【论文阅读笔记】Beyond Short Snippets: Deep Networks for Video Classification
-
主要目的:
视频分类
-
测试数据集:
Sports-1M、UCF-101
-
方法概况:
使用在imageNet上预训练过的CNN(AlexNet或者GoogleLeNet)提取帧级特征,再将帧级特征和提取到的光流特征输入到池化框架或者LSTM进行训练,得到分类结果。
-
主要贡献:
1.提出采用CNN来得到视频级的全局描述,并且证明增大帧数能够显著提高分类性能。
2.通过在时序上共享参数,参数的数量在特征聚合和LSTM架构中都作为视频长度的函数保持不变。
3.证明了光流图像能够提升分类性能并用实验结果说明即使在光流图像本身存在大量噪声的情况下(如在Sports-1M数据集中),与LSTM结合后仍然对分类有很大帮助。
-
模型各部件详细介绍:
-
1.特征提取CNN
使用两个CNN的原因:对比哪个框架提取的特征效果好
1)AlexNet
参考文献:A. Krizhevsky, I. Sutskever, and G. E. Hinton. ImageNet classification with deep convolutional neural networks
输入:220X220
卷积层:每个卷积层由size为11X9X5的卷积核组成,每个卷积层后进行最大池化(max-pooling)和归一化(local contrast normalization),最后通过两个size为4096的全连接层(采用ReLu为激活函数),每个全连接层的dropout比率都为0.6
输出:4096X1
2)GoogleLeNet
参考文献:C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich. Going deeper with convolutions
输入:220X220
框架:多个Inception modules,多种卷积核大小,最大池化和平均池化均采用
输出:1000X1
- 2.聚合帧级特征以得到视频级描述(与视频帧时序无关)
采用两种方式,最后将下面两种方式和上述两种CNN分别组合进行效果对比。
优化方式:随机梯度下降(SGD)
参数:学习率10^-5,momentum系数0.9,衰减率0.0005
1)特征池化
共提出了五种池化结构,用于对比,表1是效果对比
(紫色是max-pooling层,C是CNN特征提取输出层,黄色是全连接层,橘色是softmax层,绿色是时域卷积层)
a)Conv Pooling:在视频帧的最终卷积层后使用max_pooling。这种模型的最主要优点是能够通过时域上的最大池化操作来保留卷积层的输出信息。
b)Late Pooling:先将卷积后的特征先后输入到两个全连接层,再对输出进行池化。所有的卷积层和全连接层的参数是共享的。不同于Conv Pooling,这种方法直接池化了更高级别的帧间特征。
c)Slow Pooling:通过较小的时间窗来分层池化帧级的特征,采用两步池化策略:先用max_pooling对10帧特征进行池化,步幅为5(这里的池化也可以看作size为10的卷积核以步幅5对输入的一维特征进行卷积),每个最大池化层后是共享参数的全连接层。第二步是在对所有全连接层的输出进行最大池化。这种方法的特点是在池化帧间高级特征之前对局部时间特征进行组合。
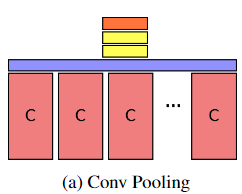


d)Local Pooling:与Slow Pooling相似,这种方法是在最后的卷积层之后对帧级特征分段池化,不同的是只有一个池化阶段。池化后连接两个全连接层,参数共享。最后是将所有输出输入到一个大的softmax层。减少一个池化层,能够避免时序特征的潜在丢失。
e)Time-Domain Convolution:该方法在池化层前增加了一个时域卷积层,该卷积层是由256个3X3的卷积核组成,步幅为5。这种方法通过一个小的时间窗能够捕捉到帧间的局部关系。

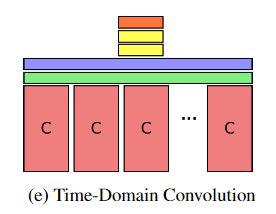
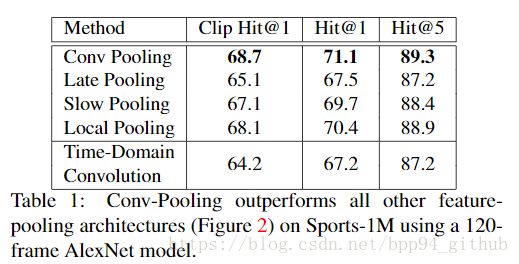
实验证明,第一种池化方式效果最好,第二种最差,指出在池化操作前保留原来的时空信息很重要,第二种方法直接将帧特征输入到全连接层,损失了时空信息,得到高层特征。最后一种方法效果也差,说明时域卷积层的效果不如max-pooling
- 3.使用LSTM以得到视频级描述(与视频帧时序相关)
参考文献:A. Graves, A.-R. Mohamed, and G. E. Hinton. Speech recognition with deep recurrent neural networks
构架:每帧特征后连接五个LSTM层(five layers of stacked LSTMs),后一帧的LSTM输出将输入到下一帧的LSTM,如图所示,最后使用softmax分类器(橙色)
优化方法:随机梯度下降(SGD)
参数:学习率为N(输入视频帧数)X10^-5,并随时间衰减
- 4.光流特征提取
1)融合光流特征和帧特征的方式:
K. Simonyan and A. Zisserman. Two-stream convolutional networks for action recognition in videos
2)光流特征提取方式:
每秒随机抽取连续的15帧,并从中随机抽取两帧进行特征提取
以图的方式存储光流特征,阈值为[-40,40],并将光流的水平(第一维)和垂直(第二维)的部分重新缩放到[0,255]的范围,增加第三维并且将数值设置为0。提取完光流图之后采取和帧图像一样的特征提取方法(CNN)。
C. Zach, T. Pock, and H. Bischof. A duality based approach for realtime tv-l1 optical flow
-
评估指标
Hit@k
参考论文:A. Karpathy, G. Toderici, S. Shetty, T. Leung, R. Sukthankar, and L. Fei-Fei. Large-scale video classification with convolutional neural networks.
-
训练过程
-
1.特征池化
多帧模型准确率高,但同时也需要大量的训练时间。由于提取每帧特征的CNN是一样的,所以单帧和多帧的最大池化网络也是相似的,所以可以采用由单帧模型扩展到多帧模型的方式。max-pooling先被初始化为单帧网络,,然后再扩展到30帧、120帧。虽然在扩展过程中池化层的特征分布会动态改变,然而实验证明传递参数仍然是有作用的。通过这种扩展方法能提高训练速度。
- 2.LSTM
遵循上述池化方式,并做一些修改。首先,每帧都将使用视频标签做反向传播,而不是每个clip做反向传播。该网络在不同时间上的同一层网络参数是共享参数的。其次,在反向传播中使用到参数g,代表增益,g是0…1的线性插值帧t=0...T。g强调了最后一帧预测正确的重要性。对时序中的所有帧设置g=1,或者对最后一帧设置g=1,其它为0,预测效果和训练速度都不如线性插值g。
为了 聚合帧级预测得到视频级预测结果,提出四种方式:
1)使用最后一个时间帧的预测结果为最终视频预测结果;
2)对所有时序帧的预测结果进行最大池化得到最终结果;
3)加和所有帧预测结果,并取最大值;
4)结合g对每帧预测结果进行线性加权,求和并返回最大值。
然而这四种方法的效果只有少于1%的区别,其中加权预测往往会带来最优结果。
-
实验结果
1.Sports-1M
取帧方式:再视频前5分钟抽取300帧(每秒抽取1帧)进行特征提取,若视频不足5分钟就重复视频。在本文的实验中只取120帧(2分钟)对模型进行训练来作为一个简单的例子。
数据增强:将视频帧大小重设置为256X256,然后随机抽取一个220X220的区域,并以50%的概率对帧图像进行水平翻转。虽然数据增强并不是一定要的步骤,但是在条件允许的情况下还是推荐这样做,因为能够提高模型的性能,例如在Sports-1M的Hit@1能够提高3%到5%。
实验结果:CNN对随机抽取的单帧视频预测结果如下表。不同的特征提取方法和特征聚合方法组合的效果也如下图。GoogleLeNet从Hit@1到Hit@5的提升不显著,是因为该数据集相比于预训练使用的ImageNet数据集噪声大

微调:对预训练过的CNN进行微调无法确定是否能使效果变好,通过实验,微调能够提升模型效果。
通过实验证明帧数增加对预测性能有提升:

增加光流特征的效果如下图,可以看见在特征池化模型加入光流特征中没有太大提高,而LSTM加入光流特征后有较大提高,是因为LSTM能将光流特征用于后期特征融合,而特征池化模型却无法做到这样。所以使用光流并不总是有用的,特别是如果视频是从野外拍摄的,就像在 Sports-1M数据集里的情况一样。为了在这种情况下利用光流,有必要使用更复杂的序列处理体系结构,比如LSTM

2.UCF-101
该数据集视频较短,所以可以用更高的帧率抽取视频。下图是以不同帧率抽取视频的对比。由第一行结果推测,相同帧数下,帧率小,意味着送入更长视频,所以准确率会提高,但是再继续降低帧率到1秒1帧,效果就不会提升了。因此,当帧率下降到足以看到整个视频的上下文内容,再降低帧率也不会对结果有提升。

下图是与前人的模型准确率进行比较,所以本文提高了准确率,方法是有效的:
