看图说话:从图片到文字
文章目录
- 模型整体结构
- 比较翻译模型和看图说话
- 编码器模型
- 解码器模型
- 训练和评估
- 了解数据集
- 了解pack_padded_sequence函数和pad_packed_sequence函数
- 对梯度进行clip操作
- epoch级别的训练函数
- epoch级别的评估函数
- 引入注意力机制
- Soft attention原理及实现
- Attention
- 矩阵相乘test(理解上面的encoder_out * alpha.unsqueeze(2))
- 引入attention的解码器
- Beam Search
模型整体结构
import sys
import torch
import torch.nn as nn
import torchvision
from torch.nn.utils.rnn import pack_padded_sequence
from torch.nn.utils.rnn import pad_packed_sequence
from scipy.misc import imread, imresize
import torch.nn.functional as F
import numpy as np
import json
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import matplotlib.cm as cm
import skimage.transform
from PIL import Image
sys.path.append("./src")
from action import AverageMeter #Metric class defined in src/action, read code when availabel
from dataset import Dataset #Dataset class defined in src/action, read code when availabel
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
比较翻译模型和看图说话
Language translation means to translate a kind of language to another.
When it comes to image caption, we could take image as a special kind of “language”.
In this ways, we could
follow the method that we apply in translation tasks.
In Week11, we have implemented a
naive Seq2seq models, a model that generates sequences will use an Encoder to encode the input into a fixed form and a Decoder to decode it, word by word, into a sequence.
In translation task, we usuallly use RNN as both the encoder and decoder.
In image caption, we use CNN as the encoders instead of RNN.
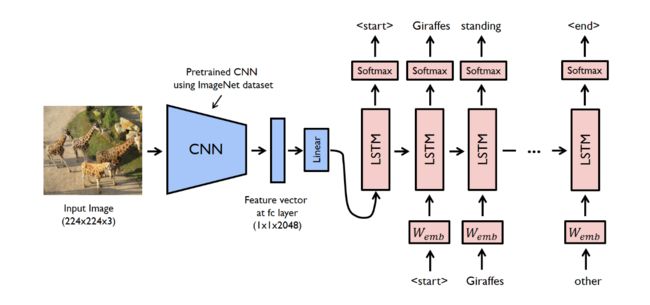
编码器模型
Encoder would be implemented as below

class Encoder(nn.Module):
"""Encoder
"""
def __init__(self, encoded_image_size=14):
super(Encoder, self).__init__()
self.encoded_image_size = encoded_image_size
self.backbone = self.get_backbone()
# 只需要给定输出特征图的大小就好,直接输出你想要的大小
self.adaptive_pool = nn.AdaptiveAvgPool2d((encoded_image_size, encoded_image_size))
def forward(self, images):
"""
Forward propagation.
:param images: images, a tensor of dimensions (batch_size, 3, image_size, image_size)
:return: encoded images
"""
# (batch_size, 2048, image_size/32, image_size/32)
out = self.backbone(images)
# (batch_size, 2048, encoded_image_size, encoded_image_size)
out = self.adaptive_pool(out)
# (batch_size, encoded_image_size, encoded_image_size, 2048)
out = out.permute(0, 2, 3, 1)
return out
def get_backbone(self):
"""Get backbone"""
# 加载预训练好的resnet101模型
resnet = torchvision.models.resnet101(pretrained=True)
# 去掉模型最后的线性连接层和池化层
models = list(resnet.children())[:-2]
backbone = nn.Sequential(*models)
return backbone
解码器模型
Decoder would implement as below
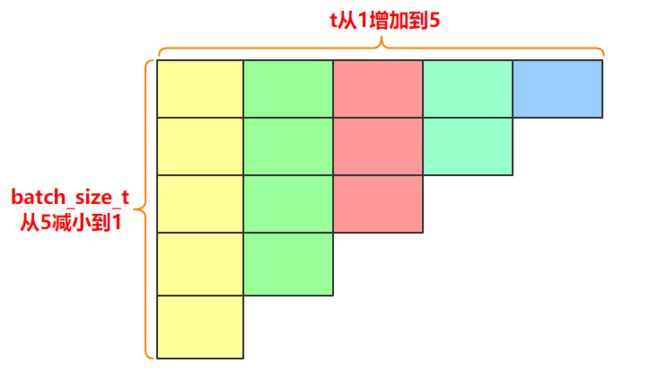
如何将一个batch里面长度不同的句子拆分成更小的batch单位进行计算:见decoder中batch_size_t和t的使用。
class Decoder(nn.Module):
"""Decoder
"""
def __init__(self, embed_dim, decoder_dim, vocab_size, encoder_dim=2048, dropout=0.5):
"""
:param attention_dim: size of attention network
:param embed_dim: embedding size
:param decoder_dim: size of decoder's RNN
:param vocab_size: size of vocabulary
:param encoder_dim: feature size of encoded images
:param dropout: dropout
"""
super(Decoder, self).__init__()
self.encoder_dim = encoder_dim
self.embed_dim = embed_dim
self.decoder_dim = decoder_dim
self.vocab_size = vocab_size
self.dropout = dropout
# embedding layer
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.dropout = nn.Dropout(p=self.dropout)
#self.decode_step = nn.LSTMCell(embed_dim + encoder_dim, decoder_dim)
self.decode_step = nn.LSTMCell(embed_dim, decoder_dim)
# linear layer to find initial hidden state of LSTMCell
self.init_h = nn.Linear(encoder_dim, decoder_dim)
# linear layer to find initial cell state of LSTMCell
self.init_c = nn.Linear(encoder_dim, decoder_dim)
self.f_beta = nn.Linear(decoder_dim, encoder_dim)
# linear layer to create a sigmoid-activated gate
self.sigmoid = nn.Sigmoid()
# linear layer to find scores over vocabulary
self.fc = nn.Linear(decoder_dim, vocab_size)
self.init_weights()
def forward(self, encoder_out, encoded_captions, caption_lengths):
"""
Forward propagation.
:param encoder_out: encoded images, a tensor of dimension (batch_size, enc_image_size, enc_image_size, encoder_dim)
:param encoded_captions: encoded captions, a tensor of dimension (batch_size, max_caption_length)
:param caption_lengths: caption lengths, a tensor of dimension (batch_size, 1)
:return: scores for vocabulary, sorted encoded captions, decode lengths, weights, sort indices
"""
batch_size = encoder_out.size(0)
encoder_dim = encoder_out.size(-1)
vocab_size = self.vocab_size
device = encoder_out.device
# Flatten image
# (batch_size, num_pixels, encoder_dim)
encoder_out = encoder_out.view(batch_size, -1, encoder_dim)
num_pixels = encoder_out.size(1)
# Sort input data by decreasing lengths; why?
# This is so that we can process only valid timesteps, i.e., not process the s.
# 猜测,是为了保证输入与embedding,h,c的一一对应性,降序排列之后,挑选前三个最长的作为输入,那么对应的embedding和h,c也直接取前三个就可以
# 详见下面的batch_size_t部分
# 通过以下步骤,令一个batch内的encoder_out和encoded_captions按照caption_lengths来降序排序
caption_lengths, sort_ind = caption_lengths.squeeze(1).sort(dim=0, descending=True)
encoder_out = encoder_out[sort_ind]
encoded_captions = encoded_captions[sort_ind]
# Embedding
# (batch_size, max_caption_length, embed_dim)
embeddings = self.embedding(encoded_captions)
# Initialize LSTM state
# (batch_size, decoder_dim)
h, c = self.init_hidden_state(encoder_out)
# We won't decode at the position, since we've finished generating as soon as we generate
# So, decoding lengths are actual lengths - 1
decode_lengths = (caption_lengths - 1).tolist()
# Create tensors to hold word predicion scores and alphas
predictions = torch.zeros(batch_size, max(decode_lengths), vocab_size).\
to(device)
for t in range(max(decode_lengths)):
batch_size_t = sum([l > t for l in decode_lengths])
# 前batch_size_t个输入的decode length递减直到t
# 经过前面的排序,下面的步骤才可以做到一一对应, 注意到h和c也只能截取一小部分
h, c = self.decode_step(
embeddings[:batch_size_t, t, :],
(h[:batch_size_t], c[:batch_size_t]))
preds = self.fc(self.dropout(h))
predictions[:batch_size_t, t, :] = preds
return predictions, encoded_captions, decode_lengths, None, sort_ind
def init_weights(self):
"""
初始化时,均匀分布weight的权重,将bias全部置零
Initializes some parameters with values from the uniform distribution, for easier convergence.
"""
self.embedding.weight.data.uniform_(-0.1, 0.1)
self.fc.bias.data.fill_(0)
self.fc.weight.data.uniform_(-0.1, 0.1)
def init_hidden_state(self, encoder_out):
"""
Creates the initial hidden and cell states for the decoder's LSTM based on the encoded images.
将所有的像素求平均之后,输入到线性连接层获得输出
:param encoder_out: encoded images, a tensor of dimension (batch_size, num_pixels, encoder_dim)
:return: hidden state, cell state
"""
mean_encoder_out = encoder_out.mean(dim=1)
# (batch_size, decoder_dim)
h = self.init_h(mean_encoder_out)
c = self.init_c(mean_encoder_out)
return h, c
训练和评估
Functions introduce here.
clip_gradient: clip gradient
train_epoch: Performs one epoch's training.
eval_epoch: Performs one epoch's validation.
run: Main function to run
了解数据集
"""Dataset"""
import json
import os
import h5py
import torch
import torchvision.transforms as transforms
class Dataset:
def __init__(self, batch_size=32):
# Custom dataloaders
data_folder = "./data"
data_name = "flickr8k_5_cap_per_img_5_min_word_freq"
# Read word map
word_map_file = os.path.join(data_folder, 'WORDMAP_' + data_name +
'.json')
with open(word_map_file, 'r') as j:
self.word_map = json.load(j)
self.rev_word_map = {v: k for k, v in self.word_map.items()} # ix2word
train_dataset, val_dataset = self.load_dataset(data_folder, data_name)
self.train_loader, self.val_loader = self.load_dataloader(train_dataset,
val_dataset,
batch_size)
def load_dataset(self, data_folder, data_name):
"""Load dataset
"""
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
train_dataset = CaptionDataset(data_folder, data_name, 'TRAIN',
transform=transforms.Compose([normalize]))
val_dataset = CaptionDataset(data_folder, data_name, 'VAL',
transform=transforms.Compose([normalize]))
return train_dataset, val_dataset
def load_dataloader(self, train_dataset, val_dataset, batch_size):
"""Init dataloader"""
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size, shuffle=True)
val_loader = torch.utils.data.DataLoader(
val_dataset, batch_size=batch_size, shuffle=True)
return train_loader, val_loader
def get_dataloader(self):
"""Get dataloader
"""
return self.train_loader, self.val_loader
def get_word_map(self):
"""Get word map"""
return self.word_map
def get_rev_word_map(self):
return self.rev_word_map
class CaptionDataset(torch.utils.data.Dataset):
"""
A PyTorch Dataset class to be used in a PyTorch DataLoader to create batches.
"""
def __init__(self, data_folder, data_name, split, transform=None):
"""
:param data_folder: folder where data files are stored
:param data_name: base name of processed datasets
:param split: split, one of 'TRAIN', 'VAL', or 'TEST'
:param transform: image transform pipeline
"""
self.split = split
assert self.split in {'TRAIN', 'VAL', 'TEST'}
# Open hdf5 file where images are stored
self.h = h5py.File(os.path.join(data_folder, self.split + '_IMAGES_' + data_name + '.hdf5'), 'r')
self.imgs = self.h['images']
# Captions per image
self.cpi = self.h.attrs['captions_per_image']
# Load encoded captions (completely into memory)
with open(os.path.join(data_folder, self.split + '_CAPTIONS_' + data_name + '.json'), 'r') as j:
self.captions = json.load(j)
# Load caption lengths (completely into memory)
with open(os.path.join(data_folder, self.split + '_CAPLENS_' + data_name + '.json'), 'r') as j:
self.caplens = json.load(j)
# PyTorch transformation pipeline for the image (normalizing, etc.)
self.transform = transform
# Total number of datapoints
self.dataset_size = len(self.captions)
def __getitem__(self, i):
# Remember, the Nth caption corresponds to the (N // captions_per_image)th image
img = torch.FloatTensor(self.imgs[i // self.cpi] / 255.)
if self.transform is not None:
img = self.transform(img)
caption = torch.LongTensor(self.captions[i])
caplen = torch.LongTensor([self.caplens[i]])
if self.split is 'TRAIN':
return img, caption, caplen
else:
# For validation of testing, also return all 'captions_per_image' captions to find BLEU-4 score
all_captions = torch.LongTensor(
self.captions[((i // self.cpi) * self.cpi):(((i // self.cpi) * self.cpi) + self.cpi)])
return img, caption, caplen, all_captions
def __len__(self):
return self.dataset_size
batch_size = 2
dataset = Dataset(batch_size=batch_size)
word_map = dataset.get_word_map()
rev_word_map = dataset.get_rev_word_map()
train_loader, val_loader = dataset.get_dataloader()
testdata = iter(train_loader).next()
testdata
[tensor([[[[-1.8782, -1.9467, -2.0152, ..., 2.1804, 2.1804, 2.1804],
[-1.8439, -1.9295, -1.9809, ..., 2.1975, 2.1804, 2.1804],
[-1.8439, -1.8953, -1.9467, ..., 2.2147, 2.1804, 2.1804],
...,
[-1.6213, -1.6384, -1.6042, ..., 0.0227, 0.2111, 0.2796],
[-1.7412, -1.7583, -1.6555, ..., 0.6734, 0.6392, 0.6906],
[-1.6727, -1.5870, -1.5014, ..., 0.8276, 0.9646, 0.9132]],
[[-1.8606, -1.8957, -1.9482, ..., 2.4286, 2.4286, 2.4286],
[-1.8256, -1.8606, -1.9132, ..., 2.4286, 2.4286, 2.4286],
[-1.8256, -1.8431, -1.8782, ..., 2.4286, 2.4286, 2.4286],
...,
[-1.0553, -1.0903, -1.0553, ..., 0.3803, 0.6078, 0.6779],
[-1.1779, -1.2129, -1.1078, ..., 1.0630, 1.0105, 1.0455],
[-1.1429, -1.0903, -1.0028, ..., 1.0805, 1.2206, 1.1856]],
[[-1.7870, -1.8044, -1.8044, ..., 2.6400, 2.6400, 2.6400],
[-1.7522, -1.7870, -1.7870, ..., 2.6400, 2.6400, 2.6400],
[-1.7522, -1.7522, -1.7696, ..., 2.6226, 2.6400, 2.6400],
...,
[-0.3753, -0.4101, -0.3753, ..., 1.0714, 1.3154, 1.4200],
[-0.5321, -0.5495, -0.4275, ..., 1.6465, 1.6117, 1.6814],
[-0.4798, -0.3927, -0.2707, ..., 1.7163, 1.8383, 1.7860]]],
[[[-0.6281, -0.6623, -0.6623, …, -0.6452, -0.8164, -0.5767],
[-0.6623, -0.7308, -0.7308, …, -0.9192, -0.8849, -0.7308],
[-0.7137, -0.7137, -0.7479, …, -0.8678, -0.8164, -0.7650],
…,
[ 0.5707, 0.6392, 0.7248, …, 1.6495, 1.6495, 1.6667],
[ 0.5878, 0.6906, 0.8104, …, 1.5639, 1.5468, 1.6153],
[ 0.6734, 0.7591, 0.8447, …, 1.5810, 1.5125, 1.5982]],
[[-1.0378, -1.0553, -1.1078, ..., -1.0378, -1.2479, -1.1779],
[-1.0203, -1.0903, -1.1253, ..., -1.3880, -1.3004, -1.2129],
[-1.0553, -1.1078, -1.1954, ..., -1.3880, -1.3179, -1.2654],
...,
[ 0.2227, 0.2577, 0.3277, ..., 1.2731, 1.2906, 1.2906],
[ 0.2577, 0.2927, 0.3627, ..., 1.2206, 1.2556, 1.2381],
[ 0.3102, 0.3102, 0.3803, ..., 1.2031, 1.2031, 1.1856]],
[[-0.9504, -1.0376, -1.0376, ..., -0.9853, -1.2119, -1.1596],
[-0.8807, -0.9853, -1.0201, ..., -1.3513, -1.3164, -1.2293],
[-0.7936, -0.8633, -1.0027, ..., -1.4384, -1.3861, -1.3164],
...,
[ 0.3916, 0.4265, 0.5136, ..., 1.4200, 1.3851, 1.3502],
[ 0.4439, 0.4788, 0.5485, ..., 1.2805, 1.2631, 1.3677],
[ 0.5136, 0.5136, 0.5659, ..., 1.2631, 1.1411, 1.2108]]]]),
tensor([[2631, 1, 46, 8, 91, 56, 284, 8, 28, 420, 1, 681,
2632, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0],
[2631, 1, 120, 46, 130, 44, 54, 630, 2632, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0]]),
tensor([[13],
[ 9]])]
testdata[0].shape
torch.Size([2, 3, 256, 256])
testdata[1].shape
torch.Size([2, 52])
从上图中可以看出,训练集中包含三部分内容,一部分是图像本身的数据;一部分为最多包含52(max_caplength)个词汇的图像描述,不足用0填补,注意到最后有个2632代表end结束符,因此在翻译时要把字符串的长度统一减去一;一部分是描述语句的长度。
了解pack_padded_sequence函数和pad_packed_sequence函数
解码的时候,把作为最初的输入,直到输出为时停止,因此decoder的输出不包含最开始的,因此计算损失函数时target要从1开始截取。
imgs, caps, caplens = testdata[0], testdata[1], testdata[2]
imgs = encoder(imgs)
scores, caps_sorted, decode_lengths, alphas, sort_ind = decoder(imgs, caps, caplens)
#大小为(batch_size, max_sqe_length, vocab_size)
print(scores.shape)
scores
torch.Size([2, 12, 2633])
tensor([[[-6.3274e-02, 8.4856e-02, 3.5868e-01, ..., -1.6268e-01,
-1.7387e-01, -8.9078e-02],
[-6.0537e-02, 1.6019e-01, -3.8231e-02, ..., -8.6260e-02,
-6.0351e-02, -1.4645e-01],
[-7.0616e-02, 6.8983e-02, -2.7189e-02, ..., -6.2762e-02,
-2.8988e-03, -1.1590e-02],
...,
[ 4.3584e-02, 8.9589e-03, -1.9933e-02, ..., 3.2062e-03,
2.6120e-02, 3.2919e-03],
[-4.8098e-02, 8.9050e-03, 1.4572e-02, ..., -3.1682e-02,
3.8065e-02, -3.6008e-02],
[-6.8593e-03, -2.2740e-02, 2.4878e-02, ..., -6.2892e-03,
-1.0617e-03, -7.1017e-04]],
[[-2.0730e-01, 2.2974e-01, 2.0219e-01, ..., -1.4169e-01,
-1.6017e-01, 1.2114e-01],
[-3.7488e-02, 7.5987e-02, 2.8402e-02, ..., 3.7354e-02,
-1.2828e-01, -1.9194e-02],
[-7.1490e-02, 6.5804e-02, 2.9808e-02, ..., 1.0255e-04,
-1.0273e-02, 1.9436e-02],
...,
[ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00],
[ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00],
[ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00]]], grad_fn=)
#大小为(batch_size, max_length),由于输入恰好是按降序排列的,因此与输入的caps相同
print(caps_sorted.shape)
caps_sorted
torch.Size([2, 52])
tensor([[2631, 1, 46, 8, 91, 56, 284, 8, 28, 420, 1, 681,
2632, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0],
[2631, 1, 120, 46, 130, 44, 54, 630, 2632, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0]])
# 去除最后一位的即caps中的2632
decode_lengths
[12, 8]
sort_ind
tensor([0, 1])
targets = caps_sorted[:, 1:]
通过pack_padded_sequence将一个
填充过的变长了的序列进行紧压(pack)来去除冗余,其输入参数包括:
- embed_input_x是输入的被填充后的batch
- seq_lens是每个seq的长度
- batch_first=True表示input的形状是(batch_size, max_length, vocab_size)
scores = pack_padded_sequence(scores, decode_lengths, batch_first=True)
print(scores.data.shape)
scores
torch.Size([20, 2633])
PackedSequence(data=tensor([[-0.0633, 0.0849, 0.3587, ..., -0.1627, -0.1739, -0.0891],
[-0.2073, 0.2297, 0.2022, ..., -0.1417, -0.1602, 0.1211],
[-0.0605, 0.1602, -0.0382, ..., -0.0863, -0.0604, -0.1465],
...,
[ 0.0436, 0.0090, -0.0199, ..., 0.0032, 0.0261, 0.0033],
[-0.0481, 0.0089, 0.0146, ..., -0.0317, 0.0381, -0.0360],
[-0.0069, -0.0227, 0.0249, ..., -0.0063, -0.0011, -0.0007]],
grad_fn=), batch_sizes=tensor([2, 2, 2, 2, 2, 2, 2, 2, 1, 1, 1, 1]))
scores的前二维已被合并成一维,维数可以看做是decode_lengths之和,同时原来scores中的padding值0已经被消除,多出的batch_sizes可以看成是原来scores中第二维即seq_length在第一维即batch_size中竖着从上往下数不为padding值的个数。
targets = pack_padded_sequence(targets, decode_lengths, batch_first=True)
print(targets.data.shape)
targets
torch.Size([20])
PackedSequence(data=tensor([ 1, 1, 46, 120, 8, 46, 91, 130, 56, 44, 284, 54,
8, 630, 28, 2632, 420, 1, 681, 2632]), batch_sizes=tensor([2, 2, 2, 2, 2, 2, 2, 2, 1, 1, 1, 1]))
通过pad_packed_sequence将PackedSequence类型的数据转换为tensor类型,其输入参数包括:
- embed_input_x_packed,将要被填充的数据
- batch_first=True
scores, decode_lengths = pad_packed_sequence(scores, batch_first=True)
scores.shape
torch.Size([2, 12, 2633])
decode_lengths
tensor([12, 8])
可以看到,完美还原了原始的输入数据
对梯度进行clip操作
def clip_gradient(optimizer, grad_clip):
"""
Clips gradients computed during backpropagation to avoid explosion of gradients.
:param optimizer: optimizer with the gradients to be clipped
:param grad_clip: clip value
"""
for group in optimizer.param_groups:
for param in group["params"]:
if param.grad is not None:
param.grad.data.clamp_(-grad_clip, grad_clip)
epoch级别的训练函数
def train_epoch(train_loader, encoder, decoder, loss_fn,
encoder_optimizer, decoder_optimizer, epoch):
"""
Performs one epoch's training.
:param train_loader: DataLoader for training data
:param encoder: encoder model
:param decoder: decoder model
:param criterion: loss layer
:param encoder_optimizer: optimizer to update encoder's weights (if fine-tuning)
:param decoder_optimizer: optimizer to update decoder's weights
"""
encoder.train()
decoder.train()
# 自定义的AverageMeter类管理一些变量的更新。
#在初始化的时候就调用的重置方法reset。
#当调用该类对象的update方法的时候就会进行变量更新,当要读取某个变量的时候,可以通过对象.属性的方式来读取
losses = AverageMeter()
for idx, (imgs, caps, caplens) in enumerate(train_loader):
torch.cuda.empty_cache()
# Move to GPU, if available
imgs = imgs.to(device)
caps = caps.to(device)
caplens = caplens.to(device)
# Forward prop.
imgs = encoder(imgs)
scores, caps_sorted, decode_lengths, alphas, sort_ind = \
decoder(imgs, caps, caplens)
# Since we decoded starting with , the targets are all words after , up to
targets = caps_sorted[:, 1:]
# Remove timesteps that we didn't decode at, or are pads
# pack_padded_sequence is an easy trick to do this
#TODO
scores = pack_padded_sequence(scores, decode_lengths, batch_first=True)
targets = pack_padded_sequence(targets, decode_lengths, batch_first=True)
# 就相当于scores = scores.data
scores = scores[0]
targets = targets[0]
# Calculate loss
loss = loss_fn(scores, targets)
if alphas is not None:
loss += (1 - alphas.sum(dim=1) ** 2).mean()
# Back prop.
decoder_optimizer.zero_grad()
if encoder_optimizer is not None:
encoder_optimizer.zero_grad()
loss.backward()
# Clip gradients一定要放在step之前
if grad_clip is not None:
clip_gradient(decoder_optimizer, grad_clip)
if encoder_optimizer is not None:
clip_gradient(encoder_optimizer, grad_clip)
# Update weights
decoder_optimizer.step()
if encoder_optimizer is not None:
encoder_optimizer.step()
losses.update(loss.item(), sum(decode_lengths))
if idx % 100 == 0:
print(">>Epoch(Train): [{0}][{1}/{2}]\tLoss {loss.avg:.4f}".format
(epoch, idx, len(train_loader), loss=losses))
epoch级别的评估函数
def eval_epoch(val_loader, encoder, decoder, loss_fn, epoch):
"""
Performs one epoch's validation.
:param val_loader: DataLoader for validation data.
:param encoder: encoder model
:param decoder: decoder model
:param criterion: loss layer
"""
decoder.eval()
encoder.eval()
losses = AverageMeter()
with torch.no_grad():
for idx, (imgs, caps, caplens, allcaps) in enumerate(val_loader):
torch.cuda.empty_cache()
# Move to device, if available
imgs = imgs.to(device)
caps = caps.to(device)
caplens = caplens.to(device)
# Forward prop.
imgs = encoder(imgs)
scores, caps_sorted, decode_lengths, alphas, sort_ind = \
decoder(imgs, caps, caplens)
# Since we decoded starting with , the targets are all
# words after , up to
targets = caps_sorted[:, 1:]
scores = pack_padded_sequence(scores, decode_lengths, batch_first=True)
targets = pack_padded_sequence(targets, decode_lengths, batch_first=True)
scores = scores[0]
targets = targets[0]
# Calculate loss
loss = loss_fn(scores, targets)
if alphas is not None:
loss += (1 - alphas.sum(dim=1) ** 2).mean()
losses.update(loss.item(), sum(decode_lengths))
if idx % 100== 0:
print(">>Epoch(Eval): [{epoch}][{idx}/{iters}]\tLoss {loss.avg:.4f}".format(
epoch=epoch, idx=idx, iters=len(val_loader),
loss=losses))
def run(encoder, decoder):
"""Main function to run"""
encoder_lr = 1e-4 # learning rate for encoder if fine-tuning
decoder_lr = 4e-4 # learning rate for decoder
encoder_optimizer = torch.optim.Adam(encoder.parameters(), lr=encoder_lr)
decoder_optimizer = torch.optim.Adam(decoder.parameters(), lr=decoder_lr)
encoder = encoder.to(device)
decoder = decoder.to(device)
loss_fn = nn.CrossEntropyLoss().to(device)
train_loader, val_loader = dataset.get_dataloader()
for epoch in range(n_epochs):
train_epoch(train_loader, encoder, decoder, loss_fn,
encoder_optimizer, decoder_optimizer, epoch)
eval_epoch(val_loader, encoder, decoder, loss_fn, epoch)
# Run your code
batch_size = 2
n_epochs = 5
embed_dim = 512 # dimension of word embeddings
decoder_dim = 512 # dimension of decoder RNN
dropout = 0.5
grad_clip = 5
encoder = Encoder()
decoder = Decoder(embed_dim=embed_dim,
decoder_dim=decoder_dim,
vocab_size=len(word_map),
dropout=dropout)
run(encoder, decoder)
Downloading: "https://download.pytorch.org/models/resnet101-5d3b4d8f.pth" to /home/jovyan/.torch/models/resnet101-5d3b4d8f.pth
100.0%
>>Epoch(Train): [0][0/250] Loss 7.8655
>>Epoch(Train): [0][100/250] Loss 5.8830
>>Epoch(Train): [0][200/250] Loss 5.4569
>>Epoch(Eval): [0][0/250] Loss 4.3891
>>Epoch(Eval): [0][100/250] Loss 4.7746
>>Epoch(Eval): [0][200/250] Loss 4.7747
>>Epoch(Train): [1][0/250] Loss 4.1016
>>Epoch(Train): [1][100/250] Loss 4.5317
>>Epoch(Train): [1][200/250] Loss 4.5297
>>Epoch(Eval): [1][0/250] Loss 4.1637
>>Epoch(Eval): [1][100/250] Loss 4.5952
>>Epoch(Eval): [1][200/250] Loss 4.5721
>>Epoch(Train): [2][0/250] Loss 4.4086
>>Epoch(Train): [2][100/250] Loss 4.1621
>>Epoch(Train): [2][200/250] Loss 4.1592
>>Epoch(Eval): [2][0/250] Loss 3.8804
>>Epoch(Eval): [2][100/250] Loss 4.3713
>>Epoch(Eval): [2][200/250] Loss 4.3962
>>Epoch(Train): [3][0/250] Loss 4.3024
>>Epoch(Train): [3][100/250] Loss 3.8419
>>Epoch(Train): [3][200/250] Loss 3.8291
>>Epoch(Eval): [3][0/250] Loss 4.4523
>>Epoch(Eval): [3][100/250] Loss 4.2866
>>Epoch(Eval): [3][200/250] Loss 4.2494
>>Epoch(Train): [4][0/250] Loss 3.9095
>>Epoch(Train): [4][100/250] Loss 3.5927
>>Epoch(Train): [4][200/250] Loss 3.5962
>>Epoch(Eval): [4][0/250] Loss 4.3887
>>Epoch(Eval): [4][100/250] Loss 4.2208
>>Epoch(Eval): [4][200/250] Loss 4.2522
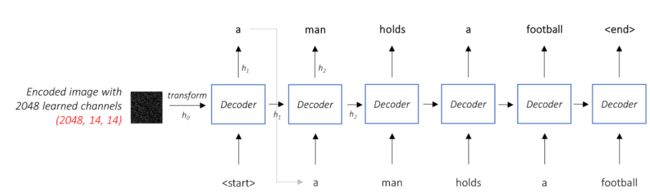
引入注意力机制
Whole picture of the model

Soft attention原理及实现
Attention
The Attention network computes these weights.
Intuitively, how would you estimate the importance of a certain part of an image? You would need to be aware of the sequence you have generated so far, so you can look at the image and decide what needs describing next. For example, after you mention a man, it is logical to declare that he is holding a football.

This is exactly what the Attention mechanism does – it considers the sequence generated thus far, and attends to the part of the image that needs describing next.
本质上是对每个像素分配权重
We will use soft Attention, where the weights of the pixels add up to 1. If there are P pixels in our encoded image, then at each timestep t –

The Attention network is simple – it’s composed of only linear layers and a couple of activations.
Separate linear layers transform both the encoded image (flattened to N, 14 * 14, 2048) and the hidden state (output) from the Decoder to the same dimension, viz. the Attention size. They are then added and ReLU activated. A third linear layer transforms this result to a dimension of 1, whereupon we apply the softmax to generate the weights alpha.
Attention
class Attention(nn.Module):
"""Attention Network
"""
def __init__(self, encoder_dim, decoder_dim, attention_dim):
"""
:param encoder_dim: feature size of encoded images
:param decoder_dim: size of decoder's RNN
:param attention_dim: size of the attention network
"""
super(Attention, self).__init__()
# linear layer to transform encoded image
self.encoder_att = nn.Linear(encoder_dim, attention_dim)
# linear layer to transform decoder's output
self.decoder_att = nn.Linear(decoder_dim, attention_dim)
# linear layer to calculate values to be softmax-ed
self.full_att = nn.Linear(attention_dim, 1)
self.relu = nn.ReLU()
# softmax layer to calculate weights
self.softmax = nn.Softmax(dim=1)
def forward(self, encoder_out, decoder_hidden):
"""
Forward propagation.
:param encoder_out: encoded images, a tensor of dimension
(batch_size, num_pixels, encoder_dim)
:param decoder_hidden: previous decoder output, a tensor of dimension
(batch_size, decoder_dim)
:return: attention weighted encoding, weights
"""
# (batch_size, num_pixels, attention_dim)
att1 = self.encoder_att(encoder_out)
# (batch_size, attention_dim)
att2 = self.decoder_att(decoder_hidden)
# (batch_size, num_pixels)
att = self.full_att(self.relu(att1 + att2.unsqueeze(1))).squeeze(2)
# (batch_size, num_pixels)
alpha = self.softmax(att)
# (batch_size, num_pixels, encoder_dim)*(batch_size, num_pixels, 1) = (batch_size, num_pixels, encoder_dim)
# (batch_size, encoder_dim)
attention_weighted_encoding = (encoder_out * alpha.unsqueeze(2)).sum(dim=1)
return attention_weighted_encoding, alpha
矩阵相乘test(理解上面的encoder_out * alpha.unsqueeze(2))
x = torch.randint(1, 4, [2,3,4])
y = torch.randint(1, 4, [2,3,1])
x
tensor([[[2, 1, 2, 1],
[1, 3, 3, 1],
[2, 3, 2, 2]],
[[3, 2, 2, 2],
[1, 1, 3, 3],
[2, 3, 3, 2]]])
y
tensor([[[3],
[3],
[1]],
[[1],
[2],
[1]]])
z = x*y
print(z.shape)
z
torch.Size([2, 3, 4])
tensor([[[6, 3, 6, 3],
[3, 9, 9, 3],
[2, 3, 2, 2]],
[[3, 2, 2, 2],
[2, 2, 6, 6],
[2, 3, 3, 2]]])
从上面的小实验里可以看得出来,当两个维度不一致的矩阵按位相乘时,会将较小维度(注意这个小维度必须得是1)的矩阵进行扩充,结果与大矩阵的维度一致。
引入attention的解码器
class DecoderWithAttention(nn.Module):
"""Decoder with attention
"""
def __init__(self, attention_dim, embed_dim, decoder_dim, vocab_size,
encoder_dim=2048, dropout=0.5):
"""
:param attention_dim: size of attention network
:param embed_dim: embedding size
:param decoder_dim: size of decoder's RNN
:param vocab_size: size of vocabulary
:param encoder_dim: feature size of encoded images
:param dropout: dropout
"""
super(DecoderWithAttention, self).__init__()
self.encoder_dim = encoder_dim
self.decoder_dim = decoder_dim
self.attention_dim = attention_dim
self.embed_dim = embed_dim
self.vocab_size = vocab_size
self.dropout = dropout
# Attention network, simple MLP
self.attention = Attention(encoder_dim, decoder_dim, attention_dim)
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.dropout = nn.Dropout(p=self.dropout)
# Different with Decoder defined above
self.decode_step = nn.LSTMCell(embed_dim + encoder_dim, decoder_dim)
self.init_h = nn.Linear(encoder_dim, decoder_dim)
self.init_c = nn.Linear(encoder_dim, decoder_dim)
self.f_beta = nn.Linear(decoder_dim, encoder_dim)
self.sigmoid = nn.Sigmoid()
self.fc = nn.Linear(decoder_dim, vocab_size)
# initialize some layers with the uniform distribution
self.init_weights()
def init_weights(self):
"""
Initializes some parameters with values from the uniform distribution, for easier convergence.
"""
self.embedding.weight.data.uniform_(-0.1, 0.1)
self.fc.bias.data.fill_(0)
self.fc.weight.data.uniform_(-0.1, 0.1)
def init_hidden_state(self, encoder_out):
"""
Creates the initial hidden and cell states for the decoder's LSTM based on the encoded images.
:param encoder_out: encoded images, a tensor of dimension (batch_size, num_pixels, encoder_dim)
:return: hidden state, cell state
"""
mean_encoder_out = encoder_out.mean(dim=1)
# (batch_size, decoder_dim)
h = self.init_h(mean_encoder_out)
c = self.init_c(mean_encoder_out)
return h, c
def forward(self, encoder_out, encoded_captions, caption_lengths):
"""
Forward propagation.
:param encoder_out: encoded images, a tensor of dimension (batch_size, enc_image_size, enc_image_size, encoder_dim)
:param encoded_captions: encoded captions, a tensor of dimension (batch_size, max_caption_length)
:param caption_lengths: caption lengths, a tensor of dimension (batch_size, 1)
:return: scores for vocabulary, sorted encoded captions, decode lengths, weights, sort indices
"""
batch_size = encoder_out.size(0)
encoder_dim = encoder_out.size(-1)
vocab_size = self.vocab_size
device = encoder_out.device
# Flatten image
encoder_out = encoder_out.view(batch_size, -1, encoder_dim)
num_pixels = encoder_out.size(1)
# Sort input data by decreasing lengths; why? apparent below
caption_lengths, sort_ind = caption_lengths.squeeze(1).sort(dim=0, descending=True)
encoder_out = encoder_out[sort_ind]
encoded_captions = encoded_captions[sort_ind]
# Embedding
embeddings = self.embedding(encoded_captions)
# Initialize LSTM state
h, c = self.init_hidden_state(encoder_out)
# We won't decode at the position, since we've finished generating as soon as we generate
# So, decoding lengths are actual lengths - 1
decode_lengths = (caption_lengths - 1).tolist()
# Create tensors to hold word predicion scores and alphas
predictions = torch.zeros(batch_size, max(decode_lengths), vocab_size).to(device)
# alphas的含义是每句话解码的每个step所依赖的图像的重点区域,alpha和alphas在下面的计算中其实没有具体用到
# 唯一的作用也就是去画成图,形象化地展示一下
alphas = torch.zeros(batch_size, max(decode_lengths), num_pixels).to(device)
# At each time-step, decode by
# attention-weighing the encoder's output based on the decoder's previous hidden state output
# then generate a new word in the decoder with the previous word and the attention weighted encoding
for t in range(max(decode_lengths)):
batch_size_t = sum([l > t for l in decode_lengths])
attention_weighted_encoding, alpha = self.attention(
encoder_out[:batch_size_t], h[:batch_size_t])
# Gating scalar, (batch_size_t, encoder_dim)
gate = self.sigmoid(self.f_beta(h[:batch_size_t]))
# 前者感觉可以看做是语义权重,后者可以看做是视觉权重
attention_weighted_encoding = gate * attention_weighted_encoding
h, c = self.decode_step(
torch.cat([embeddings[:batch_size_t, t, :],
attention_weighted_encoding], dim=1),
(h[:batch_size_t], c[:batch_size_t]))
preds = self.fc(self.dropout(h))
predictions[:batch_size_t, t, :] = preds
alphas[:batch_size_t, t, :] = alpha
return predictions, encoded_captions, decode_lengths, alphas, sort_ind
# Run your code
batch_size = 2
n_epochs = 5
embed_dim = 512 # dimension of word embeddings
decoder_dim = 512 # dimension of decoder RNN
attention_dim = 512
dropout = 0.5
grad_clip = 5
dataset = Dataset(batch_size = 2)
word_map = dataset.get_word_map()
rev_word_map = dataset.get_rev_word_map()
encoder = Encoder()
decoder = DecoderWithAttention(
attention_dim=attention_dim,
embed_dim=embed_dim,
decoder_dim=decoder_dim,
vocab_size=len(word_map),
dropout=dropout)
run(encoder, decoder)
>>Epoch(Train): [0][0/250] Loss 8.9114
>>Epoch(Train): [0][100/250] Loss 6.0963
>>Epoch(Train): [0][200/250] Loss 5.8183
>>Epoch(Eval): [0][0/250] Loss 5.2436
>>Epoch(Eval): [0][100/250] Loss 5.3373
>>Epoch(Eval): [0][200/250] Loss 5.3380
>>Epoch(Train): [1][0/250] Loss 5.2668
>>Epoch(Train): [1][100/250] Loss 5.1481
>>Epoch(Train): [1][200/250] Loss 5.1250
>>Epoch(Eval): [1][0/250] Loss 6.4294
>>Epoch(Eval): [1][100/250] Loss 5.1621
>>Epoch(Eval): [1][200/250] Loss 5.2236
>>Epoch(Train): [2][0/250] Loss 4.6826
>>Epoch(Train): [2][100/250] Loss 4.8658
>>Epoch(Train): [2][200/250] Loss 4.8693
>>Epoch(Eval): [2][0/250] Loss 7.0310
>>Epoch(Eval): [2][100/250] Loss 5.0797
>>Epoch(Eval): [2][200/250] Loss 5.0532
>>Epoch(Train): [3][0/250] Loss 5.5336
>>Epoch(Train): [3][100/250] Loss 4.6897
>>Epoch(Train): [3][200/250] Loss 4.7051
>>Epoch(Eval): [3][0/250] Loss 5.1410
>>Epoch(Eval): [3][100/250] Loss 5.0357
>>Epoch(Eval): [3][200/250] Loss 4.9734
>>Epoch(Train): [4][0/250] Loss 4.6166
>>Epoch(Train): [4][100/250] Loss 4.5629
>>Epoch(Train): [4][200/250] Loss 4.5261
>>Epoch(Eval): [4][0/250] Loss 6.5371
>>Epoch(Eval): [4][100/250] Loss 4.8869
>>Epoch(Eval): [4][200/250] Loss 4.8346
Beam Search
We use a linear layer to transform the Decoder’s output into a score for each word in the vocabulary.
The straightforward – and greedy – option would be to choose the word with the highest score and use it to predict the next word. But this is not optimal because the rest of the sequence hinges on that first word you choose. If that choice isn’t the best, everything that follows is sub-optimal. And it’s not just the first word – each word in the sequence has consequences for the ones that succeed it.
It might very well happen that if you’d chosen the third best word at that first step, and the second best word at the second step, and so on… that would be the best sequence you could generate.
It would be best if we could somehow not decide until we’ve finished decoding completely, and choose the sequence that has the highest overall score from a basket of candidate sequences.
Beam Search does exactly this.
At the first decode step, consider the top k candidates.
Generate k second words for each of these k first words.
Choose the top k [first word, second word] combinations considering additive scores.
For each of these k second words, choose k third words, choose the top k [first word, second word, third word] combinations.
Repeat at each decode step.
After k sequences terminate, choose the sequence with the best overall score.
本质上就是个深搜

As you can see, some sequences (striked out) may fail early, as they don’t make it to the top k at the next step. Once k sequences (underlined) generate the token, we choose the one with the highest score.