spark写入hdfs
spark streaming写入hdfs
场景: 需要将数据写入hdfs,打包成一个gz包, 每5分钟执行一次spark任务。
最终的结果如下:
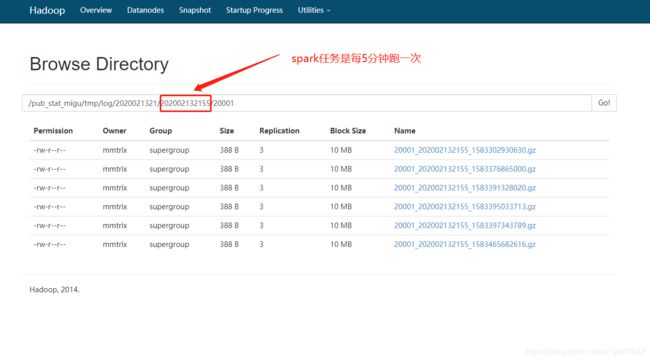
5分钟跑一次spark, 将数据写入hdfs, 会产生很多的小文件。
spark代码
val hadoopConf: Configuration = rdd.context.hadoopConfiguration
hadoopConf.set("mapreduce.output.fileoutputformat.compress", "true")
hadoopConf.set("mapreduce.output.fileoutputformat.compress.codec", "org.apache.hadoop.io.compress.GzipCodec")
hadoopConf.set("mapreduce.output.fileoutputformat.compress.type", "BLOCK")
dataToSaveHdfs.saveAsNewAPIHadoopFile(ConfigInfo.saveHdfsMarkDataPathConfig, classOf[Text], classOf[Text], classOf[StreamingDataGzipOutputFormat[Text, Text]])
注释:
dataToSaveHdfs是RDD
ConfigInfo.saveHdfsMarkDataPathConfig 是配置文件的hdfs路径, 上图的/pub_stat_migu/tmp/log/路径
StreamingDataGzipOutputFormat是一个类
StreamingDataGzipOutputFormat.java类 // 主要是实现Hadoop MapReduce重写FileOutputFormat
import com.hadoop.compression.lzo.LzopCodec;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.mapreduce.OutputCommitter;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.TaskID;
import org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.ReflectionUtils;
import java.io.DataOutputStream;
import java.io.IOException;
import java.text.NumberFormat;
import java.util.HashMap;
import java.util.Iterator;
// Hadoop MapReduce的FileOutputFormat
public class StreamingDataGzipOutputFormat<K, V> extends FileOutputFormat<K, V> {
private StreamingDataGzipOutputFormat<K, V>.MultiRecordWriter writer;
private String jobId;
private static final NumberFormat NUMBER_FORMAT = NumberFormat.getInstance();
public StreamingDataGzipOutputFormat() {
this.jobId = null;
}
@Override
public RecordWriter<K, V> getRecordWriter(TaskAttemptContext job)
throws IOException, InterruptedException {
if (this.writer == null) {
this.writer = new MultiRecordWriter(job, getTaskOutputPath(job));
}
if (this.jobId == null) {
this.jobId = String.valueOf(job.getJobID().getId());
}
return this.writer;
}
private Path getTaskOutputPath(TaskAttemptContext job) throws IOException {
Path workPath = null;
OutputCommitter committer = super.getOutputCommitter(job);
if ((committer instanceof FileOutputCommitter)) {
workPath = ((FileOutputCommitter) committer).getWorkPath();
} else {
Path outputPath = FileOutputFormat.getOutputPath(job);
if (outputPath == null) {
throw new IOException("Undefined job output-path");
}
workPath = outputPath;
}
return workPath;
}
/**
* 提供并发量: 批量写入数据,存在写入同一个或者不同的路径情况
*/
public class MultiRecordWriter extends RecordWriter<K, V> {
private HashMap<String, RecordWriter<K, V>> recordWriters;
private TaskAttemptContext job;
private Path workPath;
public MultiRecordWriter(TaskAttemptContext job, Path workPath) {
this.job = job;
this.workPath = workPath;
this.recordWriters = new HashMap();
}
@Override
public void close(TaskAttemptContext context) throws IOException, InterruptedException {
Iterator values = this.recordWriters.values().iterator();
while (values.hasNext()) {
((RecordWriter) values.next()).close(context);
}
this.recordWriters.clear();
}
protected String[] generateFileNameForKeyValue(K key, V value) {
if ((key == null) || (value == null)) {
return null;
}
String keyStr = key.toString();
String[] fileInfo = new String[3];
if (keyStr.startsWith("ERROR")) {
String[] keyStrs = StringUtils.split(keyStr.substring("ERROR".length() + 1), "_");
fileInfo[0] = (this.workPath.toString() + "/ERROR/" + StringUtils.substring(keyStrs[1], 0, 10) + "/" + keyStrs[1] + "/" + keyStrs[0]);
fileInfo[1] = ("ERROR_" + keyStrs[0] + "_" + keyStrs[1]);
} else {
//20001_202002132155_1583302930630.gz
String[] keyStrs = StringUtils.split(keyStr, "_");
fileInfo[0] = (this.workPath.toString() + "/" +StringUtils.substring(keyStrs[1], 0, 10) + "/" + keyStrs[1] + "/" + keyStrs[0]);
fileInfo[1] = (keyStrs[0] + "_" + keyStrs[1]);
}
fileInfo[2] = (fileInfo[1] + "_" + System.currentTimeMillis());
return fileInfo;
}
@Override
public void write(K key, V value)
throws IOException, InterruptedException {
String[] fileInfo = generateFileNameForKeyValue(key, value);
if (fileInfo != null) {
RecordWriter rw = (RecordWriter) this.recordWriters.get(fileInfo[1]);
if (rw == null) {
rw = getBaseRecordWriter(this.job, fileInfo);
this.recordWriters.put(fileInfo[1], rw);
}
rw.write(key, value);
}
}
private RecordWriter<K, V> getBaseRecordWriter(TaskAttemptContext job, String[] fileInfo) throws IOException, InterruptedException {
Configuration conf = job.getConfiguration();
String keyValueSeparator = "_";
RecordWriter recordWriter = null;
if (!FileOutputFormat.getCompressOutput(job)) { // 如果是压缩,则根据压缩获取扩展名
Path file = new Path(new Path(fileInfo[0]), fileInfo[2]);
FSDataOutputStream fileOut = file.getFileSystem(conf).create(file, false, 1048576, (short) 3, 10485760);
recordWriter = new MessageRecordWriter(new DataOutputStream(fileOut), keyValueSeparator);
} else {
Class codecClass = FileOutputFormat.getOutputCompressorClass(job, LzopCodec.class);
CompressionCodec codec = (CompressionCodec) ReflectionUtils.newInstance(codecClass, conf);
Path file = new Path(new Path(fileInfo[0]), fileInfo[2] + codec.getDefaultExtension());
FSDataOutputStream fileOut = file.getFileSystem(conf).create(file, false, 1048576, (short) 3, 10485760);
recordWriter = new MessageRecordWriter(new DataOutputStream(codec.createOutputStream(fileOut)), keyValueSeparator);
}
return recordWriter;
}
}
}
存在写入同一个或者不同的路径情况
MultiRecordWriter 类 —>提供并发量: 批量写入数据,存在写入同一个或者不同的路径情况
MessageRecordWriter 有点像单个hdfs路径的对象,把所有出现的路径保存下来HashMap
数据来就直接写入, 不需要新打开一个hdfs路径对象。
MessageRecordWriter.java
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import java.io.DataOutputStream;
import java.io.IOException;
import java.io.UnsupportedEncodingException;
public class MessageRecordWriter<K, V> extends RecordWriter<K, V> {
private static final String utf8 = "UTF-8";
private static final byte[] newline;
protected DataOutputStream out;
private final byte[] keyValueSeparator;
public MessageRecordWriter(DataOutputStream out, String keyValueSeparator) {
this.out = out;
try {
this.keyValueSeparator = keyValueSeparator.getBytes("UTF-8");
} catch (UnsupportedEncodingException uee) {
throw new IllegalArgumentException("can't find UTF-8 encoding");
}
}
public MessageRecordWriter(DataOutputStream out) {
this(out, "\t");
}
private void writeObject(Object o) throws IOException {
if ((o instanceof Text)) {
Text to = (Text) o;
this.out.write(to.getBytes(), 0, to.getLength());
} else {
this.out.write(o.toString().getBytes("UTF-8"));
}
}
@Override
public synchronized void write(K key, V value) throws IOException {
boolean nullKey = (key == null) || ((key instanceof NullWritable));
boolean nullValue = (value == null) || ((value instanceof NullWritable));
if ((nullKey) && (nullValue)) {
return;
}
if (!nullValue) {
writeObject(value);
}
this.out.write(newline);
}
@Override
public synchronized void close(TaskAttemptContext context) throws IOException {
this.out.flush();
this.out.close();
}
static {
try {
newline = "\n".getBytes("UTF-8");
} catch (UnsupportedEncodingException uee) {
throw new IllegalArgumentException("can't find UTF-8 encoding");
}
}
}