Paper:论文解读《Adaptive Gradient Methods With Dynamic Bound Of Learning Rate》中国本科生提出AdaBound的神经网络优化算法
Paper:论文解读—《Adaptive Gradient Methods With Dynamic Bound Of Learning Rate》中国本科生(学霸)提出AdaBound的神经网络优化算法
目录
亮点总结
论文解读
实验结果
1、FEEDFORWARD NEURAL NETWORK
2、CONVOLUTIONAL NEURAL NETWORK
3、RECURRENT NEURAL NETWORK
实验结果分析
《Adaptive Gradient Methods With Dynamic Bound Of Learning Rate》
论文页面:https://openreview.net/pdf?id=Bkg3g2R9FX
评审页面:https://openreview.net/forum?id=Bkg3g2R9FX
GitHub地址:https://github.com/Luolc/AdaBound
亮点总结
1、AdaBound算法的初始化速度快。
2、AdaBound算法对超参数不是很敏感,省去了大量调参的时间。
3、适合应用在CV、NLP领域,可以用来开发解决各种流行任务的深度学习模型。
We investigate existing adaptive algorithms and find that extremely large or small learning rates can result in the poor convergence behavior. A rigorous proof of non-convergence for ADAM is provided to demonstrate the above problem.
Motivated by the strong generalization ability of SGD, we design a strategy to constrain the learn- ing rates of ADAM and AMSGRAD to avoid a violent oscillation. Our proposed algorithms, AD- ABOUND and AMSBOUND, which employ dynamic bounds on their learning rates, achieve a smooth transition to SGD. They show the great efficacy on several standard benchmarks while maintaining advantageous properties of adaptive methods such as rapid initial progress and hyper- parameter insensitivity.
我们研究了现有的自适应算法,发现极大或极小的学习率都会导致较差的收敛行为。为证明上述问题,ADAM给出了非收敛性的严格证明。
基于SGD较强的泛化能力,我们设计了一种策略来约束ADAM和AMSGRAD的学习速率,以避免剧烈的振荡。我们提出的算法,ADABOUND和AMSBOUND,采用了动态的学习速率边界,实现了向SGD的平稳过渡。它们在保持自适应方法初始化速度快、超参数不敏感等优点的同时,在多个标准基准上显示了良好的效果。
论文解读

自适应优化方法,如ADAGRAD, RMSPROP和ADAM已经被提出,以实现一个基于学习速率的元素级缩放项的快速训练过程。虽然它们普遍存在,但与SGD相比,它们的泛化能力较差,甚至由于不稳定和极端的学习速率而无法收敛。最近的研究提出了AMSGRAD等算法来解决这一问题,但相对于现有的方法没有取得很大的改进。在我们的论文中,我们证明了极端的学习率会导致糟糕的表现。我们提供了ADAM和AMSGRAD的新变体,分别称为ADABOUND和AMSBOUND,它们利用学习速率的动态边界来实现从自适应方法到SGD的渐进平稳过渡,并给出收敛性的理论证明。我们进一步对各种流行的任务和模型进行实验,这在以往的工作中往往是不够的。实验结果表明,新的变异可以消除自适应方法与SGD的泛化差距,同时在训练早期保持较高的学习速度。此外,它们可以对原型带来显著的改进,特别是在复杂的深度网络上。该算法的实现可以在https://github.com/Luolc/AdaBound找到。
实验结果
In this section, we turn to an empirical study of different models to compare new variants with popular optimization methods including SGD(M), ADAGRAD, ADAM, and AMSGRAD. We focus on three tasks: the MNIST image classification task (Lecun et al., 1998), the CIFAR-10 image classification task (Krizhevsky & Hinton, 2009), and the language modeling task on Penn Treebank (Marcus et al., 1993). We choose them due to their broad importance and availability of their architectures for reproducibility. The setup for each task is detailed in Table 2. We run each experiment three times with the specified initialization method from random starting points. A fixed budget on the number of epochs is assigned for training and the decay strategy is introduced in following parts. We choose the settings that achieve the lowest training loss at the end.
在这一节中,我们将对不同的模型进行实证研究,将新变量与常用的优化方法(包括SGD(M)、ADAGRAD、ADAM和AMSGRAD))进行比较。我们主要关注三个任务:MNIST图像分类任务(Lecun et al.,1998)、CIFAR-10图像分类任务(Krizhevsky & Hinton, 2009)和Penn Treebank上的语言建模任务(Marcus et al.1993)。我们之所以选择它们,是因为它们的架构具有广泛的重要性和可再现性。表2详细列出了每个任务的设置。我们使用指定的初始化方法从随机的起点运行每个实验三次。为训练指定了固定的时域数预算,下面将介绍衰减策略。我们选择的设置,实现最低的训练损失在最后。

1、FEEDFORWARD NEURAL NETWORK
We train a simple fully connected neural network with one hidden layer for the multiclass classification problem on MNIST dataset. We run 100 epochs and omit the decay scheme for this experiment.
Figure 2 shows the learning curve for each optimization method on both the training and test set. We find that for training, all algorithms can achieve the accuracy approaching 100%. For the test part, SGD performs slightly better than adaptive methods ADAM and AMSGRAD. Our two proposed methods, ADABOUND and AMSBOUND, display slight improvement, but compared with their prototypes there are still visible increases in test accuracy.
针对MNIST数据集上的多类分类问题,我们训练了一个具有隐层的简单全连通神经网络。我们运行了100个epochs,省略了这个实验的衰变方案。
图2显示了训练和测试集上每种优化方法的学习曲线。我们发现在训练中,所有算法都能达到接近100%的准确率。在测试部分,SGD的性能略优于ADAM和AMSGRAD的自适应方法。我们提出的 ADABOUND和AMSBOUND两种方法显示出轻微的改进,但与它们的原型相比,测试精度仍然有明显的提高。

2、CONVOLUTIONAL NEURAL NETWORK
Using DenseNet-121 (Huang et al., 2017) and ResNet-34 (He et al., 2016), we then consider the task of image classification on the standard CIFAR-10 dataset. In this experiment, we employ the fixed budget of 200 epochs and reduce the learning rates by 10 after 150 epochs.
DenseNet :We first run a DenseNet-121 model on CIFAR-10 and our results are shown in Figure 3. We can see that adaptive methods such as ADAGRAD, ADAM and AMSGRAD appear to perform better than the non-adaptive ones early in training. But by epoch 150 when the learning rates are decayed, SGDM begins to outperform those adaptive methods. As for our methods, ADABOUND and AMSBOUND, they converge as fast as adaptive ones and achieve a bit higher accuracy than SGDM on the test set at the end of training. In addition, compared with their prototypes, their performances are enhanced evidently with approximately 2% improvement in the test accuracy.
ResNet :Results for this experiment are reported in Figure 3. As is expected, the overall performance of each algorithm on ResNet-34 is similar to that on DenseNet-121. ADABOUND and AMSBOUND even surpass SGDM by 1%. Despite the relative bad generalization ability of adaptive methods, our proposed methods overcome this drawback by allocating bounds for their learning rates and obtain almost the best accuracy on the test set for both DenseNet and ResNet on CIFAR-10.
然后利用DenseNet-121 (Huang et al.2017)和ResNet-34 (He et al.2016)对CIFAR-10标准数据集进行图像分类。在这个实验中,我们使用200个epoch的固定预算,在150个epoch后将学习率降低10个。
DenseNet:我们首先在CIFAR-10上运行DenseNet-121模型,结果如图3所示。我们可以看到,ADAGRAD、ADAM和AMSGRAD等自适应方法在早期训练中表现得比非自适应方法更好。但是到了历元150,当学习速率衰减时,SGDM开始优于那些自适应方法。对于我们的方法ADABOUND和AMSBOUND,它们收敛速度和自适应方法一样快,并且在训练结束时的测试集上达到比SGDM稍高的精度。此外,与原型机相比,其性能得到了显著提高,测试精度提高了约2%。
ResNet:实验结果如图3所示。正如预期的那样,ResNet-34上的每个算法的总体性能与DenseNet-121上的相似。ADABOUND和AMSBOUND甚至超过SGDM 1%。尽管自适应方法的泛化能力相对较差,但我们提出的方法克服了这一缺点,为其学习速率分配了界限,在CIFAR-10上对DenseNet和ResNet的测试集都获得了几乎最佳的准确率。
3、RECURRENT NEURAL NETWORK
Finally, we conduct an experiment on the language modeling task with Long Short-Term Memory (LSTM) network (Hochreiter & Schmidhuber, 1997). From two experiments above, we observe that our methods show much more improvement in deep convolutional neural networks than in perceptrons. Therefore, we suppose that the enhancement is related to the complexity of the architecture and run three models with (L1) 1-layer, (L2) 2-layer and (L3) 3-layer LSTM respectively. We train them on Penn Treebank, running for a fixed budget of 200 epochs. We use perplexity as the metric to evaluate the performance and report results in Figure 4.

We find that in all models, ADAM has the fastest initial progress but stagnates in worse performance than SGD and our methods. Different from phenomena in previous experiments on the image classification tasks, ADABOUND and AMSBOUND does not display rapid speed at the early training stage but the curves are smoother than that of SGD.
我们发现,在所有模型中,ADAM的初始进展最快,但在性能上停滞不前,不如SGD和我们的方法。与以往在图像分类任务实验中出现的现象不同,ADABOUND和AMSBOUND在训练初期的速度并不快,但曲线比SGD平滑。
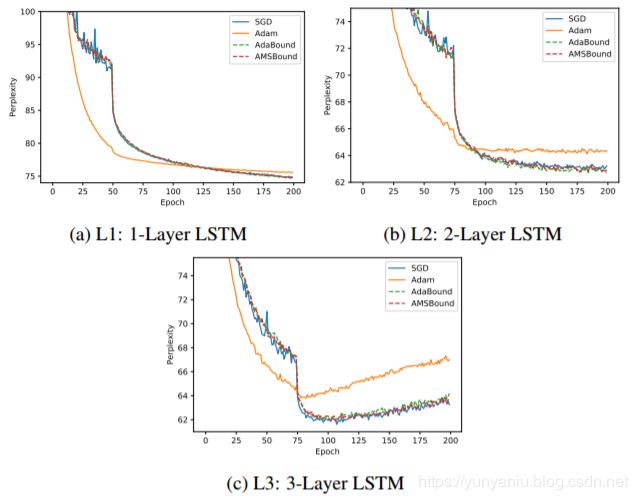
Comparing L1, L2 and L3, we can easily notice a distinct difference of the improvement degree. In L1, the simplest model, our methods perform slightly 1.1% better than ADAM while in L3, the most complex model, they show evident improvement over 2.8% in terms of perplexity. It serves as evidence for the relationship between the model’s complexity and the improvement degree.
对比L1、L2和L3,我们可以很容易地发现改善程度的显著差异。在最简单的模型L1中,我们的方法比ADAM的方法略好1.1%,而在最复杂的模型L3中,我们的方法在复杂的方面明显优于2.8%。为模型的复杂性与改进程度之间的关系提供了依据。
实验结果分析
To investigate the efficacy of our proposed algorithms, we select popular tasks from computer vision and natural language processing. Based on results shown above, it is easy to find that ADAM and AMSGRAD usually perform similarly and the latter does not show much improvement for most cases. Their variants, ADABOUND and AMSBOUND, on the other hand, demonstrate a fast speed of convergence compared with SGD while they also exceed two original methods greatly with respect to test accuracy at the end of training. This phenomenon exactly confirms our view mentioned in Section 3 that both large and small learning rates can influence the convergence.
Besides, we implement our experiments on models with different complexities, consisting of a per- ceptron, two deep convolutional neural networks and a recurrent neural network. The perceptron used on the MNIST is the simplest and our methods perform slightly better than others. As for DenseNet and ResNet, obvious increases in test accuracy can be observed. We attribute this differ- ence to the complexity of the model. Specifically, for deep CNN models, convolutional and fully connected layers play different parts in the task. Also, different convolutional layers are likely to be responsible for different roles (Lee et al., 2009), which may lead to a distinct variation of gradients of parameters. In other words, extreme learning rates (huge or tiny) may appear more frequently in complex models such as ResNet. As our algorithms are proposed to avoid them, the greater enhance- ment of performance in complex architectures can be explained intuitively. The higher improvement degree on LSTM with more layers on language modeling task also consists with the above analysis.
为了研究我们提出的算法的有效性,我们从计算机视觉和自然语言处理中选择流行的任务。根据上面显示的结果,不难发现ADAM和AMSGRAD的表现通常是相似的,而AMSGRAD在大多数情况下并没有太大的改善。另一方面,它们的变体ADABOUND和AMSBOUND与SGD相比具有较快的收敛速度,同时在训练结束时的测试精度也大大超过了两种原始方法。这一现象正好印证了我们在第3节中提到的观点,学习速率的大小都会影响收敛。
此外,我们还对不同复杂度的模型进行了实验,包括一个per- ceptron模型、两个深度卷积神经网络模型和一个递归神经网络模型。MNIST上使用的感知器是最简单的,我们的方法比其他方法稍好一些。DenseNet和ResNet的测试精度明显提高。我们把这种不同归因于模型的复杂性。具体来说,对于深度CNN模型,卷积层和全连通层在任务中扮演不同的角色。此外,不同的卷积层可能负责不同的角色(Lee et al.2009),这可能导致参数梯度的明显变化。换句话说,极端的学习速率(巨大或微小)可能在ResNet等复杂模型中出现得更频繁。由于我们的算法是为了避免这些问题而提出的,因此可以直观地解释在复杂体系结构中性能的提高。LSTM在语言建模任务上的层次越多,改进程度越高,也与上述分析一致。
PS:因为时间比较紧,博主翻译的不是特别尽善尽美,如有错误,请指出,谢谢!