【开源计划】图像配准中变形操作(Warp)的pytorch实现
前言
按照开源计划的预告,这次我来分享图像配准流程中的变形操作的代码实现。首先我们先来回顾一下配准的流程,我们以这篇Unsupervised End-to-end Learning for Deformable Medical Image Registration论文中的流程图为例,进行说明。该论文提出的配准框架是基于无监督学习的端到端的非刚性图像配准,配准网络(registration network)根据输入的浮动图像(moving image)与固定图像(fixed image)预测出变形场(deformation field),然后采样网格生成器(sampling grid generator)生成规则网格(regular grid),并与变形场结合得到采样网格(sampling grid),再经过采样器(sampler)对浮动图像进行重采样即得到变形后的图像(warped image)。其中,从规则网格生成到得到变形后的图像的过程一般称为变形(warp,可能翻译的不够准确与专业)。另外,这个过程也正是论文Spatial Transformer Networks的思想,只不过最初该论文的应用是在自然图像的检测与分类任务上的,后来才被引入到医学图像配准上。正是它的引入,使得这种基于无监督学习的图像配准变得可行。
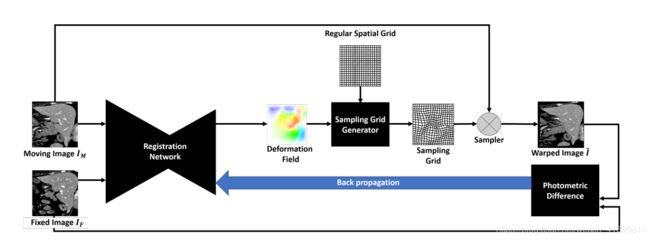
该流程图的原始说明引用如下:
Fig. 2: Illustration of the unsupervised training strategy of our fully convolutional image-to-image registration network. The registration network takes two images and outputs a deformation field, which is used to produce the sampling grid. The moving image is then warped by the sampling grid via bilinear interpolation. The loss function is defined as the photometric difference between the warped image and the fixed image. The registration error can be efficiently back propagated to update the learnable parameters of the registration network for end-to-end training.
值得注意的是,如果要使用基于无监督学习的配准框架,对网络进行端到端地训练,就需要依靠论文Spatial Transformer Networks的思想,实现一个可反向梯度计算的重采样函数,将这个变形操作纳入到配准模型框架之中。这个操作的实现对于一般的研究生来说无疑难度是巨大的,很庆幸,pytorch框架提供了一个这样的函数,称为grid_sample函数,为研究者们构建Spatial Transformer Networks提供了方便。具体介绍请点击链接,参看pytorch的官方文档说明。下面我将使用该函数,编写变形(warp)的函数。
准备
首先,导入依赖包
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
二维图像变形(Warp)
变形(Warp)的操作内容就是,在初始化的过程中先生成一个与图像大小相同的网格,即规则网格,如果使用规则网格对图像变形,则可以得到一个与原始图像相同的图像,图像不发生形变,这个过程的可视化可以参考我的另一篇博客。在调用变形函数时,需要提供两个参数,一个是原始图像,一个是变形场(flow-field),将变形场与规则网格相加,然后对原始图像进行重采样。代码的实现,我参考一篇称为PWC-Net的论文的开源代码(这里是链接)其中的warp函数进行了修改,具体如下:
class Warper2d(nn.Module):
def __init__(self, img_size):
super(Warper2d, self).__init__()
"""
warp an image/tensor (im2) back to im1, according to the optical flow
# img_src: [B, 1, H1, W1] (source image used for prediction, size 32)
img_smp: [B, 1, H2, W2] (image for sampling, size 44)
flow: [B, 2, H1, W1] flow predicted from source image pair
"""
self.img_size = img_size
H, W = img_size, img_size
# mesh grid
xx = torch.arange(0, W).view(1,-1).repeat(H,1)
yy = torch.arange(0, H).view(-1,1).repeat(1,W)
xx = xx.view(1,H,W)
yy = yy.view(1,H,W)
self.grid = torch.cat((xx,yy),0).float() # [2, H, W]
def forward(self, flow, img):
grid = self.grid.repeat(flow.shape[0],1,1,1)#[bs, 2, H, W]
if img.is_cuda:
grid = grid.cuda()
# if flow.shape[2:]!=img.shape[2:]:
# pad = int((img.shape[2] - flow.shape[2]) / 2)
# flow = F.pad(flow, [pad]*4, 'replicate')#max_disp=6, 32->44
vgrid = Variable(grid, requires_grad = False) + flow
# scale grid to [-1,1]
# vgrid[:,0,:,:] = 2.0*vgrid[:,0,:,:]/(W-1)-1.0 #max(W-1,1)
# vgrid[:,1,:,:] = 2.0*vgrid[:,1,:,:]/(H-1)-1.0 #max(H-1,1)
vgrid = 2.0*vgrid/(self.img_size-1)-1.0 #max(W-1,1)
vgrid = vgrid.permute(0,2,3,1)
output = F.grid_sample(img, vgrid)
# mask = Variable(torch.ones(img.size())).cuda()
# mask = F.grid_sample(mask, vgrid)
#
# mask[mask<0.9999] = 0
# mask[mask>0] = 1
return output#*mask
三维图像变形(Warp)
根据二维图像变形操作的思路,我将其拓展到了三维图像配准上,以下是实现代码:
class Warper3d(nn.Module):
def __init__(self, img_size):
super(Warper3d, self).__init__()
"""
warp an image, according to the optical flow
image: [B, 1, D, H, W] image for sampling
flow: [B, 3, D, H, W] flow predicted from source image pair
"""
self.img_size = img_size
D, H, W = img_size
# mesh grid
xx = torch.arange(0, W).view(1,1,-1).repeat(D,H,1).view(1,D,H,W)
yy = torch.arange(0, H).view(1,-1,1).repeat(D,1,W).view(1,D,H,W)
zz = torch.arange(0, D).view(-1,1,1).repeat(1,H,W).view(1,D,H,W)
self.grid = torch.cat((xx,yy,zz),0).float() # [3, D, H, W]
def forward(self, img, flow):
grid = self.grid.repeat(flow.shape[0],1,1,1,1)#[bs, 3, D, H, W]
# mask = torch.ones(img.size())
if img.is_cuda:
grid = grid.cuda()
# mask = mask.cuda()
vgrid = grid + flow
# scale grid to [-1,1]
D, H, W = self.img_size
vgrid[:,0] = 2.0*vgrid[:,0]/(W-1)-1.0 #max(W-1,1)
vgrid[:,1] = 2.0*vgrid[:,1]/(H-1)-1.0 #max(H-1,1)
vgrid[:,2] = 2.0*vgrid[:,2]/(D-1)-1.0 #max(H-1,1)
vgrid = vgrid.permute(0,2,3,4,1)#[bs, D, H, W, 3]
output = F.grid_sample(img, vgrid, padding_mode='border')#, mode='nearest'
# mask = F.grid_sample(mask, vgrid)#, mode='nearest'
# mask[mask<0.9999] = 0
# mask[mask>0] = 1
return output#*mask另外,voxelmorph开源代码提供了TensorFlow实现的Spatial Transformer Networks,有兴趣的可以查看其代码。
结束语
最后,以上仅供参考,欢迎各位网友批评指正与留言交流。
有兴趣的还可以关注一下我的B站账号:Timmy_毛毛,方便及时获取更新视频内容,谢谢~