NLP实践九:HAN原理与文本分类实践
文章目录
- HAN原理
- 代码实践
HAN原理
参考多层注意力模型
用于文本分类的注意力模型

整个网络结构包括五个部分:
1)词序列编码器
2)基于词级的注意力层
3)句子编码器
4)基于句子级的注意力层
5)分类
整个网络结构由双向GRU网络和注意力机制组合而成,具体的网络结构公式如下:
1)词序列编码器
给定一个句子中的单词 w i t w_{it} wit,其中 i 表示第 i 个句子,t 表示第 t 个词。通过一个词嵌入矩阵 W e W_e We 将单词转换成向量表示,具体如下所示:
x i t = W e ; w i t x_{it} = W_e; w_{it} xit=We;wit
接下来看看利用双向GRU实现的整个编码流程:

h i t = [ → h i t , ← h i t ] h_{it} = [{\rightarrow{h}}_{it}, \leftarrow{h}_{it}] hit=[→hit,←hit] 。
2)词级的注意力层
但是对于一句话中的单词,并不是每一个单词对分类任务都是有用的,比如在做文本的情绪分类时,可能我们就会比较关注“很好”、“伤感”这些词。为了能使循环神经网络也能自动将“注意力”放在这些词汇上,作者设计了基于单词的注意力层的具体流程如下:
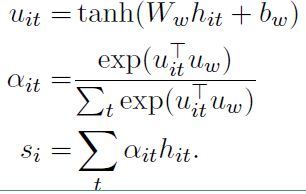
上面式子中, u i t u_{it} uit 是 h i t h_{it} hit 的隐层表示, a i t a_{it} ait 是经 softmax 函数处理后的归一化权重系数, u w u_w uw 是一个随机初始化的向量,之后会作为模型的参数一起被训练, s i s_i si 就是我们得到的第 i 个句子的向量表示。
3)句子编码器
也是基于双向GRU实现编码的,其流程如下:

公式和词编码类似,最后的 h i h_i hi 也是通过拼接得到的.
4)句子级注意力层
注意力层的流程如下,和词级的一致:
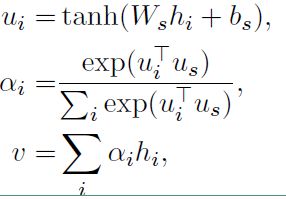
最后得到的向量 v 就是文档的向量表示,这是文档的高层表示。接下来就可以用可以用这个向量表示作为文档的特征。
5)分类
使用最常用的softmax分类器对整个文本进行分类了
![]()
损失函数如下:
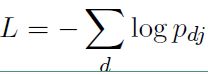
代码实践
使用Thucnews数据集,数据处理等代码请参考之前的文章。
模型定义
class Attention(nn.Module):
def __init__(self, feat_dim, bias=False):
super(Attention, self).__init__()
self.weight = nn.Parameter(t.Tensor(feat_dim, 1))
if bias:
raise ValueError('not implemented')
def forward(self, x):
"""x: B L C"""
B, L, C = x.size()
eij = x.view(B*L, C).mm(self.weight).view(B, L)
alpha = F.softmax(eij, dim=1)
# print(alpha.unsqueeze(-1).size())
out = t.bmm(x.permute(0, 2, 1), alpha.unsqueeze(-1)) #B C L ** B L 1 --> B C 1
return out.squeeze()
class HAN(nn.Module):
def __init__(self, sent_len, word_len, embed_weight, spatial_drop=0.1,
rnn_h_word_dim=32, ui_word_dim=32, rnn_h_sent_dim=32, ui_sent_dim=32,
fc_h_dim=32, fc_drop=0.2, nb_class=10, batch_size=512):
super(HAN, self).__init__()
embed_weight = t.FloatTensor(embed_weight)
embed_num, embed_dim = embed_weight.shape
self.embed = nn.Embedding(embed_num, embed_dim)
self.embed.weight = nn.Parameter(t.FloatTensor(embed_weight))
self.embed.weight.requires_grad = False
self.spatial_drop = nn.Dropout2d(p=spatial_drop, inplace=True)
self.word_gru = nn.GRU(embed_dim, rnn_h_word_dim, batch_first=True, bidirectional=True)
self.word_linear = nn.Linear(2*rnn_h_word_dim, ui_word_dim)
self.word_att = Attention(feat_dim=ui_word_dim, bias=False)
self.sent_gru = nn.GRU(rnn_h_word_dim, rnn_h_sent_dim, batch_first=True, bidirectional=True)
self.sent_linear = nn.Linear(2*rnn_h_sent_dim, ui_sent_dim)
self.sent_att = Attention(feat_dim=ui_sent_dim, bias=False)
self.classifier = nn.Sequential(OrderedDict({
'fc1': nn.Linear(rnn_h_sent_dim, fc_h_dim),
'drop': nn.Dropout(p=fc_drop, inplace=True),
'relu': nn.ReLU(inplace=True),
'fc2': nn.Linear(fc_h_dim, nb_class)
}))
# t.nn.init.xavier_normal_(self.classifier[0].weight, gain=1)
# t.nn.init.xavier_normal_(self.classifier[3].weight, gain=1)
self.rnn_h0_word = nn.Parameter(t.randn(2, batch_size, rnn_h_word_dim).type(t.FloatTensor), requires_grad=True)
self.softmax=nn.Softmax()
def get_optimizer(self, lr_base=1e-3, lr_embed=0, weight_decay=0):
embed_param = self.embed.parameters()
id_embed_param = list(map(id, embed_param))
base_param = list(filter(lambda x: id(x) not in id_embed_param, self.parameters()))
optimizer = t.optim.Adam([
{'params': embed_param, 'lr': lr_embed},
{'params': base_param, 'lr': lr_base}
])
return optimizer
def forward(self, x):
"""x: B s_l w_l long --> B 1 score """
B, s_l, w_l = x.size()
x = x.permute(1,0,2) #s_l B w_l
x = self.embed(x) # s_l B w_l E
x = self.spatial_drop(x.view(s_l*B, w_l, x.size(-1)).unsqueeze(-1)) #s_l*B w_l E 1
x = x.view(s_l, B, w_l, -1) # s_l B w_l E
h = None
y = []
for word_batch in x:
out, h = self.word_gru(word_batch, h)
y.append(out)
y = t.cat(y, 0) # s_l B w_l 2Hw
y = self.word_linear(y)
y = t.tanh(y) #s_l B w_l C
y = self.word_att(y.view(s_l*B, w_l, -1)).view(s_l, B, -1).permute(1,0,2) # B s_l C
out, _ = self.sent_gru(y) # B s_l 2Hs
out = self.sent_linear(out)
out = F.tanh(out)
out = self.sent_att(out) # B 2Hs
score = self.classifier(out)
return score
数据加载:
class MyDataset(Dataset):
def __init__(self, data_path, w2i_path,
max_length_sentences, max_length_word):
super(MyDataset, self).__init__()
self.data = pd.read_pickle(data_path)
self.texts = self.data['content'].values
self.labels = torch.from_numpy(self.data['label_id'].values)
self.w2i = pickle.load(open(w2i_path, "rb"))
self.max_length_sentences = max_length_sentences
self.max_length_word = max_length_word
def __len__(self):
return len(self.labels)
def chunkIt(self, seq, num, interval):
return [seq[i*interval:(i+1)*interval] for i in range(num)]
def chunkIt_(self, seq, num):
avg = len(seq) / float(num)
out = []
last = 0.0
while last < len(seq):
out.append(seq[int(last):int(last + avg)])
last += avg
return out
def __getitem__(self, index):
label = self.labels[index]
text = self.texts[index]
sent_list = self.chunkIt(text, self.max_length_sentences, self.max_length_word)
document_encode = [
[self.w2i[word] if word in self.w2i else -1 for word in sent] for sent
in
sent_list]
for sentences in document_encode:
if len(sentences) < self.max_length_word:
extended_words = [-1 for _ in range(self.max_length_word - len(sentences))]
sentences.extend(extended_words)
if len(document_encode) < self.max_length_sentences:
extended_sentences = [[-1 for _ in range(self.max_length_word)] for _ in
range(self.max_length_sentences - len(document_encode))]
document_encode.extend(extended_sentences)
document_encode = [sentences[:self.max_length_word] for sentences in document_encode][
:self.max_length_sentences]
document_encode = np.stack(arrays=document_encode, axis=0)
document_encode += 1
document_encode = t.Tensor(document_encode)
return document_encode.long(), label
训练:
import os
os.environ['CUDA_VISIBLE_DEVICES']='0'
t.cuda.set_device(0)
model = HAN(15, 25, embed_weight)
criterion = nn.CrossEntropyLoss()
optimizer = model.get_optimizer()
optimizer = torch.optim.Adam(filter(lambda p: p.requires_grad, model.parameters()), lr=0.001)
train(train_loader, val_loader,
model, 'cuda',
criterion, optimizer,
num_epochs=20)