概述
最近在看Netty的源码,关注了下其队列的实现;Netty中基于不同的IO模型,提供了不同的线程实现:
- BIO:ThreadPerChannelEventLoop
每个Channel一个线程,采用的队列为LinkedBlockingQueue - NIO:NioEventLoop(水平触发)
每个线程一个Selector,可以注册多个Channel,采用的队列为MpscChunkedArrayQueue或MpscLinkedAtomicQueue - Epoll:EpollEventLoop(边缘触发)
和2相同
那为什么要采用不同的Queue实现呢?下面看看不同Queue的具体实现;
LinkedBlockingQueue
LinkedBlockingQueue是JDK提供的,采用链表存储数据,通过ReentrantLock和Condition来解决竞争和支持堵塞;
既然采用链表,铁定要定义一个新的节点类,在LinkedBlockingQueue中这个节点类为:
static class Node {
E item;
Node next;
Node(E x) { item = x;}
}
可以看到实现很简单,采用单向链接,通过next指向下一个节点,如果next为null,表示该节点为尾节点;
LinkedBlockingQueue的成员变量为:
//容量,队列是和ArrayList不同,有容量限制
private final int capacity;
//当前节点数量
private final AtomicInteger count = new AtomicInteger(0);
//头节点
private transient Node head;
//尾节点
private transient Node last;
//出列锁,当从队列取数据时,要先获取该锁
private final ReentrantLock takeLock = new ReentrantLock();
//队列非空条件变量,当队列为空时,出列线程要等待该条件变量
private final Condition notEmpty = takeLock.newCondition();
//入列锁,当往队列添加数据时,要先获取该锁
private final ReentrantLock putLock = new ReentrantLock();
//队列容量未满条件变量,当队列满了,入列线程要等待该条件变量
private final Condition notFull = putLock.newCondition();
从上面的成员变量大概可以看出:
- 可以设置容量,但未提供初始容量、最大容量之类的特性;
- 先入先出队列,入列和出列都要获取锁,因此是线程安全的;
- 入列和出列分为两个锁;
以其中的入列offer方法为例(由于netty中使用的是Queue而不是BlockingQueue,因此此处分析的都是非堵塞的方法):
public boolean offer(E e) {
if (e == null) throw new NullPointerException();//参数非空
final AtomicInteger count = this.count;//队列元素数量
if (count.get() == capacity)//队列已满,无法添加,返回false
return false;
int c = -1;
Node node = new Node(e);//将元素封装为节点
final ReentrantLock putLock = this.putLock;
putLock.lock();//获取锁,所有入列操作共有同一个锁
try {
if (count.get() < capacity) {//只有队列不满,才能添加
enqueue(node);//入列
c = count.getAndIncrement();
if (c + 1 < capacity)//如果添加元素之后,队列仍然不满,notFull条件变量满足条件,通知排队等待的线程
notFull.signal();
}
} finally {
putLock.unlock();//释放锁
}
if (c == 0)
signalNotEmpty();//说明之前队列为空,因此需要出发非空条件变量
return c >= 0;
}
ArrayBlockingQueue
顾名思义,ArrayBlockingQueue是采用数组存储数据的;它的成员变量如下:
//数组,用于存储数据
final Object[] items;
//ArrayBlockingQueue维护了两个索引,一个用于出列,一个用于入列
int takeIndex;
int putIndex;
//当前队列的元素数量
int count;
//可重入锁
final ReentrantLock lock;
//队列容量非空条件变量,当队列空了,出列线程要等待该条件变量
private final Condition notEmpty;
//队列容量未满条件变量,当队列满了,入列线程要等待该条件变量
private final Condition notFull;
从上面可出:
- 入列和出列采用同一个锁,也就是说入列和出列会彼此竞争锁;
- 采用索引来记录当前出列和入列的位置,避免了移动数组元素;
- 基于以上2点,在高并发的情况下,由于锁竞争,性能应该比不上链表的实现;
MpscChunkedArrayQueue
MpscChunkedArrayQueue也是采用数组来实现的,从名字上可以看出它是支持多生产者单消费者( Multi Producer Single Consumer),和前面的两种队列使用场景有些差异;但恰好符合netty的使用场景;它对特定场景进行了优化:
- CacheLine Padding
LinkedBlockingQueue的head和last是相邻的,ArrayBlockingQueue的takeIndex和putIndex是相邻的;而我们都知道CPU将数据加载到缓存实际上是按照缓存行加载的,因此可能出现明明没有修改last,但由于出列操作修改了head,导致整个缓存行失效,需要重新进行加载;
//此处我将多个类中的变量合并到了一起,便于查看
long p01, p02, p03, p04, p05, p06, p07;
long p10, p11, p12, p13, p14, p15, p16, p17;
protected long producerIndex;
long p01, p02, p03, p04, p05, p06, p07;
long p10, p11, p12, p13, p14, p15, p16, p17;
protected long maxQueueCapacity;
protected long producerMask;
protected E[] producerBuffer;
protected volatile long producerLimit;
protected boolean isFixedChunkSize = false;
long p0, p1, p2, p3, p4, p5, p6, p7;
long p10, p11, p12, p13, p14, p15, p16, p17;
protected long consumerMask;
protected E[] consumerBuffer;
protected long consumerIndex;
可以看到生产者索引和消费者索引中间padding了18个long变量,18*8=144,而一般操作系统的cacheline为64,可以通过如下方式查看缓存行大小:
cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size
减少锁的使用,使用CAS+自旋:
由于使用锁会造成线程切换,消耗资源;因此MpscChunkedArrayQueue并未使用锁,而是使用自旋;和Disruptor的BusySpinWaitStrategy比较类似,如果系统比较繁忙,自旋效率会很适合;当然它也会造成CPU使用率比较高,所以建议使用时将这些线程绑定到特定的CPU;支持扩容;
MpscChunkedArrayQueue采用数组作为内部存储结构,那么它是如何实现扩容的呢?可能大家第一反应想到的是创建新数组,然后将老数据挪到新数组中去;但MpscChunkedArrayQueue采用了一种独特的方式,避免了数组的复制;
举例说明:
假设队列的初始化大小为4,则初始的buffer数组为4+1;为什么要+1呢?因为最后一个元素需要存储下一个buffer的指针;假设队列中存储了8个元素,则数组的内容如下:
- buffer
| 数组下标 | 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|---|
| 内容 | e0 | e1 | e2 | JUMP | next[5] |
- next
| 数组下标 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|
| 内容 | e4 | e5 | JUMP | e3 | next |
可以看到,每个buffer数组的大小都是固定的(之前的版本支持固定大小和非固定大小),也就是initialCapacity指定的大小;每个数组的最后一个实际保存的是个指针,指向下一个数组;读取数据时,如果遇到JUMP表示要从下一个buffer数组读取数据;
public E poll() {//消费队列元素
final E[] buffer = consumerBuffer;
final long index = consumerIndex;
final long mask = consumerMask;
//通过Unsafe.getObjectVolatile(E[] buffer, long offset)获取数组元素
//因此需要根据数组索引,计算出在内存中的偏移量
final long offset = modifiedCalcElementOffset(index, mask);
Object e = lvElement(buffer, offset);
if (e == null) {
//e==null并不一定表示队列为空,因为入列的时候是先更新producerIndex,后更新数组元素,因此需要判断producerIndex
if (index != lvProducerIndex()) {
//采用自旋,直到获取到数据
do {
e = lvElement(buffer, offset);
} while (e == null);
}
else {
return null;
}
}
if (e == JUMP) {//跳转到新的buff寻找
final E[] nextBuffer = getNextBuffer(buffer, mask);
return newBufferPoll(nextBuffer, index);
}
//从队列中取出数据之后,将数组对应位置元素清除
soElement(buffer, offset, null);
soConsumerIndex(index + 2);
return (E) e;
}
性能对比
从网上找了一份测试代码,稍做修改:
public class TestQueue {
private static int PRD_THREAD_NUM;
private static int C_THREAD_NUM=1;
private static int N = 1<<20;
private static ExecutorService executor;
public static void main(String[] args) throws Exception {
System.out.println("Producer\tConsumer\tcapacity \t LinkedBlockingQueue \t ArrayBlockingQueue \t MpscLinkedAtomicQueue \t MpscChunkedArrayQueue \t MpscArrayQueue");
for (int j = 1; j < 8; j++) {
PRD_THREAD_NUM = (int) Math.pow(2, j);
executor = Executors.newFixedThreadPool(PRD_THREAD_NUM * 2);
for (int i = 9; i < 12; i++) {
int length = 1<< i;
System.out.print(PRD_THREAD_NUM + "\t\t");
System.out.print(C_THREAD_NUM + "\t\t");
System.out.print(length + "\t\t");
System.out.print(doTest2(new LinkedBlockingQueue(length), N) + "/s\t\t");
System.out.print(doTest2(new ArrayBlockingQueue(length), N) + "/s\t\t");
System.out.print(doTest2(new MpscLinkedAtomicQueue(), N) + "/s\t\t");
System.out.print(doTest2(new MpscChunkedArrayQueue(length), N) + "/s\t\t");
System.out.print(doTest2(new MpscArrayQueue(length), N) + "/s");
System.out.println();
}
executor.shutdown();
}
}
private static class Producer implements Runnable {
int n;
Queue q;
public Producer(int initN, Queue initQ) {
n = initN;
q = initQ;
}
public void run() {
while (n > 0) {
if (q.offer(n)) {
n--;
}
}
}
}
private static class Consumer implements Callable {
int n;
Queue q;
public Consumer(int initN, Queue initQ) {
n = initN;
q = initQ;
}
public Long call() {
long sum = 0;
Integer e = null;
while (n > 0) {
if ((e = q.poll()) != null) {
sum += e;
n--;
}
}
return sum;
}
}
private static long doTest2(final Queue q, final int n)
throws Exception {
CompletionService completionServ = new ExecutorCompletionService<>(executor);
long t = System.nanoTime();
for (int i = 0; i < PRD_THREAD_NUM; i++) {
executor.submit(new Producer(n / PRD_THREAD_NUM, q));
}
for (int i = 0; i < C_THREAD_NUM; i++) {
completionServ.submit(new Consumer(n / C_THREAD_NUM, q));
}
for (int i = 0; i < 1; i++) {
completionServ.take().get();
}
t = System.nanoTime() - t;
return (long) (1000000000.0 * N / t); // Throughput, items/sec
}
}
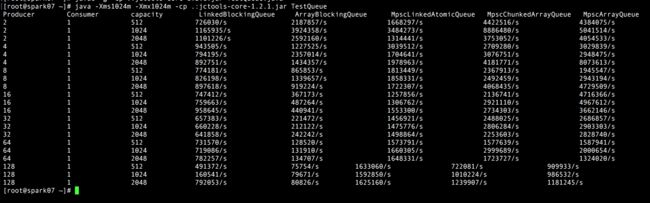
从上面可以看到:
- Mpsc*Queue表现最好,而且性能表现也最稳定;
- 并发数较低的时候,基于数组的队列比基于链表的队列表现要好,,推测有可能是因为数组在内存中是连续分配的,因此加载的时候可以有效利用缓存行,减少读的次数;而链表在内存的地址不是连续的,随机读代价比较大;
- 并发数较高的时候,基于链表的队列比基于数组的队列表现要好;LinkedBlockingQueue因为入列和出列采用不同的锁,因此锁竞争应该比ArrayBlockingQueue小;而MpscLinkedAtomicQueue没有容量限制,使用AtomicReference提供的XCHG功能修改链接即可达到出列和入列的目的,效率特别高;
- MpscChunkedArrayQueue相对于MpscArrayQueue,提供了动态扩容大能力;