高性能MySQL第六章笔记
1.不要查询不需要的列,不要用select *(减少内存占用和网络带宽占用,减少表结构变化带来的影响)
2.EXPLAIN语句结果中的rows是预估的要扫描的行数,Extra:Using Where表示MySQL将通过WHERE条件来筛选存储引擎(注意是存储引擎)返回的记录
一般MySQL能够使用如下三种方式应用WHERE条件,从好到坏:
在索引中使用WHERE条件来过滤,在存储引擎层
使用索引覆盖扫描(在Extra列中出现了Using index)来返回记录,直接从索引中过滤不需要的记录并返回命中的结果。这是在MySQL服务器层返回的,但无须再回表查询记录。
从数据表中返回数据,然后过滤不满足条件的记录(Extra:Using Where)。这是在MySQL服务层完成,MySQL需要从数据表读出记录然后过滤。
3.使用多个简单查询来代替一个复杂查询
3.1如每个月删除旧的数据,为了防止一次锁住很多数据,占满整个事务日志,耗尽系统资源,阻塞很多小的但重要的查询:
将DELETE FROM message WHERE created < DATE_SUB(NOW,INTERVAL 3 MONTH);
换为:
rows_affected = 0
do{
rows_affected = do_query(
"DELETE FROM message WHERE created < DATE_SUB(NOW,INTERVAL 3 MONTH)
LIMIT 10000"
)
}while rows_affected>0
3.2分解关联查询
优势:
让缓存的效率更高;减少锁的竞争;在应用层做关联,可以更容易对数据库进行拆分,更容易做到高性能和可扩展;减少冗余记录的查询,减少内存和网络的消耗。
4.查询执行的基础
内容比较多,这里只记录几点:
4.3 MySQL如何执行关联查询:嵌套循环
4.4 MySQL的临时表是没有索引的,在编写复杂的子查询和关联查询的时候需要注意这一点
5.MySQL查询优化器的缺陷
5.1 避免用IN(子查询)
如SELECT * FROM sakila.film WHERE file_id IN(
SELECT film_id FROM sakila.film_actor WHERE actor_id = 1;
)
我们会认为上面的查询会这样执行:
--SELECT GROUP_CONCAT(film_id) FROM sakila.film_actor WHERE actor_id = 1;
--Result:1,23,25,106,140,166,277,361,436,499,506,509,605,635,749,832,939,970,980
SELECT * FROM sakila.film
WHERE film_id
IN(1,23,25,106,140,166,277,361,436,499,506,509,605,635,749,832,939,970,980)
但MySQL实际会将查询改写成下面这样的关联子查询:
SELECT * FROM sakila.film
WHERE EXISTS(
SELECT * FROM sakila.film_actor WHERE actor_id = 1
AND film_actor.film_id = film.film_id);
性能非常差
可用如下语句改写:
SELECT film.* FROM sakila.film
INNER JOIN sakila.film_actor USING(film_id)
WHERE actor_id = 1;‘
另一个优化的方法是使用GROUP_CONCAT()在IN()中构造一个由逗号分隔的列表
注1:关联子查询:在关联子查询中,对于外部查询返回的每一行数据,内部查询都要执行一次。另外,在关联子查询中是信息流是双向的。外部查询的每行数据传递一个值给子查询,然后子查询为每一行数据执行一次并返回它的记录。然后,外部查询根据返回的记录做出决策。
注2:可用EXPLAIN EXTENDED来查看这个查询被改写成什么样子
注3:前面提到关联子查询效率低,可以用join代替,但其实不是所有关联子查询效率都低,应当测试
注4:可用SHOW STATUS 查看扫描的行数
5.2 如果要取出UNION ALL的两个子句的前N条可以在子句里面和外面都加上LIMIT N;
5.3 MIN()和MAX():
看这个语句:SELECT MIN(actor_id) FROM sakila.actor WHERE first_name = 'PENELOPE';
first_name上没有索引所以会全表扫描,因为主键是按照从小到大排列,理论上扫描到第一个满足条件的记录就是了,可是MySQL却只会全表扫表,重写:
SELECT actor_id FROM sakila.actor USE INDEX(PRIMARY)
WHERE first_name = 'PENELOPE' LIMIT 1;
6. 优化特定类型的查询
6.1 COUNT()或COUNT(*)统计行数,COUNT(exp)统计exp有值的结果数
条件反转优化:
将SELECT COUNT(*) FROM world.City WHERE ID > 5;
优化为:
SELECT (SELECT COUNT(*) FROM world.City)-COUNT(*)
WHERE world.City WHERE ID < 5;
近似值优化,有些业务不需要精确值,可以用EXPLAIN出来的rows近似值代替:
6.2 优化关联查询:
确保ON或者USING子句中的列上有索引
确保GROUP BY和ORDER BY中的表达式只涉及一个表中的列,这样MySQL才能使用索引来优化这个过程
6.3 优化子查询
尽可能使用关联查询代替(MySQL5.6后可忽略这条)
6.4优化LIMIT分页
大偏移量时LIMIT效率很差,因为他会扫描很多然后丢弃他们
SELECR film_id,description FROM sakila.film ORDER BY title LIMIT 50,5
"延迟关联"优化为:
SELECT film.film_id , film.description
FROM sakila.film
INNER JOIN(
SELECT film_id FROM sakila.film
ORDER BY title LIMIT 50,5
)AS lim USING(film_id)
另一种优化是,预先存储排名信息,然后优化为:
SELECT film_id,description FROM sakila.film
WHERE position BETWEEN 50 AND 54 ORDER BY position
6.5 优化UNION查询
MySQL总是通过创建并填充临时表的方式来执行UNION查询,因此很多优化策略在UNION中都没法很好地使用,经常需要手动的将WHERE,LIMIT,ORDER BY等子句“下推”到UNION的各个子查询中,以便优化器利用这些条件进行优化。
除非确实需要消除重复的行,否则就一定要使用UNION ALL,如果没有ALL,MySQL就会给临时表加上DISTINCT选项,代价很高
7.其他注意点:
7.1不要用前置%和前后双%,这会使索引失效
7.2 索引的最左前缀匹配
7.3 使用left join或not exists来优化not in(会使索引失效)
7.4 避免隐式转换,这会使索引失效
7.5 使用in代替or,in可利用索引
7.6 不要join太多表
7.7 程序中使用预编译语句:防止SQL注入;同步地使用执行计划;一次解析,多次利用
7.8 程序连接不同数据库使用不同的帐号,禁止跨库查询:降低业务耦合度;安全;为了以后的分库分表和数据库迁移
7.9 禁止使用不含字段列表的INSERT语句
7.10 减少同数据库的交互次数
7.11 禁止用ORDER BY rand()进行随机排序:这会把表中所有符合条件的数据装载到内存中;推荐在程序中获取随机值到数据库中取相应的数据
7.12 禁止在WHERE中对列进行函数转换和计算,这回导致索引失效
2.EXPLAIN语句结果中的rows是预估的要扫描的行数,Extra:Using Where表示MySQL将通过WHERE条件来筛选存储引擎(注意是存储引擎)返回的记录
一般MySQL能够使用如下三种方式应用WHERE条件,从好到坏:
在索引中使用WHERE条件来过滤,在存储引擎层
使用索引覆盖扫描(在Extra列中出现了Using index)来返回记录,直接从索引中过滤不需要的记录并返回命中的结果。这是在MySQL服务器层返回的,但无须再回表查询记录。
从数据表中返回数据,然后过滤不满足条件的记录(Extra:Using Where)。这是在MySQL服务层完成,MySQL需要从数据表读出记录然后过滤。
3.使用多个简单查询来代替一个复杂查询
3.1如每个月删除旧的数据,为了防止一次锁住很多数据,占满整个事务日志,耗尽系统资源,阻塞很多小的但重要的查询:
将DELETE FROM message WHERE created < DATE_SUB(NOW,INTERVAL 3 MONTH);
换为:
rows_affected = 0
do{
rows_affected = do_query(
"DELETE FROM message WHERE created < DATE_SUB(NOW,INTERVAL 3 MONTH)
LIMIT 10000"
)
}while rows_affected>0
3.2分解关联查询
优势:
让缓存的效率更高;减少锁的竞争;在应用层做关联,可以更容易对数据库进行拆分,更容易做到高性能和可扩展;减少冗余记录的查询,减少内存和网络的消耗。
4.查询执行的基础
内容比较多,这里只记录几点:
4.1 查询执行路径
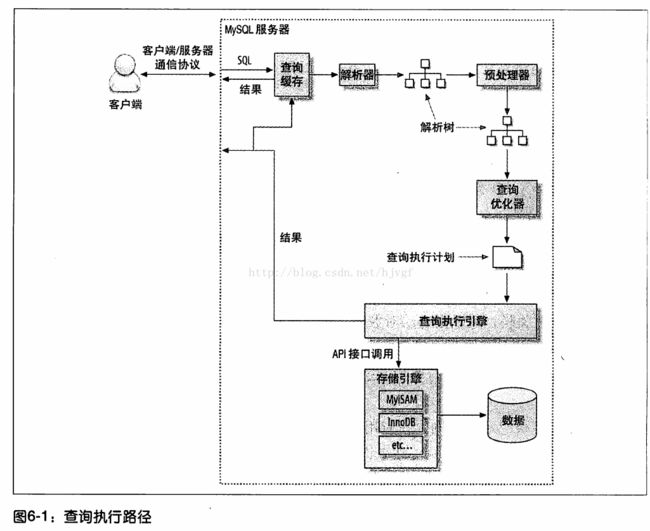
4.3 MySQL如何执行关联查询:嵌套循环
4.4 MySQL的临时表是没有索引的,在编写复杂的子查询和关联查询的时候需要注意这一点
5.MySQL查询优化器的缺陷
5.1 避免用IN(子查询)
如SELECT * FROM sakila.film WHERE file_id IN(
SELECT film_id FROM sakila.film_actor WHERE actor_id = 1;
)
我们会认为上面的查询会这样执行:
--SELECT GROUP_CONCAT(film_id) FROM sakila.film_actor WHERE actor_id = 1;
--Result:1,23,25,106,140,166,277,361,436,499,506,509,605,635,749,832,939,970,980
SELECT * FROM sakila.film
WHERE film_id
IN(1,23,25,106,140,166,277,361,436,499,506,509,605,635,749,832,939,970,980)
但MySQL实际会将查询改写成下面这样的关联子查询:
SELECT * FROM sakila.film
WHERE EXISTS(
SELECT * FROM sakila.film_actor WHERE actor_id = 1
AND film_actor.film_id = film.film_id);
性能非常差
可用如下语句改写:
SELECT film.* FROM sakila.film
INNER JOIN sakila.film_actor USING(film_id)
WHERE actor_id = 1;‘
另一个优化的方法是使用GROUP_CONCAT()在IN()中构造一个由逗号分隔的列表
注1:关联子查询:在关联子查询中,对于外部查询返回的每一行数据,内部查询都要执行一次。另外,在关联子查询中是信息流是双向的。外部查询的每行数据传递一个值给子查询,然后子查询为每一行数据执行一次并返回它的记录。然后,外部查询根据返回的记录做出决策。
注2:可用EXPLAIN EXTENDED来查看这个查询被改写成什么样子
注3:前面提到关联子查询效率低,可以用join代替,但其实不是所有关联子查询效率都低,应当测试
注4:可用SHOW STATUS 查看扫描的行数
5.2 如果要取出UNION ALL的两个子句的前N条可以在子句里面和外面都加上LIMIT N;
5.3 MIN()和MAX():
看这个语句:SELECT MIN(actor_id) FROM sakila.actor WHERE first_name = 'PENELOPE';
first_name上没有索引所以会全表扫描,因为主键是按照从小到大排列,理论上扫描到第一个满足条件的记录就是了,可是MySQL却只会全表扫表,重写:
SELECT actor_id FROM sakila.actor USE INDEX(PRIMARY)
WHERE first_name = 'PENELOPE' LIMIT 1;
6. 优化特定类型的查询
6.1 COUNT()或COUNT(*)统计行数,COUNT(exp)统计exp有值的结果数
条件反转优化:
将SELECT COUNT(*) FROM world.City WHERE ID > 5;
优化为:
SELECT (SELECT COUNT(*) FROM world.City)-COUNT(*)
WHERE world.City WHERE ID < 5;
近似值优化,有些业务不需要精确值,可以用EXPLAIN出来的rows近似值代替:
6.2 优化关联查询:
确保ON或者USING子句中的列上有索引
确保GROUP BY和ORDER BY中的表达式只涉及一个表中的列,这样MySQL才能使用索引来优化这个过程
6.3 优化子查询
尽可能使用关联查询代替(MySQL5.6后可忽略这条)
6.4优化LIMIT分页
大偏移量时LIMIT效率很差,因为他会扫描很多然后丢弃他们
SELECR film_id,description FROM sakila.film ORDER BY title LIMIT 50,5
"延迟关联"优化为:
SELECT film.film_id , film.description
FROM sakila.film
INNER JOIN(
SELECT film_id FROM sakila.film
ORDER BY title LIMIT 50,5
)AS lim USING(film_id)
另一种优化是,预先存储排名信息,然后优化为:
SELECT film_id,description FROM sakila.film
WHERE position BETWEEN 50 AND 54 ORDER BY position
6.5 优化UNION查询
MySQL总是通过创建并填充临时表的方式来执行UNION查询,因此很多优化策略在UNION中都没法很好地使用,经常需要手动的将WHERE,LIMIT,ORDER BY等子句“下推”到UNION的各个子查询中,以便优化器利用这些条件进行优化。
除非确实需要消除重复的行,否则就一定要使用UNION ALL,如果没有ALL,MySQL就会给临时表加上DISTINCT选项,代价很高
7.其他注意点:
7.1不要用前置%和前后双%,这会使索引失效
7.2 索引的最左前缀匹配
7.3 使用left join或not exists来优化not in(会使索引失效)
7.4 避免隐式转换,这会使索引失效
7.5 使用in代替or,in可利用索引
7.6 不要join太多表
7.7 程序中使用预编译语句:防止SQL注入;同步地使用执行计划;一次解析,多次利用
7.8 程序连接不同数据库使用不同的帐号,禁止跨库查询:降低业务耦合度;安全;为了以后的分库分表和数据库迁移
7.9 禁止使用不含字段列表的INSERT语句
7.10 减少同数据库的交互次数
7.11 禁止用ORDER BY rand()进行随机排序:这会把表中所有符合条件的数据装载到内存中;推荐在程序中获取随机值到数据库中取相应的数据
7.12 禁止在WHERE中对列进行函数转换和计算,这回导致索引失效