之前写过一篇 一个框架解决几乎所有机器学习问题 但是没有具体的例子和代码,今天看到一个不错的 kaggle 上的 code Exploratory Tutorial - Titanic 来解析一下,源码可以直接点这个链接。
在这篇文章中可以学到一个完整的运用机器学习解决分析问题的过程,它包括了解决问题的一般流程,描述性统计的常用方法,数据清洗的常用方法,如何由给定的普通变量启发式思考其他影响因素,sklearn 建立模型的一般流程,以及很火的 ensemble learning 怎么用。
下面进入正题:
在 Titanic: Machine Learning from Disaster 这个问题中,要解决的是根据所提供的 age,sex 等因素的数据,判断哪些乘客更有可能生存下来,所以这是一个分类问题。
在解决机器学习问题时,一般包括以下流程:
- Data Exploration
- Data Cleaning
- Feature Engineering
- Model Building
- Ensemble Learning
- Predict
1. Data Exploration
这部分先导入常用的 Numpy,Pandas,Matplotlib 等包,导入训练集和测试集:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
train = pd.read_csv('../input/train.csv')
test = pd.read_csv('../input/test.csv')
之后,可以用下面的命令先观察一下数据表的结构:
train.tail()
test.head()
train.describe()
接下来,可以观察各个变量的分布情况:
各个变量在测试集和训练集的分布差不多一致。
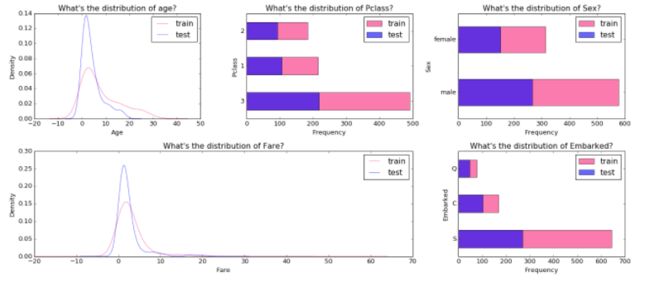
然后看一下各个变量对分类标签的影响:
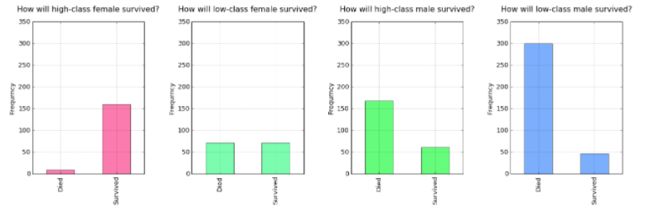
例如,性别的影响,通过可视化可以发现,生还的乘客中女性多于男性.
或者 Pclass 的影响。
2. Data Cleaning
这个部分,可以统计一下各个变量的缺失值情况:
train.isnull().sum()
#test.isnull().sum()
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
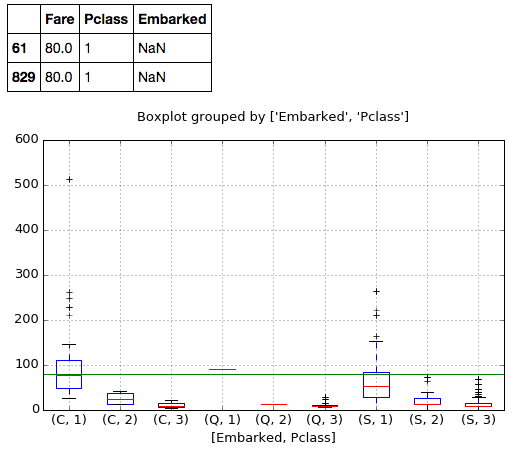
然后对缺失部分进行处理,如果是连续变量,可以采用预测模型,例如 Age,如果是离散的变量,可以找到类似的数据群体,然后取最多的,或者最多群体的平均值。
eg,Embarked 这两个缺失值,可以看 Pclass 1 and Fare 80 时,最多的情况是 Embarked=C。
3. Feature Engineering
之前有过一篇 特征工程怎么做 只是介绍了一些概念,这个例子就是比较具有启发性,看看怎么通过给定的几个变量,去拓展成更有影响力的 feature,如何结合实际情况联想新的因素,并转化成数字的形式表达出来。
下面是数据中的原始变量,看看由它们可以联想到什么因素。
pclass Passenger Class
(1 = 1st; 2 = 2nd; 3 = 3rd)
name Name
sex Sex
age Age
sibsp Number of Siblings/Spouses Aboard
parch Number of Parents/Children Aboard
ticket Ticket Number
fare Passenger Fare
cabin Cabin
embarked Port of Embarkation
(C = Cherbourg; Q = Queenstown; S = Southampton)
除了性别,年龄等明显的因素,社会地位等也可能影响着谁会优先乘坐救生艇,或被救助而生存下来。例如,
- Name 里可以抓取到这样的字眼,来反映出乘客的职场地位: ['Capt', 'Col', 'Major', 'Dr', 'Officer', 'Rev']。
- Cabin 里的 [a-zA-Z] 也许可以反映出社会地位。
- Cabin 里的 [0-9] 可能代表船舱的地理位置。
- SibSp 可以算出乘客中同一家庭成员人数的大小。
title[title.isin(['Capt', 'Col', 'Major', 'Dr', 'Officer', 'Rev'])] = 'Officer'
deck = full[~full.Cabin.isnull()].Cabin.map( lambda x : re.compile("([a-zA-Z]+)").search(x).group())
checker = re.compile("([0-9]+)")
full['Group_num'] = full.Parch + full.SibSp + 1
在这个环节中,还有必要把类别数据变换成 dummy variable 的形式,也就是变换成向量格式,属于第几类就在第几个位置上为 1,其余位置为 0.
连续数据做一下归一化,即把大范围变化的数据范围缩小至 0~1 或者 -1~1 之间。
然后把不相关的变量 drop 掉。
train = pd.get_dummies(train, columns=['Embarked', 'Pclass', 'Title', 'Group_size'])
full['NorFare'] = pd.Series(scaler.fit_transform(full.Fare.reshape(-1,1)).reshape(-1), index=full.index)
full.drop(labels=['PassengerId', 'Name', 'Cabin', 'Survived', 'Ticket', 'Fare'], axis=1, inplace=True)
4. Model Building
首先就是把数据分为训练集和测试集,用到 train_test_split,
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
因为后面会用到很多模型,所以可以把 cross validation 和 fit 的部分写入一个函数,这样每次把分类器投入到函数中训练,最后返回训练好的模型即可。
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import make_scorer
from sklearn.metrics import accuracy_score
scoring = make_scorer(accuracy_score, greater_is_better=True)
def get_model(estimator, parameters, X_train, y_train, scoring):
model = GridSearchCV(estimator, param_grid=parameters, scoring=scoring)
model.fit(X_train, y_train)
return model.best_estimator_
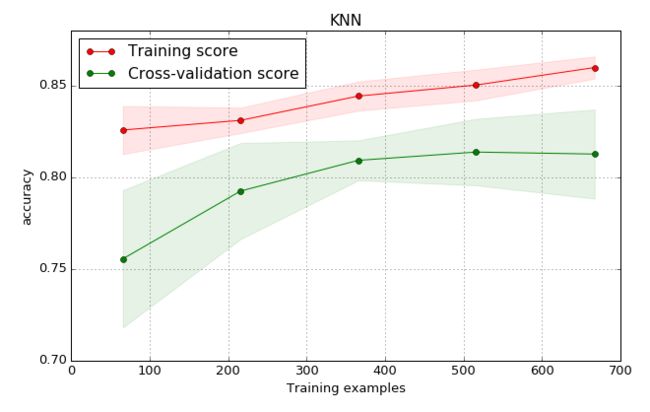
以一个 KNN 为例,来看一下建立 训练 并用模型预测的过程,
- 从
sklearn导入分类器模型后,定义一个 KNN, - 定义合适的参数集
parameters, - 然后用
get_model去训练 KNN 模型, - 接下来用训练好的模型去预测测试集的数据,并得到
accuracy_score, - 然后画出
learning_curve。
from sklearn.neighbors import KNeighborsClassifier
KNN = KNeighborsClassifier(weights='uniform')
parameters = {'n_neighbors':[3,4,5], 'p':[1,2]}
clf_knn = get_model(KNN, parameters, X_train, y_train, scoring)
print (accuracy_score(y_test, clf_knn.predict(X_test)))
plot_learning_curve(clf_knn, 'KNN', X, y, cv=4);
采用上面的方式,尝试多种模型,并打印出它们的 accuracy_score:
KNN, 0.816143497758
Random Forest, 0.829596412556
只选择比较重要的几个特征后的 Random Forest, 0.834080717489
Logistic Regression, 0.811659192825
SVC, 0.838565022422
XGBoost, 0.820627802691
5. Ensemble
接下来把前面训练好的几个分类器用 VotingClassifier 集成起来再 fit 训练一下,打印 accuracy_score 并画出 learning_curve。
from sklearn.ensemble import VotingClassifier
clf_vc = VotingClassifier(estimators=[('xgb1', clf_xgb1), ('lg1', clf_lg1), ('svc', clf_svc),
('rfc1', clf_rfc1),('rfc2', clf_rfc2), ('knn', clf_knn)],
voting='hard', weights=[4,1,1,1,1,2])
clf_vc = clf_vc.fit(X_train, y_train)
print (accuracy_score(y_test, clf_vc.predict(X_test)))
plot_learning_curve(clf_vc, 'Ensemble', X, y, cv=4);
ensemble, 0.825112107623
6. Prediction
用最后训练好的 model 去预测给出的测试集文件,并把数据按照指定格式做好,存进 csv 提交即可。
def submission(model, fname, X):
ans = pd.DataFrame(columns=['PassengerId', 'Survived'])
ans.PassengerId = PassengerId
ans.Survived = pd.Series(model.predict(X), index=ans.index)
ans.to_csv(fname, index=False)
历史技术博文链接汇总
我是 不会停的蜗牛 Alice
85后全职主妇
喜欢人工智能,行动派
创造力,思考力,学习力提升修炼进行中
欢迎您的喜欢,关注和评论!