zookeeper集群、solr集群、Redis集群的一些概念
1. zookeeper集群
zookeeper集群比较简单,重要的是理解其中有一个选举机制,官方建议配置节点数奇数个,因为因eader的选举机制要超过半数
且与启动顺序有关,比如,现在存在5个节点,启动顺序为1、2、3、4、5
当1启动时,集群并未真的启动,因为没有leader、
当2启动时,会进行投票选举leader,因为2后来的所以2为leader,1为follower
当3启动时,大家肯定回想谁是leader,结果是2是leader,为什么呢?因为这时候虽然3是后来的但是leader已经产生,除非挂掉
否则不会重选,以下同理
场景:3个节点,2为leader
当1挂掉,集群依然正常运行,因为现在还可以超过半数,2依然为leader
当2挂掉,leader会重新选举
当三个中挂掉2个,则集群就挂了,因为没能超过半数,无法选取leader
2.solr集群
搭建过程比较zookeeper较为麻烦,总结一下遇到的需要注意的点,比如说分片,主从
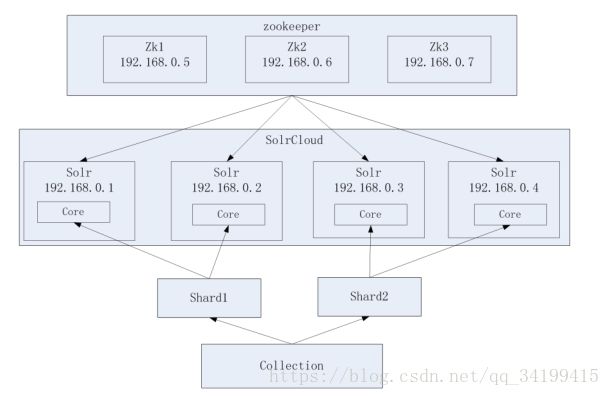
分片-主从:其实一种物理结构,若存在四个物理机器分别安装了solr,且每个solr中只有一个core,如上图,将四台机器分成逻辑上的两片,一起组成一个完整的逻辑结构,一个solr集群,两个分片存储的内容不同,而分片中的两个solr则为一主一备,存储的数据相同,谁为主是由solr决定,我们可以指定有多少个备机器,还可以指定有多少个分片。
solr中不存在选举的机制
solr的索引数据存放在磁盘,有一定的规则,不像Redis数据常驻内存
solr集群需要配合zookeeper实现统一配置文件管理,可以把zookeeper看作管理者,就像zookeeper集群中的Leader
场景:如上图
若shard1中一个节点挂掉,则另一个节点仍在正常工作,整个集群正常
若shard1中两个节点都挂掉,则集群挂掉,以下同理
3.Redis集群
Redis集群很不一样的一个点在于它是无中心的架构,每个节点保存数据和整个集群状态,每个节点都和其他所有节点连接,
客户端不需要连接集群所有节点连接集群中任何一个可用节点即可,所有的 redis 节点彼此互联(PING-PONG 机制),发送一个请求如果对方没有回应则判定节点挂掉

还有很重要的一个概念是槽的概念,Redis 集群中内置了 16384 个哈希槽,当需要在 Redis 集群中放置一个 key-value 时,redis 先对 key 使用 crc16 算法算出一个结果,然后把结果对 16384 求余数,这样每个key 都会对应一个编号在 0-16383 之间的哈希槽,redis 会根据节点数量大致均等的将哈希槽映射到不同的节点。
场景:三个节点(每个节点5461):槽分布的值如下
SERVER1: 0-5460
SERVER2: 5461-10922
SERVER3: 10923-16383
若现在存入一个key-value,使用 crc16 算法算出一个结果,然后把结果对 16384 求余数,得出的结果在那个Server的槽范围内,数据就放在哪里
另一个重要的地方在于节点主从备份,在说主从备份之前要提到Redis的容错机制(投票),)选举过程是集群中所有master参与,如果半数以上master节点与故障节点通信超过(cluster-node-timeout),认为该节点故障,自动触发故障转移操作. 故障节点对应的从节点自动升级为主节点,这里的的投票不同于上面的zookeeper,这是要把挂掉的节点踢出去,让备份节点进来
在搭建集群的过程中要使用Ruby连接集群
./redis-trib.rb create --replicas 1 192.168.25.140:6379 192.168.25.141:6379 192.168.25.142:6379
192.168.25.143:6379 192.168.25.144:6379 192.168.25.145:6379
一共有6个节点,--replicas 1表示每一个节点都有一个从节点,从节点不会分配槽,主节点有,当主节点挂掉后,从节点才会有槽,从节点会自动Copy主节点中的内容