DARTS 可微 架构搜索
论文链接:Differentiable Architecture Search
源代码:quark0/darts
背景
我们现在主流的效果最好的两种方法,进化学习(evolution)和强化学习(Reinforcement),他们的搜索空间都是不可微的,而现在作者提出了一种可微的方法,可以用梯度下降来解决架构搜索的问题,所以效率可以比之前不可微的方法快几个数量级。可以这么通俗的理解:之前不可微的方法,相当于是你定义了一个搜索空间(比如3*3和5*5的卷积核),然后神经网络的每一层你可以从搜索空间中选一个构成了一个神经网络,跑一下这个神经网络试结果,然后再换其它的可能,本质是在很多的组合当中尽快搜索到效果很好的那个,但这个过程是黑箱,所以我们有大量的验证过程,所以会很耗时,而这篇论文,他把架构搜索融合在模型当中,一起训练,具体怎么操作我们看下文的解析。对于是否耗时,这个有不同的评价标准,比如对于这种有大量采样,验证的方向,我们很好的支持并行,在机器足够多的情况下时间可能会很短,但这种可微串行的方法,就不太适用与机器很多的情况。
算法
会分三部分讲,第一部分讲如何定义它的搜索空间,第二部分讲梯度下降优化的策略,第三部分讲一个它的trick,使得算法效果提升,速度下降。
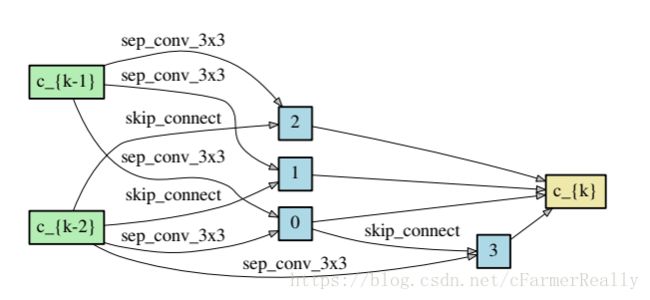
搜索空间
作者是如何松弛搜索空间使它能够梯度下降呢?(例如将离散的3*3,5*5松弛为一个连续值)
darts要做的事情,是训练出来一个cell(小网络),然后把cell相连构成一个大网络,而超参数layers可以控制有多少个cell相连,例如layers = 20,表示有20个cell前后相连,我们现在定义这个cell的结构。
cell由输入节点,中间节点,输出节点,边构成,我们规定每一个cell有两个输入节点和一个输出节点:
- 输入节点:对于卷积网络来说,两个输入节点分别是前两层(layers)cell的输出,对于循环网络(Recurrent)来说,输入时当前层的输入和前一层的状态。
- 中间节点:每一个中间节点都由它的前继通过边再求和得来(可以看图理解)。
- 输出节点:由每一个中间节点concat起来。
- 边:边代表的是operation(比如3*3的卷积),在收敛得到结构的过程中,两两节点中间所有的边都会存在并参与训练,最后加权平均,这个权就是我们要训练的东西,我们希望得到的结果是效果最好的边它的权重最大。
上面这个过程我们用一个图来表示:

上图中明确表示了:
0有三个后继,1,2,3
1有两个后继,2,3
2有一个后继,3
每两个节点之间都连着所有的边。
上面那个式子表示如何处理前继,
下面那个式子表示如何处理边(加权平均,和softmax那个有点像),权就是alpha,也就是我们训练的东西,我们把这么些个alpha称作一个权值矩阵,我们收敛到最后就是希望得到一个权值矩阵,这个矩阵当中权值越大的边,留下来之后效果越好。
优化策略
我们前面已经知道了我们的目的是为了通过梯度下降优化alpha矩阵,我们把神经网络原有的权重称为W矩阵,那么我们现在其实是希望能同时优化两个矩阵使得结果变好。我们可以work的一个朴素的思路是,再训练集上固定alpha矩阵的值,然后梯度下降W矩阵的值,再验证集上固定W矩阵的值,然后梯度下降alpha的值,循环往复直到这两个值都比较理想,这个过程有点像k-means的过程,先定了中心,再求均值,再换中心,再求均值,这个时候有一个点是验证机和训练集的划分比例是1:1的,因为对于alpha矩阵来说,验证集就是它的训练集。
但是我们这个方法虽然可以work,但是效果不是很好,作者提了一个trick,就是我们要讲的第三部分。
Approximation
这一部分说实话我没有看太明白它的数学式子,具体的内容大家可以看原文链接的paper中的部分就可以了,我通俗的说一下我的理解。

他在优化的过程中,不单单是在验证集上简单的梯度下降alpha的值,而是求了一下二阶导,它希望知道能如何下降不仅在当前验证集效果好,而且在训练集的效果也好,这样就可以使原来的网络更好,速度也更快,具体的数据式子大家看原论文,也可能我理解有偏差大家一起讨论交流。
生成网络
我们前面讲到了,我们要训练出来一个alpha矩阵,使得权重大的边保留下来会更work,所以在这个结构收敛了之后它还会做一个生成最终网络的过程,那这个时候你可能会问说为什么不把之前的结构直接用上呢?我觉得是因为边太多,结构太复杂,参数太多不好训练,所以作者希望能生成一个更简单的网络结构,接下来我们说生成的方法。
对于每一个中间节点来说,我们最多保留两个最强壮的前继,对于两两节点之间的边,我们只保留权重最大的一条边,我们定义一下什么最强壮的前继。
假设一个节点有三个前继,那我们选哪两个呢?把前继和当前节点之间权重最高的那条边代表那个前继的强壮程度,我们选最强壮的两个前继。节点之间只保留权重最大的那条边。
由此,我们就把整个算法介绍完了,它训练出来一个好的cell,然后有多个layers构成大的网络,但是!!!
总结
我们不难发现,这篇论文的先验太多了,比如说:为什么train cifar10的时候收敛结构用的是layers是8层?为什么我最后只保留权重最大的那条边?为什么我只能保留两个前继?为什么我训练一个cell然后连起来就能work?等等
比如layers,比如一个cell里面有几个节点,其实这个是超参数,也就说我原来训练一个网络我要调这个网络我怎么设计,那现在变成了我要调这个网络有多少个layers,多少个节点,所以我觉得这个方法不够auto,它的效果足够惊艳可能是因为作者已经知道这个网络很好然后搜出来了这个网络,但这个搜的过程不够auto。
那有几个思路,比如我能不能做增量学习使得不设置layers也可以?我能不能保留权重相差不大的几条边而不只是一条?第一个提出可微搜索的不是这个作者,但是这个作者最厉害的地方在于他work了,那接下来可能还有很多工作可以做,大家可以进一步做实验,也欢迎大家和我这个萌新一起交流,进步。
以上全都是自己的理解,难免有不严谨的地方,非常希望能有做相关方向的人我们在一起能一起交流,可以联系我,如果文中有不对,没有解释清楚的地方,直接在评论喷就好了,我会及时看和更新的。