PU-Net阅读笔记:点云的上采样
简述
PU-Net在点云上进行上采样,即输入一个点云,输出一个更密的点云,且它落在输入点云隐含的几何体(比如表面)上。点云上采样和图片的超分辨率很像,但因为是三维的点而不是二维的像素,因此也有点云不规则、无顺序的一系列缺陷。PU-Net的核心思想,是学习到每个点多个粒度(从局部到全局)下的特征,再在特征空间中扩大点集,最后将扩大的点集映射回三维。提取特征的方法基于PointNet++。
邻域选择
在模型表面上随机选择 M M M个中心点,然后指定一个测地线距离 d d d,将 d d d范围内的点和中心点一起作为一个Patch。然后,我们使用Poisson disk sampling来随机采样 N ^ \hat{N} N^个点,作为ground truth。我们可以改变 d d d的大小,从而形成不同尺度、不同密度的patch。
层次特征学习
此部分采用了PointNet++的算法,得到了各个尺度上点的特征。注意这里每层聚类的半径比较小,这样可以保留住更多的局部细节特征。
多层次特征融合
越低层次的特征对应着越局部的特征。对于高层次的特征,PointNet++采用了按归属(连接)关系将它们传递到每个点上。但PU-Net的作者认为这样不是很高效,因此采用了直接加权融合的方法。即
f ( l ) ( x ) = ∑ i = 1 3 w i ( x ) f ( l ) ( x i ) ∑ i = 1 3 w i ( x ) f^{(l)}(x) = \frac{ \sum_{i=1}^3 w_i(x) f^{(l)}(x_i) }{ \sum_{i=1}^3 w_i(x) } f(l)(x)=∑i=13wi(x)∑i=13wi(x)f(l)(xi)
它表示了点 x x x在第 l l l层的特征为它最临近三个中心点 x 1 , x 2 , x 3 x_1, x_2, x_3 x1,x2,x3的加权和,其中权重 w i ( x ) w_i(x) wi(x)为距离反比。
然后,我们在每个点上将其各层次的特征做一个concatenate,作为该点的特征。
特征展开
令 N N N为点的数量, C ~ \tilde{C} C~为特征的维度。我们的目标是得到 r N rN rN个特征,其中 r r r为上采样率。按照代码里的做法,首先将 N × C ~ N \times \tilde{C} N×C~扩展到 r N × C ~ rN \times \tilde{C} rN×C~,然后通过两个各点独立的 1 × 1 1 \times 1 1×1的卷积核,得到 r N × C ~ 2 rN \times \tilde{C}_2 rN×C~2的张量。
坐标重建
最后,通过多个全连接层,将 r N × C ~ 2 rN \times \tilde{C}_2 rN×C~2的张量转化为 r N × 3 rN \times 3 rN×3,得到最终的结果。
训练过程
对于一个模型,我们当然事先不知道它上采样的结果。因此训练时,我们首先对模型进行下采样,然后用原模型作为ground truth。
损失函数
重建损失
重建损失测量了生成的点云和ground truth之间的推土机距离EMD(Earth Move Distance),即令生成的点云为 S p S_p Sp,ground truth点云为 S g t S_{gt} Sgt,则此距离为
L r e c = d E M D ( S p , S g t ) = min ϕ : S p → S g t ∑ x i ∈ S p ∣ ∣ x i − ϕ ( x i ) ∣ ∣ 2 L_{rec} = d_{EMD}(S_p,S_{gt}) = \min_{\phi: S_p \rightarrow S_{gt}} \sum_{x_i \in S_p} || x_i - \phi(x_i) ||_2 Lrec=dEMD(Sp,Sgt)=ϕ:Sp→Sgtminxi∈Sp∑∣∣xi−ϕ(xi)∣∣2
其中, ϕ : S p → S g t \phi: S_p \rightarrow S_{gt} ϕ:Sp→Sgt是一个从生成点云到ground truth的双射。
另一个常用的点云之间距离的度量方式是CD,Chamfer Distance。和CD相比,EMD可以更好地使点接近模型的隐藏表面。
排斥损失
如果只有重建损失,则从一个点派生出来的 r r r个点很可能会聚集在一起。为了使这些点分开一些,作者增加了排斥损失。
L r e p = ∑ i = 0 N ^ ∑ i ′ ∈ K ( i ) η ( ∣ ∣ x i ′ − x i ∣ ∣ ) w ( ∣ ∣ x i ′ − x i ∣ ∣ ) L_{rep} = \sum_{i=0}^{\hat{N}} \sum_{i' \in K(i)} \eta(|| x_{i'}-x_i ||) w(||x_{i'}-x_i||) Lrep=i=0∑N^i′∈K(i)∑η(∣∣xi′−xi∣∣)w(∣∣xi′−xi∣∣)
其中, N ^ = r N \hat{N}=rN N^=rN, K ( i ) K(i) K(i)为 x i x_i xi的 K K K近邻。 η ( r ) = − r \eta(r)=-r η(r)=−r为排斥项,距离越近 η ( r ) \eta(r) η(r)越大。 w ( r ) = e − r 2 / h 2 w(r)=e^{-r^2/h^2} w(r)=e−r2/h2为权重项,距离越近权重越大。论文里没有提及 h h h是什么,感觉是一个权重的超参数。
总损失
L ( θ ) = L r e c + α L r e p + β ∣ ∣ θ ∣ ∣ 2 L(\theta) = L_{rec} + \alpha L_{rep} + \beta ||\theta||^2 L(θ)=Lrec+αLrep+β∣∣θ∣∣2
其中,最后一项为正则化项。
实验结果
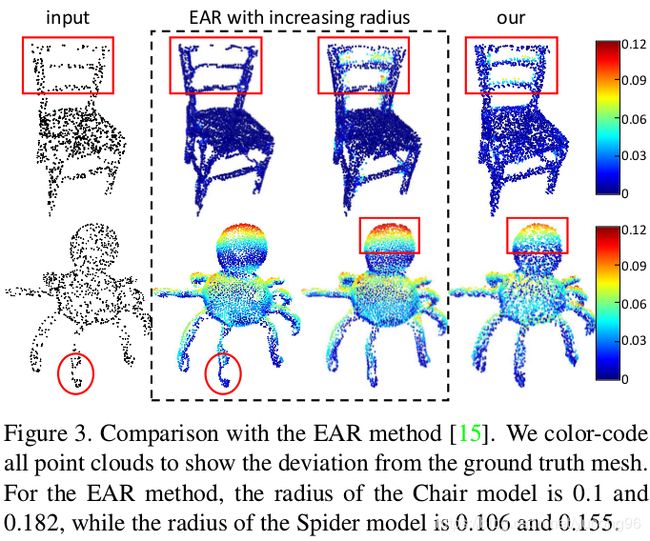
与另一个方法EAR的比较
参考文献
Yu, Lequan, et al. “Pu-net: Point cloud upsampling network.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018.