CVPR2018论文笔记(四)PPFNet_Part4
本周主要读(yì)了第五部分Results的内容。
5.Results##
(1)Setup
Our input encoding uses a 17-point neighborhood to compute the normals for the entire scene, using the well accepted plane fitting [18]. For each fragment, we anchor 2048 sample points distributed with spatial uniformity. These sample points act as keypoints and within their 30cm vicinity, they form the patch, from which we compute the local PPF encoding. Similarly, we down-sample the points within each patch to 1024 to facilitate the training as well as to increase the robustness of features to various point density and missing part. For occasional patches with insufficient points in the defined neighborhood, we randomly repeat points to ensure identical patch size. PPFNet extracts compact descriptors of dimension 64.
我们的输入编码利用由17个点的邻域作为整个场景来计算法线,利用公认的平面拟合。对于每个片段,我们锚定2048个具有分布均匀性的样本点。这些样本点作为关键点,并且在它们的30cm附近形成贴片,从中我们计算局部PPF编码。类似地,我们降采样每个贴片的点为1024,以便训练,同样增强特征对各种点密度和确实部分的鲁棒性。对于包含定义的邻域中点不足的偶然的贴片,我们随机重复点来确保相同的贴片大小。PPFNet提取64维度紧凑的描述符。
PPFNet is implemented in the popular Tensorflow [1]. The initialization uses random weights and ADAM [25] optimizer minimizes the loss. Our network operates simultaneously on all 2048 patches. Learning rate is set at 0.001 and exponentially decayed after every 10 epochs until 0.00001. Due to the hardware constraints, we use a batch size of 2 fragment pairs per iteration, containing 8192 local patches from 4 fragments already. This generates 2×20482 combinations for the network per batch.
PPFNet是在流行的Tensorflow中实现的。初始化利用随机宽度和ADAM优化程序缩小损失。我们同时在全部2048个贴片上运行网络。学习率设置为0.001并且以指数方式在每10历元衰减为0.00001。由于硬件条件的限制,我们每次迭代使用2个片段对的批处理大小,包含来自4个片段的8129个局部贴片。这就使每批网络产生2×2048x2048个组合。
(2)Real Datasets
We concentrate on real sets rather than synthetic ones and therefore our evaluations are against the diverse 3DMatch RGBD benchmark [48], in which 62 different real-world scenes retrieved from the pool of datasets Analysis-by-Synthesis [42], 7-Scenes [38], SUN3D [46], RGB-D Scenes v.2 [27] and Halber et [15]. This collection is split into 2 subsets, 54 for training and validation, 8 for testing. The dataset typically includes indoor scenes like living rooms, offices, bedrooms, tabletops, and restrooms. See [48] for details. As our input consists of only point geometry, we solely use the fragment reconstructions captured by Kinect sensor and not the color.
我们专注于真实的集合而不是合成集合,因此我们的评估是针对不同的3DMatch RGBD基准,其中从数据集Analysis-by-Synthesis [42], 7-Scenes [38], SUN3D [46], RGB-D Scenes v.2 [27] ,Halber et [15]的池中检索了62个不同的真实世界场景。这些集合分为2个子集,54个用来训练和验证,8个用来测试。数据集通常包括室内场景比如客厅、办公室、我是、桌面和洗手间。详情参考[48]。因为我们的输入只包括点几何,我们只通过Kinect传感器捕获片段进行重建,而不使用颜色特征。
(3)Can PPFNet outperform the baselines on real data?
We evaluate our method against hand-crafted baselines of Spin Images [21], SHOT [37], FPFH [34], USC [41], as well as 3DMatch [48], the state of the art deep learning based 3D local feature descriptor, the vanilla PointNet [30] and CGF [23], a hybrid hand-crafted and deep descriptor designed for compactness. To set the experiments more fair, we also show a version of 3DMatch, where we use 2048 local patches per fragment instead of 5K, the same as in our method, denoted as 3DMatch-2K. We use the provided pretrained weights of CGF [23]. We keep the local patch size same for all methods. Our evaluation data consists of fragments from 7-scenes [38] and SUN3D [46] datasets. We begin by showing comparisons without applying RANSAC to prune the false matches. We believe that this can show the true quality of the correspondence estimator. Inspired by [23], we accredit recall as a more effective measure for this experiment, as the precision can always be improved by better corresponding pruning [5, 4]. Our evaluation metric directly computes the recall by averaging the number of matched fragments across the datasets:
我们针对Spin Images [21], SHOT [37], FPFH [34], USC [41], 3DMatch [48] ,基于3D局部特征描述符的深度学习技术发展水平,基本的PointNet和CGF的手工基准线来评估我们的方法,设计一个混合手工和深度描述符用来使得描述符变得紧凑。为了让实验变得更公平,我们同样展示了一个3DMatch的版本,其中每个片段我们用2048个局部贴片而不是5000个,这和我们的3DMatch-2K的方法相同。我们使用CGF[23]所提供的预训练权值。我们让所有方法保持相同的局部贴片大小。我们的评估数据来自7-scenes和SUN3D数据集。我们通过显示比较来开始,而不是应用RANSAC减少错误匹配。我们相信,这可以显示对应估计的真实质量。受到[23]的启发,我们认可召回率作为本次实验更有效的方式,因为通过更好的对应减少总可以提升精度。我们的评估度量直接通过平均数据集中匹配片段的数目来计算召回率:
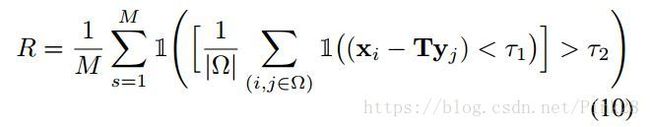
where M is the number of ground truth matching fragment pairs, having at least 30% overlap with each other under ground-truth transformation T and τ1 = 10cm. (i, j) denotes an element of the found correspondence set Ω. x and y respectively come from the first and second fragment under matching. The inlier ratio is set as τ2 = 0.05. As seen from Tab. 1, PPFNet outperforms all the hand crafted counterparts in mean recall. It also shows consistent advantage over 3DMatch-2K, using an equal amount of patches. Finally and remarkably, we are able to show ∼ 2.7% improvement on mean recall over the original 3DMatch, using only ∼ 40% of the keypoints for matching. The performance boost from 3DMatch-2K to 3DMatch also indicates that having more keypoints is advantageous for matching.
其中,M是地面真实匹配片段对的真实数量,和彼此地面真值变换T和τ1 = 10cm下有至少30%的重叠。(i, j)表示找到的对应集合Ω中的一个元素。x 和 y分别来自于匹配下的第一个和第二个片段。内径比设置为τ2 = 0.05。正如表1中所看到的,PPFNet在平均召回率上优于所有手工选择的同类方法。它同样显示比3DMatch-2K更具有相容的优势,利用相等数量的蹄片。最后也是值得注意的是,相比于原始的3DMatch,我们在平均召回率上可以显示大约2.7%的提升,仅用40%的关键点进行比配。从3DMatch-2K到3DMatch的性能提升也表明,有更多的关键点对于匹配也是有益的。

表1 我们在RANSAC之前对三维匹配基准进行的评估。
【RANSAC】关于RANSAC算法的介绍https://www.cnblogs.com/weizc/p/5257496.html。
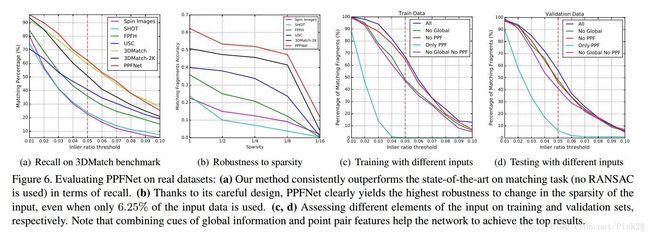
Our method expectedly outperforms both vanilla PointNet and CGF by 15%. We show in Tab. 2 that adding more samples brings benefit, but only up to a certain level (< 5K). For PPFNet, adding more samples also increases the global context and thus, following the advent in hardware, we have the potential to further widen the performance gap over 3DMatch, by simply using more local patches. To show that we do not cherry-pick τ2 but get gains, we also plot the recall computed with the same metric for different inlier ratios in Fig. 6(a). There, for the practical choices of τ2, PPFNet persistently remains above all others.
我们的方法预期优于基本的PointNet和CGF15%。我们在表2中显示增加更多的样本会带来益处,但是仅达到一定水平(<5K)。对PPFNet,增加更多的样本,也会增加全局背景,因此,随着硬件的出现,我们有可能通过单纯地使用更多的局部贴片进一步扩大与3DMatch的性能差距。为了显示上述内容我们没有优选τ2但是得到连续的收益,我们也在图6中画出了为不同的内径比采用相同度量计算召回率。在这里,对于τ2的实际选择,PPFNet始终保持在其他之上。
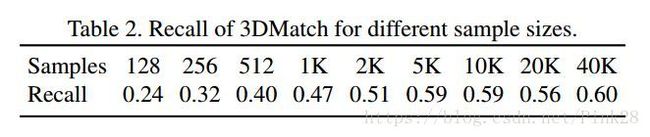
样本越大,召回率越高
(4)Application to geometric registration
Similar to [48], we now use PPFNet in a broader context of transformation estimation. To do so, we plug all descriptors into the well established RANSAC based matching pipeline, in which the transformation between fragments is estimated by running a maximum of 50,000 RANSAC iterations on the initial correspondence set. We then transform the source cloud to the target by estimated 3D pose and compute the point-to-point error. This is a well established error metric [48]. Tab. 3 tabulates the results on the real datasets. Overall, PPFNet is again the top performer, while showing higher recall on a majority of the scenes and on the average. It is noteworthy that we always use 2048 patches, while allowing 3DMatch to use its original setting, 5K. Even so, we could get better recall on more than half of the scenes. When we feed 3DMatch 2048 patches, to be on par with our sampling level, PPFNet dominates performance-wise on most scenes with higher average accuracy.
和[48]类似,我们现在在一个变换估计的更广泛背景中利用PPFNet。这样做,我们将所有描述符添加到已建立的基于匹配流程的基于匹配流程的RANSAC中,其中,通过在初始对应集上运行一个最大值为50,000 的RANSAC迭代器来估计片段之间的转换。然后,我们通过估计的3D姿态转变源点云到目标点云中,并且计算点对点误差。这是一个公认的误差度量。表3列出真实数据集上的结果。总的来说,PPFNet又一次作为最突出表现者,同时在大多数场景和平均水平上表现出更高的召回率。值得注意的是,我们总是利用2048个贴片,同时允许3DMatch使用其原始设置5K。即使这样,我们还是可以更好得复现超过一半的场景。当我们给3DMatch提供2048个贴片时,为了与我们的采样水平相当,PPFNet在大多数场景中以更高的平均精度在大多数场景中占据优势地位。

(5)Robustness to point density
Changes in point density, a.k.a. sparsity, is an important concern for point clouds, as it can change with sensor resolution or distance for 3D scanners. This motivates us to evaluate our algorithm against others in varying sparsity levels. We gradually decrease point density on the evaluation data and record the accuracy. Fig. 6(b) shows the significant advantage of PPFNet, especially under severe loss of density (only 6.5% of points kept). Such robustness is achieved due to the PointNet back end and the robust point pair features.
点密度的改变,即稀疏性,对点云来说是一个重要的关注点,因为它可以随着传感器的分辨率或者3D扫描仪的距离而改变。这就促使我们针对其他不同稀疏水平中评估我们的算法。我们在评价数据上逐渐降低点密度,并记录精度。图6(b)显示PPFNet的显著优点,特别是在严重的密度损失下(仅保持6.5%的点)。这样的鲁棒性是以PointNet后端和鲁棒点对特征实现的。
(6)How fast is PPFNet?
We found PPFNet to be lightning fast in inference and very quick in data preparation since we consume a very raw representation of data. Majority of our runtime is spent in the normal computation and this is done only once for the whole fragment. The PPF extraction is carried out within the neighborhoods of only 2048 sample points. Tab. 4 shows the average running times of different methods and ours on an NVIDIA TitanX Pascal GPU supported by an Intel Core i7 3.2GhZ 8 core CPU. Such dramatic speed-up in inference is enabled by the parallelPointNet backend and our simultaneous correspondence estimation during inference for all patches. Currently, to prepare the input for the network, we only use CPU, leaving GPU idle for more work. This part can be easily implemented on GPU to gain even further speed boosts.
自从我们消耗非常原始的点云数据表示,我们发现PPFNet的推理速度非常快,数据准备速度也非常快。我们的大部分运行时间都花费在一般的计算中,在整个片段中只完成一次。PPF提取仅在2048个采样点的邻域进行。表4显示在由Intel Core i7 3.2GhZ 8核心CPU支持的NVIDIA TitanX Pascal GPU上,不同方法和我们的方法的平均运行时间。并行PointNet后端和针对所有贴片的推理期间,我们同时进行的对应估计使得推理的这种显著加速成为可能。目前,为了准备网络的输入,我们只用到了CPU,让GPU空闲更多的工作。这部分可以很容易得在GPU 上实现,以获得更进一步的速度提升。
5.1. Ablation Study
(1)N-tuple loss
We train and test our network with 3 different losses: contrastive (pair) [14], triplet [17] and our N-tuple loss on the same dataset with identical network configuration. Inter-distance distribution of correspondent pairs and non-correspondent pairs are recorded for the train/validation data respectively. Empirical results in Fig. 7 show that the theoretical advantage of our loss immediately transfers to practice: Features learned by N-tuple are better separable, i.e. non-pairs are more distant in the embedding space and pairs enjoy a lower standard deviation.N-tuples loss repels non-pairs further in comparison to contrastive and triplet losses because of its better knowledge of global correspondence relationships. Our N-tuple loss is general and thus we strongly encourage the application also to other domains such as pose estimation [44].
我们在具有相同网络配置的相同数据上训练和测试我们包含三种不同的损失网络:contrastive (pair) [14], triplet [17]和N元组损失。分别为训练、验证数据记录对应对和非对应对之间的间距。图7的实验证明结果表明我们损失的理论优势迅速转移到了实践中:通过N元组学习的特征具有更好的分离性,即在嵌入空间中,不成对的距离更远,成对的有较低的标准偏差。同contrastive和triplet 损失方法相比,N元组损失更排斥非配对的点,因为它更了解全局的对应关系。我们的N元组损失是普遍适用的,因此我们强烈鼓励把它同样应用到其他领域,比如姿态估计[44]。

(2)How useful is global context for local feature extraction?
We argue that local features are dependent on the context. A corner belonging to a dining table should not share the similar local features of a picture frame hanging on the wall. A table is generally not supposed to be attached vertically on the wall. To assess the returns obtained from adding global context, we simply remove the global feature concatenation, keep the rest of the settings unaltered, and re-train and test on two subsets of pairs of fragments. Our results are shown in Tab. 5, where injecting global information into local features improves the matching by 18% in training and 7% in validation set as opposed to our baseline version of Vanilla PointNet •, which is free of global context and PPFs. Such significance indicates that global features aid discrimination and are valid cues also for local descriptors.
我们认为局部特征依赖于环境。属于餐桌的角落不应该同挂在墙上的相框中图片的类似局部特征相共享。桌子通常不应该垂直地贴在墙上。为了评估从添加的全局环境中获取的回报,我们简单地移除全局特征联系,保存余下的设置不变,并在片段的点对的子集上重新训练和测试。我们的结果在表5中显示,将全局信息注入到局部特征中,同我们的基线版本的基础PointNet比,在训练过程中提升18%的匹配度,和7%的验证集匹配度,后者不受全局背景和PPFs的影响。

(3)What does adding PPF bring?
We now run a similar experiment and train two versions of our network, with/without incorporating PPF into the input. The contribution is tabulated in Tab. 5. There, a gain of 1% in training and 5% in validation is achieved, justifying that inclusion of PPF increases the discriminative power of the final features. While being a significant jump, this is not the only benefit of adding PPF. Note that our input representation is composed of 33% rotation-invariant and 66% variant representations. This is already advantageous to the state of the art, where rotation handling is completely left to the network to learn from data. We hypothesize that an input guidance of PPF would aid the network to be more tolerant to rigid transformations. To test this, we gradually rotate fragments around z-axis to 180° with a step size of 30° and then match the fragment to the non-rotated one.
我们现在运行一个类似的实验,并且将我们的网络训练为两个版本,将PPF合并到输入中和不将PPF合并。相关贡献在表5中列出。表中显示,在训练中获得1%的增益,在验证中获得5%的增益,这就证明了包含PPF会增加对最终特征的辨别能力。虽然这是一个重大的飞跃,但这不仅仅是添加PPF的唯一好处。请注意,我们的输入表示是由33%的旋转不变量和66%的变量组成。这对现有技术是有利的,其中旋转处理完全留给网络以从数据中学习。我们假设PPF的输入引导将有助于增加网络对刚性变换的宽容度。为了测试这一点,我们逐渐地绕z轴旋转片段到180°,步长为30°,然后将片段与没有旋转的片段匹配。
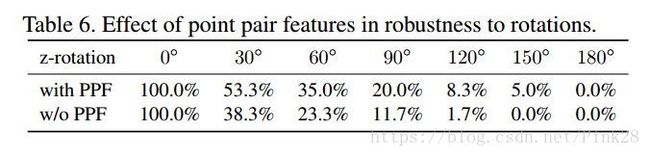
As we can observe from Tab. 6, with PPFs, the feature is more robust to rotation and the ratio in matching performance of two networks opens as rotation increases. In accordance, we also show a visualization of the descriptors at Fig. 9 under small and large rotations. To assign each descriptor an RGB color, we use PCA projection from high dimensional feature space to 3D color space by learning a linear map [23]. It is qualitatively apparent that PPF can strengthen the robustness towards rotations. All in all, with PPFs we gain both accuracy and robustness to rigid transformation, the best of seemingly contradicting worlds. It is noteworthy that using only PPF introduces full invariance besides the invariance to permutations and renders the task very difficult to learn for our current network. We leave this as a future challenge. A major limitation of PPFNet is quadratic memory footprint, limiting the number of used patches to 2K on our hardware. This is, for instance, why we cannot outperform 3DMatch on fragments of Home-2. With upcoming GPUs, we expect to reach beyond 5K, the point of saturation.
正如我们可以从表6中观察到的,对于PPFs,特征对旋转来说更有鲁棒性,随着旋转的增加,两个网络的匹配表现率也随之增加。此外,我们还在图9中展示了在小和大的旋转下描述符的可视化。为了给每个描述符分配RGB颜色,我们通过学习线性映射[23],采用从高维特征空间到3D色彩空间的PCA投影。PPF可以定量明显地增强对旋转的鲁棒性。总而言之,通过PPFs,我们不仅获得了刚性变换的精确性和鲁棒性,在看似矛盾的事物中最好的选择。值得注意的是,除了对排序的不变性外,仅适用PPF还引入了完全不变性,并且对于我们当前的网络来说,使得任务非常难以学习。我们将视其为未来的挑战。PPFNet的一个主要局限性是二次内存的占用空间,将我们硬件上使用贴片的数量限制为2K。这就是我们为什么不能在Home-2的片段上胜过3DMatch的原因。随着即将到来的GPU,我们预计饱和点的数目将达到超过5K。
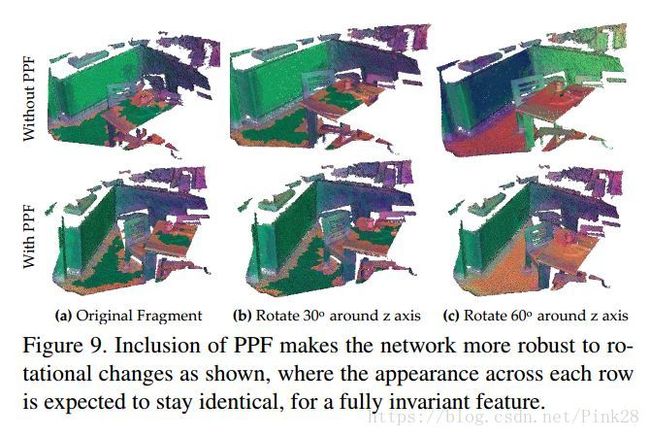
图9.正如图中所示,包含PPF使得网络对旋转的变化更具有鲁棒性,为了一个完全不变的特征,预期每一行的外观保持一致。

- Conclusion
We have presented PPFNet, a new 3D descriptor tailored for point cloud input. By generalizing the contrastive loss to N-tuple loss to fully utilize available correspondence relatioships and retargeting the training pipeline, we have shown how to learn a globally aware 3D descriptor, which outperforms the state of the art not only in terms of recall but also speed. Features learned from our PPFNet is more capable of dealing with some challenging scenarios, as shown in Fig. 8. Furthermore, we have shown that designing our network suitable for set-input such as point pair features are advantageous in developing invariance properties. Future work will target memory bottleneck and solving the more general rigid graph matching problem.
我们已经提出了PPFNet,一个新的适合于点云输入的3D描述符。通过将对比度损失推广到N元组损失以充分利用可获得的对应关系,并且对训练流程进行重新定向,我们已经展示了如何学习一个全局感知的3D描述符,该描述符不仅在召回率方面而且在速度方面都优于现有技术。正如图8中所示,从我们的PPFNet中学习特征更有能力处理包含挑战的场景。此外,我们还展示了,我们的网络设计为适用于像点对特征的点集输入对开发的不变性是有利的。未来的工作将针对内存瓶颈和解决更普遍的刚性图形匹配问题。
标红的部分都是现阶段不是很拿捏得准的地方,以便后续更改。