国防科大登顶SQuAD 2.0排行榜,机器阅读也要“不知为不知”
圆栗子 发自 凹非寺
量子位 出品 | 公众号 QbitAI
最近,国防科大 (NUDT) 登顶SQuAD 2.0排行榜。
击败了微软强敌FusionNet++,机器的阅读理解能力又进化了。

SQuAD 2.0是个阅读理解数据集,机器需要根据文本中的信息,回答问题。
强调一下,所有的答案都要来自文本。
SQuAD 2.0的特殊之处在于,有些问题,文本里并没有答案。
那么,机器回答这些问题的时候,要明确表示“No Answer”。

国防科大和微软亚洲研究院,提出的阅读-验证算法,便是为检测无法回答的问题而生的。
备选答案,需要验证
要找出“不该乱填答案”的问题,常用的方法,就是预测No Answer的概率。
可这样的做法,可能就不会去检测,系统给出的其他备选答案,有多可信了。
于是,国防科大和微软组成的Minghao Hu团队,给算法加入了验证候选答案的步骤,在SQuAD 2.0中获得了74.2 F1的最高分。
这里,阅读器与验证器,都不可缺少。

比如,阅读理解的文章提到,诺曼底是法国的一个地区。
但问题问的是,法国是 ( ) 的一个地区,文中没有提到。
这对人类来说,难度不大,诺曼底可能连干扰项也算不上。但算法会怎么看?
首先,阅读器从文中找出备选答案 ,同时也算出无答案概率 (NA Prob) 。
然后,把备选答案扔给验证器 (Answer Verifier) ,看文中相关句子的表达,能不能回答问题。
最后,把验证器的无答案概率,和第一步的无答案概率,结合到一起,才能决定要不要输出No Answer。
验证答案,并不简单
不过,验证诺曼底是不是问题的答案,需要经过一番推理。
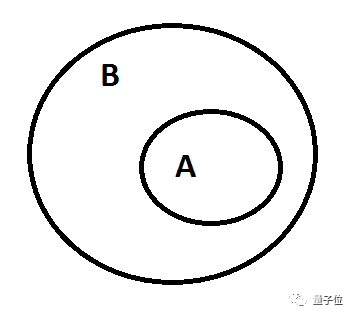
△ If A then B.
还是刚才的栗子,“诺曼底是法国的一个地区”用A表示,“法国是诺曼底的一个地区”用B表示。
如果,A能推出B,答案就是诺曼底。A不能推出B,诺曼底就被淘汰。
把这个验证过程,交给神经网络,团队试了三种不同的模型:
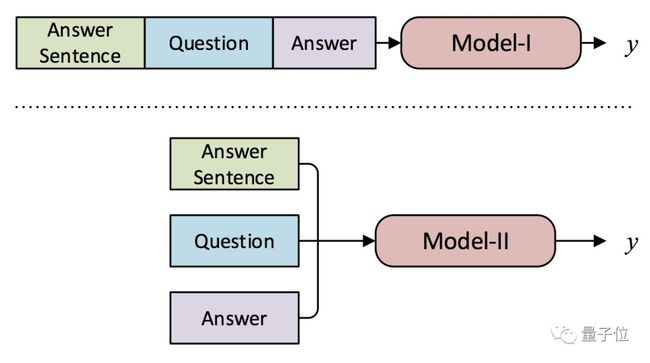
Model-I,是最简单的顺序结构。
Model-II,是交互式结构。由于要识别答案和问题之间的逻辑蕴含,团队使用了基于交互的一种方法,包含这几层:
· 编码 (Encoding)
· 推理建模 (Inference Modelling):建立两个句子之间的交互。
· 句内建模 (Intra-Sentence Modelling) :找出句子内部的逻辑。
· 预测 (Prediction) :给出阶段性的无答案概率。
Model-III,则是把前两个模型整合起来,看预测结果会不会更理想。

其中,Model I用了无监督的预训练,和有监督的微调。也就是说,阅读无标签的文本,来优化模型,初始化参数;然后按照有监督的目标,来调整参数。
Model II是直接用有监督的损失来训练的。
由于两个模型架构不同,需要的训练过程也不同。因此,Model III是用二者的预训练参数来初始化的,然后整体微调。
疗效出众
训练完成,就把AI扔进SQuAD 2.0的隐藏验证集 (下图Test栏) ,试一试。
离人类最近
测试用的阅读器,叫做Reinforced Mnemonic Reader (RMR) ,同样来自Minghao Hu团队,且在SQuAD 1.1榜上有名。

△ 在下愚钝,不确定Verifier用的是Model I、II、III中的哪一个
加上新的验证器,RMR (+ELMo嵌入) 的阅读理解成绩,高过了所有的前辈 (对手都是SQuAD 2.0论文中列出的强者) 。
它的两项分数,都与人类的表现最为接近:
71.7 EM,是精确匹配结果,表示模型给出的答案与标答完全一致。
74.2 F1,是模糊匹配,可理解为部分回答正确,根据模型的答案与标答之间的重合度计算。
登顶SQuAD 2.0排行榜的,就是这组成绩。
三个验证器比一比
击退外敌,再来看一下三个验证器模型,谁的无答案正确率最高。

Model-III,以微弱的优势胜出。由此观之,把Model I、II整合起来,还是有效的。
不过,加上ELMo嵌入,倒是没有带来明显的加成。
欣赏论文吧
“阅读+验证”模型,离人类的阅读理解分数,还有一段距离。
不过,更准确地判断哪些题目不能乱答,也是很大的一步了。

论文传送门:
https://arxiv.org/pdf/1808.05759.pdf
— 完 —
加入社群
量子位AI社群19群开始招募啦,欢迎对AI感兴趣的同学,在量子位公众号(QbitAI)对话界面回复关键字“交流群”,获取入群方式;
此外,量子位专业细分群(自动驾驶、CV、NLP、机器学习等)正在招募,面向正在从事相关领域的工程师及研究人员。
进专业群请在量子位公众号(QbitAI)对话界面回复关键字“专业群”,获取入群方式。(专业群审核较严,敬请谅解)
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态