把Map里的值set 到JavaBean里。其实这里用Java的自省会更方便,下面两个方法就是一个通过反射,一个通过自省来实现本功能。
1:JavaBean类
1 &nb
- java连接ftp下载
g21121
java
有的时候需要用到java连接ftp服务器下载,上传一些操作,下面写了一个小例子。
/** ftp服务器地址 */
private String ftpHost;
/** ftp服务器用户名 */
private String ftpName;
/** ftp服务器密码 */
private String ftpPass;
/** ftp根目录 */
private String f
- web报表工具FineReport使用中遇到的常见报错及解决办法(二)
老A不折腾
finereportweb报表java报表总结
抛砖引玉,希望大家能把自己整理的问题及解决方法晾出来,Mark一下,利人利己。
出现问题先搜一下文档上有没有,再看看度娘有没有,再看看论坛有没有。有报错要看日志。下面简单罗列下常见的问题,大多文档上都有提到的。
1、没有返回数据集:
在存储过程中的操作语句之前加上set nocount on 或者在数据集exec调用存储过程的前面加上这句。当S
- linux 系统cpu 内存等信息查看
墙头上一根草
cpu内存liunx
1 查看CPU
1.1 查看CPU个数
# cat /proc/cpuinfo | grep "physical id" | uniq | wc -l
2
**uniq命令:删除重复行;wc –l命令:统计行数**
1.2 查看CPU核数
# cat /proc/cpuinfo | grep "cpu cores" | u
- Spring中的AOP
aijuans
springAOP
Spring中的AOP
Written by Tony Jiang @ 2012-1-18 (转)何为AOP
AOP,面向切面编程。
在不改动代码的前提下,灵活的在现有代码的执行顺序前后,添加进新规机能。
来一个简单的Sample:
目标类:
[java]
view plain
copy
print
?
package&nb
- placeholder(HTML 5) IE 兼容插件
alxw4616
JavaScriptjquery jQuery插件
placeholder 这个属性被越来越频繁的使用.
但为做HTML 5 特性IE没能实现这东西.
以下的jQuery插件就是用来在IE上实现该属性的.
/**
* [placeholder(HTML 5) IE 实现.IE9以下通过测试.]
* v 1.0 by oTwo 2014年7月31日 11:45:29
*/
$.fn.placeholder = function
- Object类,值域,泛型等总结(适合有基础的人看)
百合不是茶
泛型的继承和通配符变量的值域Object类转换
java的作用域在编程的时候经常会遇到,而我经常会搞不清楚这个
问题,所以在家的这几天回忆一下过去不知道的每个小知识点
变量的值域;
package 基础;
/**
* 作用域的范围
*
* @author Administrator
*
*/
public class zuoyongyu {
public static vo
- JDK1.5 Condition接口
bijian1013
javathreadConditionjava多线程
Condition 将 Object 监视器方法(wait、notify和 notifyAll)分解成截然不同的对象,以便通过将这些对象与任意 Lock 实现组合使用,为每个对象提供多个等待 set (wait-set)。其中,Lock 替代了 synchronized 方法和语句的使用,Condition 替代了 Object 监视器方法的使用。
条件(也称为条件队列或条件变量)为线程提供了一
- 开源中国OSC源创会记录
bijian1013
hadoopsparkMemSQL
一.Strata+Hadoop World(SHW)大会
是全世界最大的大数据大会之一。SHW大会为各种技术提供了深度交流的机会,还会看到最领先的大数据技术、最广泛的应用场景、最有趣的用例教学以及最全面的大数据行业和趋势探讨。
二.Hadoop
&nbs
- 【Java范型七】范型消除
bit1129
java
范型是Java1.5引入的语言特性,它是编译时的一个语法现象,也就是说,对于一个类,不管是范型类还是非范型类,编译得到的字节码是一样的,差别仅在于通过范型这种语法来进行编译时的类型检查,在运行时是没有范型或者类型参数这个说法的。
范型跟反射刚好相反,反射是一种运行时行为,所以编译时不能访问的变量或者方法(比如private),在运行时通过反射是可以访问的,也就是说,可见性也是一种编译时的行为,在
- 【Spark九十四】spark-sql工具的使用
bit1129
spark
spark-sql是Spark bin目录下的一个可执行脚本,它的目的是通过这个脚本执行Hive的命令,即原来通过
hive>输入的指令可以通过spark-sql>输入的指令来完成。
spark-sql可以使用内置的Hive metadata-store,也可以使用已经独立安装的Hive的metadata store
关于Hive build into Spark
- js做的各种倒计时
ronin47
js 倒计时
第一种:精确到秒的javascript倒计时代码
HTML代码:
<form name="form1">
<div align="center" align="middle"
- java-37.有n 个长为m+1 的字符串,如果某个字符串的最后m 个字符与某个字符串的前m 个字符匹配,则两个字符串可以联接
bylijinnan
java
public class MaxCatenate {
/*
* Q.37 有n 个长为m+1 的字符串,如果某个字符串的最后m 个字符与某个字符串的前m 个字符匹配,则两个字符串可以联接,
* 问这n 个字符串最多可以连成一个多长的字符串,如果出现循环,则返回错误。
*/
public static void main(String[] args){
- mongoDB安装
开窍的石头
mongodb安装 基本操作
mongoDB的安装
1:mongoDB下载 https://www.mongodb.org/downloads
2:下载mongoDB下载后解压
- [开源项目]引擎的关键意义
comsci
开源项目
一个系统,最核心的东西就是引擎。。。。。
而要设计和制造出引擎,最关键的是要坚持。。。。。。
现在最先进的引擎技术,也是从莱特兄弟那里出现的,但是中间一直没有断过研发的
- 软件度量的一些方法
cuiyadll
方法
软件度量的一些方法http://cuiyingfeng.blog.51cto.com/43841/6775/在前面我们已介绍了组成软件度量的几个方面。在这里我们将先给出关于这几个方面的一个纲要介绍。在后面我们还会作进一步具体的阐述。当我们不从高层次的概念级来看软件度量及其目标的时候,我们很容易把这些活动看成是不同而且毫不相干的。我们现在希望表明他们是怎样恰如其分地嵌入我们的框架的。也就是我们度量的
- XSD中的targetNameSpace解释
darrenzhu
xmlnamespacexsdtargetnamespace
参考链接:
http://blog.csdn.net/colin1014/article/details/357694
xsd文件中定义了一个targetNameSpace后,其内部定义的元素,属性,类型等都属于该targetNameSpace,其自身或外部xsd文件使用这些元素,属性等都必须从定义的targetNameSpace中找:
例如:以下xsd文件,就出现了该错误,即便是在一
- 什么是RAID0、RAID1、RAID0+1、RAID5,等磁盘阵列模式?
dcj3sjt126com
raid
RAID 1又称为Mirror或Mirroring,它的宗旨是最大限度的保证用户数据的可用性和可修复性。 RAID 1的操作方式是把用户写入硬盘的数据百分之百地自动复制到另外一个硬盘上。由于对存储的数据进行百分之百的备份,在所有RAID级别中,RAID 1提供最高的数据安全保障。同样,由于数据的百分之百备份,备份数据占了总存储空间的一半,因而,Mirror的磁盘空间利用率低,存储成本高。
Mir
- yii2 restful web服务快速入门
dcj3sjt126com
PHPyii2
快速入门
Yii 提供了一整套用来简化实现 RESTful 风格的 Web Service 服务的 API。 特别是,Yii 支持以下关于 RESTful 风格的 API:
支持 Active Record 类的通用API的快速原型
涉及的响应格式(在默认情况下支持 JSON 和 XML)
支持可选输出字段的定制对象序列化
适当的格式的数据采集和验证错误
- MongoDB查询(3)——内嵌文档查询(七)
eksliang
MongoDB查询内嵌文档MongoDB查询内嵌数组
MongoDB查询内嵌文档
转载请出自出处:http://eksliang.iteye.com/blog/2177301 一、概述
有两种方法可以查询内嵌文档:查询整个文档;针对键值对进行查询。这两种方式是不同的,下面我通过例子进行分别说明。
二、查询整个文档
例如:有如下文档
db.emp.insert({
&qu
- android4.4从系统图库无法加载图片的问题
gundumw100
android
典型的使用场景就是要设置一个头像,头像需要从系统图库或者拍照获得,在android4.4之前,我用的代码没问题,但是今天使用android4.4的时候突然发现不灵了。baidu了一圈,终于解决了。
下面是解决方案:
private String[] items = new String[] { "图库","拍照" };
/* 头像名称 */
- 网页特效大全 jQuery等
ini
JavaScriptjquerycsshtml5ini
HTML5和CSS3知识和特效
asp.net ajax jquery实例
分享一个下雪的特效
jQuery倾斜的动画导航菜单
选美大赛示例 你会选谁
jQuery实现HTML5时钟
功能强大的滚动播放插件JQ-Slide
万圣节快乐!!!
向上弹出菜单jQuery插件
htm5视差动画
jquery将列表倒转顺序
推荐一个jQuery分页插件
jquery animate
- swift objc_setAssociatedObject block(version1.2 xcode6.4)
啸笑天
version
import UIKit
class LSObjectWrapper: NSObject {
let value: ((barButton: UIButton?) -> Void)?
init(value: (barButton: UIButton?) -> Void) {
self.value = value
- Aegis 默认的 Xfire 绑定方式,将 XML 映射为 POJO
MagicMa_007
javaPOJOxmlAegisxfire
Aegis 是一个默认的 Xfire 绑定方式,它将 XML 映射为 POJO, 支持代码先行的开发.你开发服 务类与 POJO,它为你生成 XML schema/wsdl
XML 和 注解映射概览
默认情况下,你的 POJO 类被是基于他们的名字与命名空间被序列化。如果
- js get max value in (json) Array
qiaolevip
每天进步一点点学习永无止境max纵观千象
// Max value in Array
var arr = [1,2,3,5,3,2];Math.max.apply(null, arr); // 5
// Max value in Jaon Array
var arr = [{"x":"8/11/2009","y":0.026572007},{"x"
- XMLhttpRequest 请求 XML,JSON ,POJO 数据
Luob.
POJOjsonAjaxxmlXMLhttpREquest
在使用XMlhttpRequest对象发送请求和响应之前,必须首先使用javaScript对象创建一个XMLHttpRquest对象。
var xmlhttp;
function getXMLHttpRequest(){
if(window.ActiveXObject){
xmlhttp:new ActiveXObject("Microsoft.XMLHTTP
- jquery
wuai
jquery
以下防止文档在完全加载之前运行Jquery代码,否则会出现试图隐藏一个不存在的元素、获得未完全加载的图像的大小 等等
$(document).ready(function(){
jquery代码;
});
<script type="text/javascript" src="c:/scripts/jquery-1.4.2.min.js&quo