【ios 网络篇 1】 协议设计
一.概念
这里说的协议是什么?
在两个计算端点之间建立或控制连接、通信或数据传输的约定或标准
协议设计解决的问题是?
1) 序列化/反序列化
2) 判断包的完整性
只要解决了这2个问题,2个不同机器的进程就能完成通信。
协议设计的目标是?
解析效率:互联网业务具有高并发的特点,解析效率决定了使用协议的CPU成本;
编码长度:信息编码出来的长度,编码长度决定了使用协议的网络带宽及存储成本;
易于实现:互联网业务需要一个轻量级的协议,而不是大而全的,CORBA这种重量级的协议就不太适合,易于实现决定了使用协议的开发成本和学习成本;
可读性:编码后的数据的可读性决定了使用协议的调试及维护成本
兼容性: 互联网的需求具有灵活多变的特点,协议会经常升级,使用协议的双方是否可以独立升级协议、增减协议中的字段是非常重要的。兼容性决定了持续开发时的开发成本,个人觉得这点是互联网协议中最重要的一个指标。
二. 序列化/反序列化:
序列化我们常称之为编码,或者打包,反序列化常称之为解码,或者解包。最常用的是如下两种方式:
1. TLV编码及其变体(后面统称为TLV编码):Protobuf/thrift/ASN BER都属于这种。
TLV编码基本原理是每个字段打一个二进制包,每个包包含tag、length、value 3个部分:
tag: 一般占用1个字节,表示数据类型,有的编码方式(Protobuf/thrift)中tag包含字段的id,有的编码方式(ASN BER)不包含字段的id。包含字段id的序列化方式,id是字段的标志,协议可以灵活的增删字段,只要保证字段id唯一,就能兼容解析,非常适合互联网开发。
length:一个整数,表示后面数据块的长度,Protobuf/thrift的序列化不包含length字段,因为大部分数据类型的长度都可以根据tag中的类型信息可以得到。
value:真正的数据内容
2. 文本流编码:xml/json都属于这种。
基本原理是把每个字段打一个字符串形式的包,通过键值对(key-value)的方式存储数据,key是字段的名字,用于区分不同的字段(对比上面TLV编码采用id的方式标志一个字段),特殊字符特别是非文本字符需要做适当转义,转义为xml/json的合法字符。xml的解析效率低于json,而编码长度高于json,json作为序列化的方式一般是优于xml的。
同样是上面的协议:
序列化的结果大概是
<p><name>xxxname><age>18age>p>
或者
{name:xxx,age:18}
文本流编码的特点是:解析效率低,编码长度高,易于实现,可扩展性高,可读性好
3. 效率问题

4. 包完整性判断
TCP的CRC校验是不能完全保证数据可靠性的,所有还需应用层来做一次校验,MD5、adlert32都是可以的。
包长度存储一般有两种方法:
1) 在序列化后的buffer前面增加一个采用固定结构编码的头部,头部长度和结构固定,其中有个字段存储包总长度。收包时,先接收固定字节数的头部,解出这个包完整长度,按此长度接收包体。
2) 在序列化后的buffer前面增加一个字符流的头部,其中有个字段存储包总长度,根据特殊字符(比如根据\n 或者\0)判断头部的完整性。这样通常比1要麻烦一些,http、memcached和radis采用的是这种方式。收包的时候,先判断已收到的数据中是否包含结束符,收到结束符后解析包头,解出这个包完整长度,按此长度接收包体。
protobuf包的通常格式引用一下陈硕的一个例子如下:
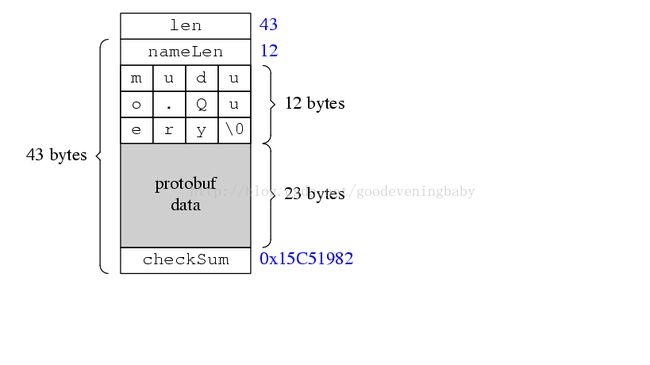
三. 移动应用业务层协议注意点
1. 基于无状态的server模型来设计协议,无状态的server具有颇多的好处,比如逻辑简洁,易于维护,易于分布式扩展。但是因为是“无状态”的,所以客户端的每一个请求在server看来都是独立不连续的,所以我们在协议中需要设计字段来来回传递“状态”。 attachInfo字段
“状态”可能是:
a 时间戳 b 分页信息 等等
2. 可下发的模型,有时候ios应用一旦发布就很难更改了,所以尽可能让app的一些特性能够被后台控制。
3. refer字段,能够标示一个网络请求来源于哪个客户端页面,对于一些有统计需求的特性来说,应该预留这个接口参数。
4. 在移动开发中应该极力避免不必要的重复请求,所以对于一些变动性不强的数据(例如好友列表),server可以提前准备好好友列表包的MD5编码,通过之前的请求的回包(例如登录请求)带给客户端,客户端通过对比MD5和缓存中的MD5来确定好友列表是否更新。
参考:
1. 互联网后台服务的协议设计 http://www.cnblogs.com/liyulong1982/p/3404947.html