Spark——部署详解及问题解决
本节目标:
掌握Spark的部署方式
所需软件:spark-2.2.1-bin-hadoop2.7
|
|
NN |
DN |
JN |
ZK |
ZKFC |
RM |
NM |
Master |
Worker |
| master(192.168.85.10) |
l |
|
|
l |
l |
|
|
l |
|
| slave1(192.168.85.11) |
l |
l |
l |
l |
l |
|
l |
l |
l |
| slave2(192.168.85.12) |
|
l |
l |
l |
|
l |
l |
|
l |
| slave3(192.168.85.13) |
|
l |
l |
|
|
l |
l |
|
l |
Spark部署方式主要有三种:local模式,standalone模式,spark on yarn 模式。
1、local单机模式:
解压安装即可
测试:./bin/spark-submit --class org.apache.spark.examples.SparkPi --master local[1] ./examples/jars/spark-examples_2.11-2.2.1.jar 100
2、standalone集群式:
1.每台解压安装spark
注意:环境变量可不用配置,start-all.sh容易与hadoop命令冲突
3.cp conf/spark-env.sh.template conf/spark-env.sh
4.修改spark-env.sh
export JAVA_HOME=/usr/local/src/jdk1.8
export SPARK_MASTER_IP=master
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_CORES=1
export SPARK_WORKER_INSTANCES=1
export SPARK_WORKER_MEMORY=1g
5.修改slaves
salve1
slave2
slave3
6.配置文件同步到其他节点
7.启动
./sbin/start-all.sh
8.webUI:
master:8080
9.HA配置
spark-env.sh添加:
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=master:2181,slave1:2181,slave2:2181"
10.同步spark-env.sh配置文件
11.slave1热备节点spark-env.sh修改:
export SPARK_MASTER_IP=slave1
12.启动热备节点
./sbin/start-master.sh
因为用到zk集群,启动spark前,先启动zk。
13.测试故障是否自动切换
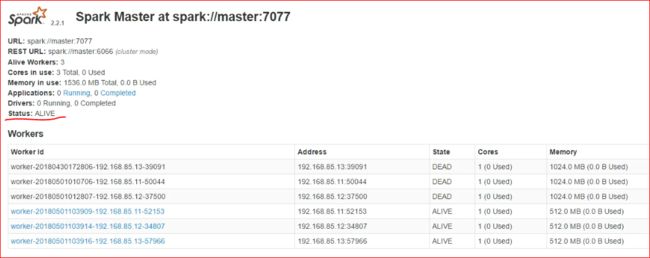
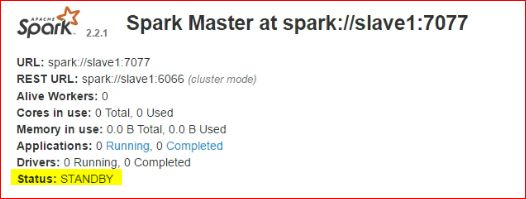
14、测试任务提交
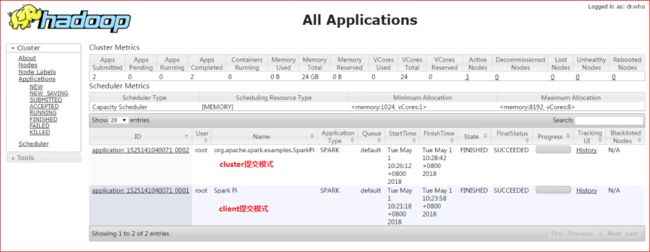
standalone模式分为两种运行方式:
client方式:运行结果在客户端直接可见
测试:./bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://master:7077 ./examples/jars/spark-examples_2.11-2.2.1.jar 100
cluster方式:运行结果不能直接可见,可在webUI中查到
测试:./bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://master:7077 --deploy-mode cluster ./examples/jars/spark-examples_2.11-2.2.1.jar 100
3、spark on yarn模式:
基于Hadoop部署
1.spark-env.sh增加
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SCALA_HOME=/usr/local/src/scala-2.11.12
export SPARK_HOME=/usr/local/src/spark-2.2.1-bin-hadoop2.7
export PATH=$SPARK_HOME/bin:$PATH
export SPARK_JAR=$SPARK_HOME/jars/*
2.同步配置文件
3.启动hadoop,此时不应启动spark,否则会造成资源管理器冲突。
4.测试
client:运行结果在客户端直接可见
测试:./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client ./examples/jars/spark-examples_2.11-2.2.1.jar 100
cluster:运行结果不能直接可见
测试:./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster ./examples/jars/spark-examples_2.11-2.2.1.jar 100
可能出现的报错:
ERROR spark.SparkContext: Error initializing SparkContext.
org.apache.spark.SparkException: Yarn application has already ended! It might have been killed or unable to launch application master.
For more detailed output, check application tracking page:http://slave3:8088/cluster/app/application_1525099301044_0003Then, click on links to logs of each attempt.
Diagnostics: Container [pid=2391,containerID=container_1525099301044_0003_02_000001] is running beyond virtual memory limits. Current usage: 40.8 MB of 1 GB physical memory used; 2.2 GB of 2.1 GB virtual memory used. Killing container.该错误是YARN的虚拟内存计算方式导致,上例中用户程序申请的内存为1Gb,YARN根据此值乘以一个比例(默认为2.1)得出申请的虚拟内存的值,当YARN计算的用户程序所需虚拟内存值大于计算出来的值时,就会报出以上错误。
解决方式:
1、修改yarn-site.xml
yarn配置文件中 containers 的默认属性有关,被强制限定了物理内存
![]()
yarn.nodemanager.vmem-check-enabled
false
yarn.nodemanager.pmem-check-enabled
false
yarn.nodemanager.vmem-pmem-ratio
4
2、SPARK_HOME/conf下的spark-defaults.conf.template,改名为spark-defaults.conf,修改并同步

官方默认为512m
