很多网页的信息都是通过异步加载的,本文就举例讨论下此类网页的抓取。
《工作细胞》最近比较火,bilibili 上目前的短评已经有17000多条。
先看分析下页面
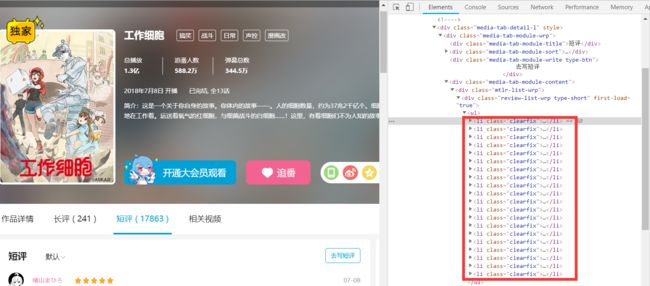
右边 li 标签中的就是短评信息,一共20条。一般我们加载大量数据的时候,都会做分页,但是这个页面没有,只有一个滚动条。
随着滚动条往下拉,信息自动加载了,如下图,变40条了。由此可见,短评是通过异步加载的。

我们不可能一次性将滚动条拉到最下面,然后来一次性获取全部的数据。既然知道是通过异步来加载的数据,那么我们可以想办法直接去获取这些异步的数据。
打开 Network 查看分析 http 请求,可以点击 XHR 过滤掉 img、css、js 等信息。这时我们发现了一些 fetch。fetch 我对它的了解就是一个比 ajax 更高级更好用的 API,当然这肯定是不准确的,但并并不影响我们的爬虫。
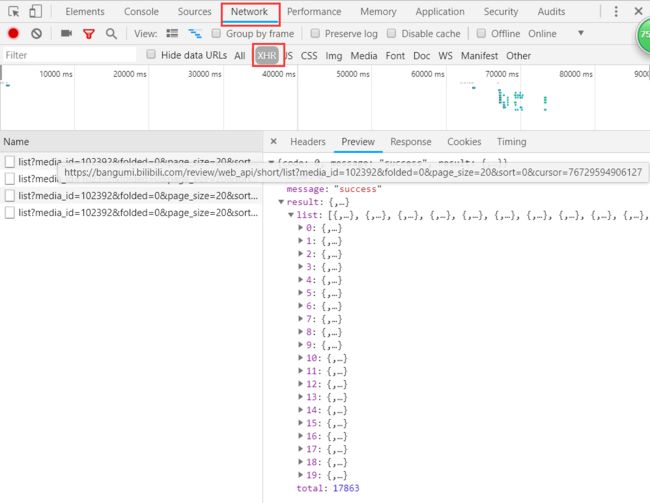
我们可以看到,其中返回的就是我们需要的内容,json 格式,一共20条,total 属性就是总的数目。分析一下 url 地址:https://bangumi.bilibili.com/review/web_api/short/list?media_id=102392&folded=0&page_size=20&sort=0&cursor=76729594906127
media_id 想必就是《工作细胞》的 id 了;
folded 不知道是啥,可以不管;
page_size 是每页的条数;
sort 排序,看名字就知道,找到排序的选项,试了下,果然是的,默认0,最新1;

cursor,字面意思的光标,猜测应该是指示本次获取开始的位置的,展开获取到的 json,发现其中包含有 cursor 属性,对比以后可以发现,url中的值跟上一次返回结果中的最后一条中的 cursor 的值是一致的。
好了,至此,页面已经分析清楚了,爬取的方式也明显了,根本不用管网页,直接根据 fetch 的地址获取 json 数据就可以了,连网页解析都省了,超级的方便。
下面的完整的代码:(如果 fake_useragent 报错,就手动写个 User-Agent 吧,那个库极度的不稳定)
import csv
import os
import time
import requests
from fake_useragent import UserAgent
curcount = 0
def main():
url = 'https://bangumi.bilibili.com/review/web_api/short/list?media_id=102392&folded=0&page_size=20&sort=0'
crawling(url)
def crawling(url):
print(f'正在爬取:{url}')
global curcount
headers = {"User-Agent": UserAgent(verify_ssl=False).random}
json_content = requests.get(url, headers).json()
total = json_content['result']['total']
infolist = []
for item in json_content['result']['list']:
info = {
'author': item['author']['uname'],
'content': item['content'],
'ctime': time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(item['ctime'])),
'likes': item['likes'],
'disliked': item['disliked'],
'score': item['user_rating']['score']
}
infolist.append(info)
savefile(infolist)
curcount += len(infolist)
print(f'当前进度{curcount}/{total}')
if curcount >= total:
print('爬取完毕。')
return
nexturl = f'https://bangumi.bilibili.com/review/web_api/short/list?' \
f'media_id=102392&folded=0&page_size=20&sort=0&cursor={json_content["result"]["list"][-1]["cursor"]}'
time.sleep(1)
crawling(nexturl)
def savefile(infos):
with open('WorkingCell.csv', 'a', encoding='utf-8') as sw:
fieldnames = ['author', 'content', 'ctime', 'likes', 'disliked', 'score']
writer = csv.DictWriter(sw, fieldnames=fieldnames)
writer.writerows(infos)
if __name__ == '__main__':
if os.path.exists('WorkingCell.csv'):
os.remove('WorkingCell.csv')
main()
相关博文推荐:
Python爬虫实例:爬取猫眼电影——破解字体反爬
Python爬虫实例:爬取豆瓣Top250