数据仓库----Hive进阶篇 一
[数据仓库----hive进阶篇二(表的链接,子查询,客户端jdbc和Thrift Client操作,自定义函数)](http://blog.csdn.net/s646575997/article/details/51471000)
一、数据的导入
1、使用Load语句执行数据的导入
1.语法:

其中(中括号中表示可加指令):
LOCAL:表示指定的文件路径是否是本地的,没有则说明是HDFS上的文件路径。
OVERWRITE:表示覆盖表中的已有数据。
PARTITION ():如果是向分区表中导入数据的话需要指定分区。
2.实例:
(1).无分区情况:
![]()
其中的'/root/data'可以是路径也可以是文件:
路径表示把该路径下的所有文件都导入到表中;
文件表示只把当前文件导入到表中。
(2).有分区情况:
![]()
2、使用Sqoop进行数据的导入
1.使用sqoop将mysql数据库中的数据导入到HDFS中
hive> sqoop import --connect jdbc:mysql://localhost/3306/sfd --username root --password 123 --table student --columns 'sid,sname' -m 1 --target-dir '/sqoop/student' 其中:
--connet :表示数据库的url链接
--username :数据库用户名
--password :数据库用户密码
--table :源数据所在的表
--clomns : 表中的列名,(例子中使用',' 链接)
-m 1 : 表示启用的mapreduce个数为1个
--target-dir : 将源数据导入到HDFS上的那个文件夹下
2.使用sqoop将mysql数据库中的数据导入到hive中:
hive> sqoop import --hive-import --connect jdbc:mysql://localhost/3306/sfd --username root --password 123 --table student --columns 'sid,sname' -m 1 --hive-table stu --where 'sid=1' 其中:
--hive-table stu : 表示在导入到hive中名为stu的表中
--where :表示插入数据的条件
3.使用sqoop将mysql数据库中的数据导入到hive中,并使用查询语句;
hive> sqoop import --hive-import --connect jdbc:mysql://localhost/3306/sfd --username root --password 123 -m 1 --query 'select * from student where sid='1' and $CONDITIONS' --target-dir '/sqoop/student1' --hive-table stu 其中:
--query : 表示使用的查询语句,如果查询语句中有where条件限制那么必须加上 and $CONDITIONS(大写)
4.使用sqoop将hive中的数据导出到mysql中:
hive> sqoop export --connect jdbc:mysql://localhost/3306/sfd --username root --password 123 -m 1 --table student1 --export-dir '/data' 其中:
--table :为mysql数据库中的已经建立了的表
--export-dir :将数据这个文件夹下的数据导入到mysql的student1表中。
5.使用sqoop将mysql中的数据导入到hbase中
sqoop import --connect jdbc:mysql://10.10.97.116:3306/rsearch --table researchers --hbase-table A --column-family person --hbase-row-key id --hbase-create-table --username 'root' -P
其中:
--connect jdbc:mysql://10.10.97.116:3306/rsearch 表示远程或者本地 Mysql 服务的URI,
3306是Mysql默认监听端口,rsearch是数据库,若是其他数据库,如Oracle,只需修改URI即可。
--table researchers 表示导出rsearch数据库的researchers表。
--hbase-table A 表示在HBase中建立表A。
--column-family person 表示在表A中建立列族person。
--hbase-row-key id 表示表A的row-key是researchers表的id字段。
--hbase-create-table 表示在HBase中建立表。
--username 'root' 表示使用用户root连接Mysql。
二、Hive的数据查询
1、 查询的语法:

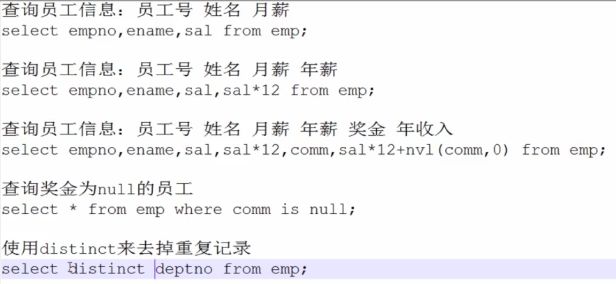
例子:查询student表中的信息:
select * from student;(查询所有信息不用启用mapreduce)
select sid from student;(需要启动mapreduce)
select sid,sname,math,english,math+english from student;(在(math+english)表达式中如果有一个变量为空那么整个表达式为空,可以使用nvl(math,0)函数,表示如果math为空令其为0)
2、简单查询的Fetch Task功能,
从上面的例子中可以看出,简单的查询如果不是查询所有的信息,就会开启mapreduce任务,这样会影响工作效率,从Hive0.10.0版本开始支持了Fetch Task功能;
Fetch Task功能配置方式:
a. 方式一: set hive.fetch.task.conversion=more
b. 方式二: hive --hiveconf hive.fetch.task.conversion=more
c. 方式三: 修改hive-site.xml文件

前两种方式只在当前hive命令行有用,当重启hive时简单查询还是会调用mapreduce程序;而第二种方式配置是一直起作用的。
3.、在查询中使用过滤
1.where 语句进行过滤。(字符串过滤区分大小写)

其中:%\\_% : 由于_是模糊查询中的关键词(表示有一个字符),所以要用到转义字符,第一个'\'表示后面使用的是转义字符,'\_'表示的是'_';
4、在查询中排序
排序默认是升序的,要想降序只需在末尾加上desc

注意:当使用序号进行排序的使用需要设置一个属性:set hive.groupby.orderby.position.alias=true;
三、Hive的内置函数
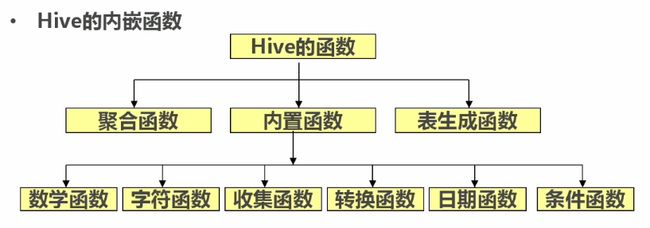
1、数学函数:
round(45.926,2):四舍五入(第二个参数表示的是保留小数点后面几位,当参数为负数是表示的是小数点前)

ceil(45.9):向上取整
floor(45.9):向下取整
2、字符函数:
lower:把字符串转换成小写
upper:把字符串装换成大写
length:字符串的长度
concat('hello','world'):添加一个字符串
substr(a,b):截取字符串:(从a中,第b为开始取,取到右边所有的字符)
substr(a,b,c):截取字符串:(从a中,第b为开始取,取c个字符)
trim:去掉字符串两端的空格
lpad('abc',10,'*'):左填充
rpad:右填充
3、收集函数和转换函数:
1,收集函数:
size:
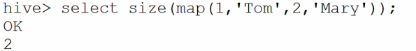
2,转换函数:
cast:cast(1 as bigint);
4、日期函数:
to_data:取出字符串中的日期部分

year:取出日期中的年
month:取出日期中的月
day:取出日期中的日
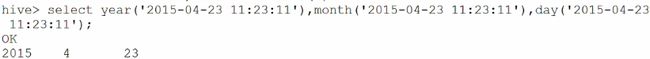
weekofyear:返回一个日期在一年中是第几个星期

datediff:两个日期相减返回相差的天数
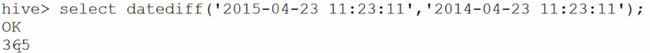
date_add:在一个日期上加上多少天
date_sub:在一个日期上减去多少天
![]()
5、条件函数:
coalesce(a,b,...):从做到右返回第一个不为null的值
![]()
case...when...: 条件表达式
case a when b then c [when d then e]* [else f] end

6、聚合函数:
count:个数
sum:求和
min:求最小值
max:求最大值
avg:求平均值
7、表生成函数:
explode:把一个map集合或者是array数组中的一个元素单独生成一行
![]()

数据仓库—-hive进阶篇二