在EXCEL文档里想从很长的文件路径中取得文件名,【数据】→【分列】是个不错的选择,但用函数会显得更高大上一些。
首先,需要获取最后一个"\"所在的位置。
方法1:
FIND("@",SUBSTITUTE(A1(字符串所在单元格),"\","@",LEN(A1)-LEN(SUBSTITUTE(A1,"\",""))))
这个比较好理解,只要理解了SUBSTITUTE第四个参数的作用就好。
SUBSTITUTE第四个参数:可选。 指定要用 new_text 替换 old_text 的事件。 如果指定了 instance_num,则只有满足要求的 old_text 被替换。 否则,文本中出现的所有 old_text 都会更改为 new_text。
例:

所以,整个函数的意思是把字符串中最后一个"\"替换成字符串中没出现过的其他字符(如“@”),然后在查找这个没出现过的字符所在的位置就可以了。

方法2:
LOOKUP(1,0/(MID(A1(字符串所在单元格),COLUMN(1:1),1)="\"),COLUMN(1:1))
这个理解起来比较难。
先来理解COLUMN(1:1)的意思:
在空白EXCEL文档里选中第一行,在编辑栏里输入=COLUMN(1:1),再按Ctrl+Shift+Enter组合键

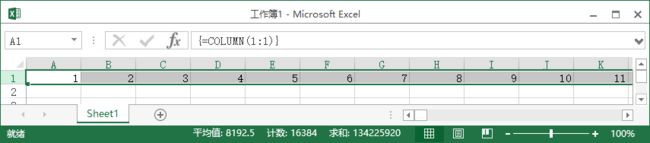
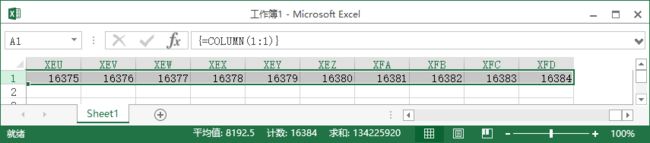
可以看到COLUMN(1:1)的结果是一个1~16384的数组。
再看(MID(A1(字符串所在单元格),COLUMN(1:1),1)="\"),作用是一个个取出字符串中的字符,并判断是否与"\"相同,相同则返回TRUE,否则返回FALSE。
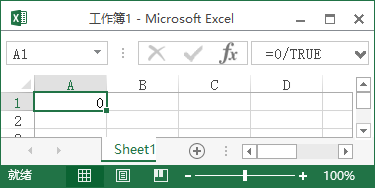
0/TRUE得0,0/FALSE得![]()

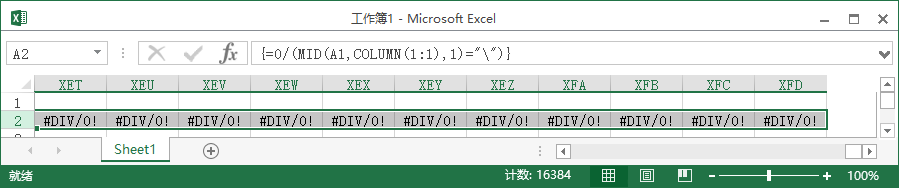
所以0/(MID(A1(字符串所在单元格),COLUMN(1:1),1)="\")的结果是

所以LOOKUP(1,0/(MID(A1(字符串所在单元格),COLUMN(1:1),1)="\"),COLUMN(1:1))的结果是

EXCEL帮助里的备注:

本例中的LOOKUP函数在0/(MID(A1(字符串所在单元格),COLUMN(1:1),1)="\")里是找不到1的,所以它找到的是0,但在0/(MID(A1(字符串所在单元格),COLUMN(1:1),1)="\")里有多个0,从结果来看,它找到的是最后一个0。(为什么?在EXCEL帮助里没有找到相关说明)
声明:本文是本人查阅网上及书籍等各种资料,再加上自己的实际测试总结而来,仅供学习交流用,请勿使用于商业用途,任何由此产生的法律版权问题概不负责,谢谢。