C/C++ openMP并发编程 (学习整理)
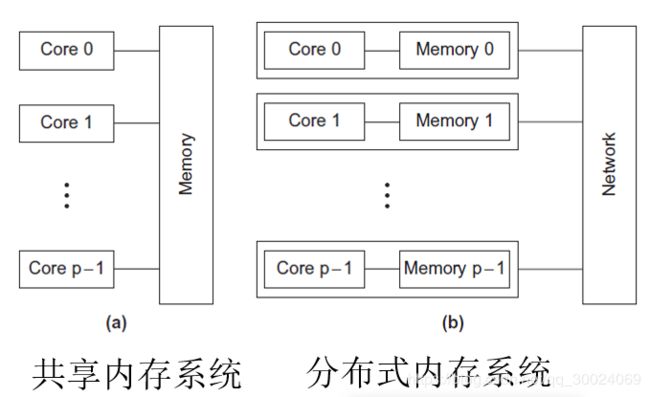
并发系统分为两种:
- 共享内存系统:各个核可以共享访问计算机的内存。
- 分布式内存系统:每个核都有自己独立私有的内存,核之间的通信需要通过网络发送消息。
OpenMP是一种用于共享内存系统的多线程程序设计方案,支持C,C++,Fortran编程语言。OpenMP提供了对并行算法的高层抽象,特别适合多核计算机上道德并行编程设计。当前很多编译器都内置了OpenMP,当编译器不支持OpenMP时,编译器会忽视OpenMP指令,程序自动退化为串行程序,不影响程序的正常编译。特别需要强调一点:在VS编译器中,只有在Release模式下才能体现OpenMP并行化,Debug模式下编译器不会对代码进行优化。
OpenMP采用fork-join(分叉-合并)并行执行模式。线程遇到并行结构时,就会创建由其自身及其它一些线程组成的线程组。遇到并行结构的线程称为线程组中的主线程,其它线程称为组的从线程。所有线程组的成员都执行并行构造内的代码。如果某个线程完成了其在并行构造内的工作,它会在并行构造末尾的隐式屏蔽处等待。当所有组成员都达到该屏蔽处,这些线程就可以离开该屏障。主线程继续执行并行结构之后的代码,而从线程则等待被召集加入到其他组。
OpenMP运行时库维护一个线程池,该线程池的线程可以用作并行区域中的从线程。当线程遇到并行结构并需要创建包含多个线程的线程组时,该线程将检查该池,从池中获取空闲线程,将其作为组的从线程。如何池中没有足够的空闲线程,则主线程获取的从线程可能会比所需的要少。组完成执行并行区域时,从线程就会返回到池中。
上面对OpenMP有一个整体的认识,下面按照OpenMP10.0开发文档的结构,对OpenMP中关键点进行整理介绍:
目录
PARALLEL-并行区域构造
工作共享构造
合并并行工作共享构造
同步构造
数据作用域
调度子句
PARALLEL-并行区域构造
parallel指令定义并行区域,该区域多个线程以并行方式执行的程序区域。默认并行线程数为电脑的核数目,下面代码我的电脑输出12个语句。
#pragma omp parallel //C,C++使用以#pragma omp开头的标准预处理指令
{
cout << "parallel run!!!\n";
}输出:parallel run!!!;parallel run!!!;parallel run!!!;parallel run!!!.....................................
工作共享构造
工作共享构造在遇到该结构的线程组成员中分配封装代码区域的执行。要使工作共享构造以并行方式执行,构造必须封装在并行区域内。
1.for构造
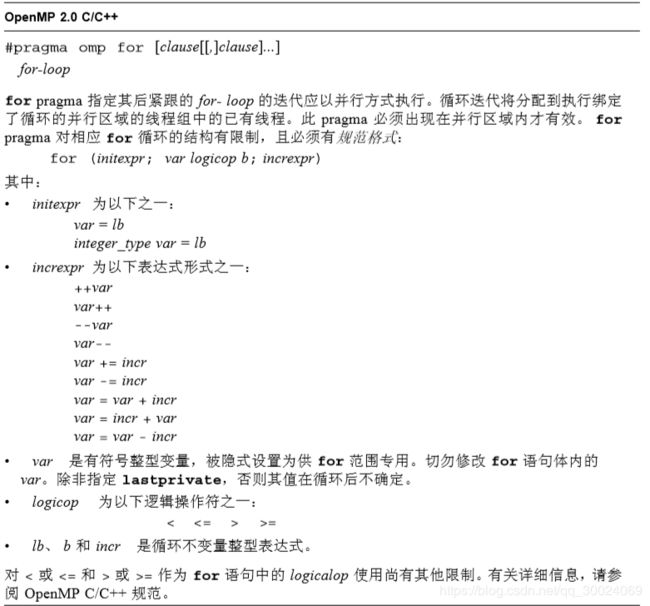
#pragma omp parallel
#pragma omp for
for (int i = 0; i < 10; i++)
{
cout << i << endl;
}注意:一定要在#pragma omp for指令前加入#pragma omp parallel指令,不然退化为串行执行
2.sections构造
sections构造用于封装要在线程组中分配的一组结构化代码块,每个代码块由线程组内的一个线程执行一次。每段以section指令开头,该指令对第一段为可选指令。
#pragma omp parallel
#pragma omp sections
{
#pragma omp section //此处可选字段,可以不加
cout << "work1" << endl;
#pragma omp section //此处必选字段,不加此字段报错OpenMP“sections”区域中的结构化块的前面必须是“#pragma omp section”
cout << "work2" << endl;
#pragma omp section //此处必选字段
cout << "work3" << endl;
}输出:work1,work2,work3(顺序不一定,但是只执行一次)
3.single构造
single封装的结构化块只由线程组中的一个线程来执行,除非指定nowait,否则组内未执行single块的线程会在块结尾处等待。
#pragma omp parallel
#pragma omp single
{
cout<<"work1"<4.task构造
task是3.0及以上OpenMP标准实现,task主要用于方便实现任务分解。可能被遇到的线程马上执行,也可能被延迟给线程组内的某个线程执行。task构造必须在并行区域内,并且task外面使用single子句,防止任务执行多次。如果想线程等待其他线程等待完成任务,则添加#pragma omp taskwait。task指令共享变量默认是firstprivate方式共享。
task主要用于不规则的循环迭代和递归函数的调用,for指令,sections指令:无法根据运行时的环境动态的进行任务划分,必须预先知道任务的划分情况。新特性task指令基础
#pragma omp parallel
#pragma omp single
{
for (int i = 0; i < 10; i = i + a[i])
{
#pragma omp task
task(a[i]);
}
}合并并行工作共享构造
parallel for构造
parallel for构造等价于parallel指令后紧跟for指令
#pragma omp parallel
#pragma omp for
#pragma omp parallel forparallel sections构造
parallel sections构造等价于parallel指令后紧跟sections指令
#pragma omp parallel
#pragma omp sections
#pragma omp parallel sections
同步构造
同步构造用于指定线程同步。
1.MASTER构造
只有线程组的主线程才执行此指令所封装的块,其他线程会跳过此块,然后继续执行。主构造的入口或出口处无暗含障碍。
#pragma omp parallel
#pragma omp master
{
cout<<"work1"<2.critical构造
每次限制一个线程可访问结构化块,实现每次只有一个线程进入临界区,实现线程间互斥。critical可以比atomic处理更复杂的原子性。
#pragma omp parallel
#pragma omp critical
{
cout<<"work1"<3.barrier构造
线程组内的所有线程,每个线程都等到组内其他线程都到达此点为止。组内的所有线程都到障碍后,组内的每个线程便开始执行barrier指令后的语句。在for,sections指令中默认在末尾添加隐形障碍。
#pragma omp parallel
{
...................
#pragma omp critical
....................
}4.atomic构造
atomic构造保证其紧随其后的语句是原子操作,如果多线程同时执行sum+=i,atomic可以保证sum最终拥有正确的值。
sum=0;
#pragma omp parallel for
for(int i=0;i<100;i++)
{
#pragma omp atomic
sum+=i;
}atomic只能用于简单的表达式,它们通常可以被编译成一条指令。如果上面改为sum=sum+i,则无法通过编译。

5.flush构造
对于多线程之间的共享变量,编译器可能将它们设为寄存器变量,每个线程都拥有变量的副本,导致变量并没有在多个线程之间共享。为了保证共享变量在线程之间真实共享,保证每个线程看到的值是一致的,使用flush指令告诉编译器需要哪些共享变量。当在多个线程中读写共享变量时,应该使用flush变量。
bool flag=flase;
#pragma omp parallel for
{
#pragma omp flush(flag)
if(flag)
{}
}6.ordered构造
封装的块按照迭代在循环的顺序执行中的执行顺序执行。#pragma omp ordered之前的代码并发执行,cout处必须等待,只有输出第i-1之后,输出第i的线程才可以继续执行。
#pragma omp parallel for ordered
for (int i = 0; i < 10; i++)
{
..............
#pragma omp ordered
cout << i << "\t";
}输出结果:0,1,2,3,....9
数据作用域
如果未给指令指定数据作用域子句,则受指令影响的变量的缺省作用域为shared.
1.shared子句
组内所有线程都共享shared指定的变量,并访问同一存储区域。
2.private子句
将private指定的变量声明为线程的私有变量,每个线程存有该变量的副本,其他线程不可访问。注意:线程只是创建了同名变量,但是并未进行初始化。并且对并行区域外的变量没有影响。for构造中的循环变量以及for内局部变量都属于private。下面代码运行错误。
int sum = 0;
int k=4;
#pragma omp parallel for private(k)
for (int i = 0; i<10; i++)
{
sum += k;
}
//error C4700: 使用了未初始化的局部变量“k” 3.firstprivate子句
声明变量为private,并且此变量的副本是拷贝先前已经存在的对象中初始化得到。如果变量是自定义类对象,则该类应该定义拷贝构造函数。原始对象的值并不会改变
int sum = 0;
int k=4;
#pragma omp paralle for firstprivate(k)
for (int i = 0; i<10; i++)
{
k++;
}
cout<4.lastprivate子句
声明变量为private。lastprivate子句在for指令中出现时,执行序列末位的最后一个迭代线程会更新原始对象。在sections指令中,执行按照顺序位于最后的section线程更新原始对象
int k = 4;
#pragma omp parallel for firstprivate(k) lastprivate(k)
for (int i = 0; i<10; i++)
{
k++;
cout << this_thread::get_id() << endl;
}
cout << k << endl;//55.default子句
指定并行区域内所有变量的作用域属性。未指定时使用default(shared),可以使用private,firstprivate,lastprivate,shared,reduction子句覆盖变量的缺省数据共享属性。使用default(none),则需要显示设置共享变量的作用域。下面代码运行错误,变量a没有显示设置作用域属性。
int a = 0, b = 0;
#pragma omp parallel default(none) shared(b)
{
b += a;
}
//error C3052: “a”: 变量没有出现在 default(none)子句下的 data-sharing 子句中
7.reduction子句
reduction(operator:list)
oprator必须为以下操作符之一:+,-,*,&,……,|,&&,||
list中的变量在封装上下文中必须为shared,为每个线程创建每个变量的专用副本,在约简尾部将原始值与每个专用副本的最终值按照操作符进行合并来更新共享变量。下面代码正确输出结果,避免了多线程访问同以地址空间。
int sum=4;
#pragma omp parallel for reduction(+:sum)
for (int i = 0; i < 10; i++)
sum = sum + i;
cout << sum << endl;调度子句
schedule子句指定C/C++for 循环中的迭代如何在组中线程间分配的。
1.static调度
#pragma omp parallel for schedule(static,4)
for(int i=0;i<10;i++)
cout<迭代被分为由chunk指定大小的块。这些块按线程号顺序,以循环方式静态地分配给组中地线程。未指定时系统会选择chunk,迭代会被划分为大小近似相同的连续块,每个线程分配一块。
2.dynamic调度
#pragma omp parallel for schedule(dynamic,4)
for(int i=0;i<10;i++)
cout<迭代被分为由chunk指定大小的块,并分配给等待的线程。每个线程都完成其迭代空间块时,会动态获取下一组迭代。未指定chunk时,缺省值为1.
3.guided调度
#pragma omp parallel for schedule(guided,2)
for(int i=0;i<10;i++)
cout<使用guided时,每分发一个迭代块,块大小便以指数方式递减一次。chunk指定每次分发的最小迭代数。未指定chunk时,缺省值为2.0.
1.交替打印奇偶数
#include
#include
#include
using namespace std;
int main()
{
int n = 100;
#pragma omp parallel for num_threads(2) ordered schedule(static,2)
for (int i = 1; i < n; i++)
{
#pragma omp ordered
cout <