简单的opencv-python的总结
好久没写博客了,总结一下过年之后一直在做的一个事情。其实很简单,就是一个图片上面文字的提取工作。
其实这个总结相当于对于一些常用的Opencv -python的总结吧。好了,here we go !!!
1.滤波
平滑均值滤波(不过这个用的有点少……)原理很简单,就是……平均……好吧,这个所有图像处理的课都会提到。而且,超级简单,我就不废话了。
dst =cv2.blur(img, (5,5))
盒式滤波 一个类似矩阵形式滤波的均值值滤波器,其实大概可以当做是算法加速的均值滤波
dst = cv2.boxFilter(im,-1,(rad,rad)) -1:代表是原图深度,rad是盒式的范围
中值滤波(这个也超简单)原理就是排序,取中间的值作为该像素的值。但是!!!但是!!!!划重点!!!!这个超级超级超级有用,别看它原理超简单,而且基本所有课都会讲到,感觉跟上边那个差不多,但是!!!但是!!!这个真的超级超级有用!!特别是对于那种是你自己用摄像头拍出来的图像,它的去噪声能力比高斯滤波和双边滤波……还有什么很牛逼的滤波都来的好用的太多了,太多了!!!然后!!我前两天听了一个大牛的课(https://www.bilibili.com/video/av25755767/?p=2)其中他讲到了这个中值滤波,这个中值滤波对于椒盐噪声的滤波能力超好,这个椒盐噪声主要来源就是摄像头传感器内部电路脉冲!!!所以,来吧,向曾经鄙视过中值滤波的自己说句MMP吧……
im = cv2.medianBlur(im,5) 这个5就是中值滤波的尺度,尺度这种超参数,怎么设置就看你自己手气和微调了。手气好,一次就很好用,非酋就微调几次吧,不出意外不会超过9这样的,一般不是3,就是5 就已经很好了。
高斯滤波(这个实在太常用了)一般处理的是高斯噪声,基本上高斯噪声无处不在。
im = cv2.GaussianBlur(im,(3,3),0.7) 同样的(3,3)是尺度,0.7简单来讲就是滤波强度,越大,图片越模糊。
双边滤波(这个也很常用),但是!!!但是,这个有一个很难以克服的问题就是它的计算速度实在是太慢了,而且讲道理,我使用过opencv自封装的双边滤波函数,感觉是跟高斯滤波加上图像锐化的感觉差不多,但是问题是,高斯滤波加图像锐化两个函数的运行速度比双边滤波快太多了。感觉是有点划不来的。啊,双边滤波的原理:通俗来讲就是一个空间上的高斯滤波加上像素上的高斯滤波。双边滤波的权重不仅考虑了空间的欧式距离也考虑了像素的欧式距离的原因就是因为双边滤波就是一个空间上的高斯滤波加上像素上的高斯滤波。
im = cv2.bilateralFilter(im,150,3,3) 150是在像素域上的参数,该值越大,表示颜色相差越大的颜色会混合在一起;(3,3)就是高斯的宽度。
引导滤波 去雾算法之一 感觉有种快速双边滤波的感觉,在滤波的基础上这个算法大概率保留了图像的细节和边缘信息。它主要考的是引导图来判断原图的梯度从而保留其边缘信息。一般用的时候是使原图和引导图相同的,这样在像素变化小的区域,相当于是一个加权的均值滤波器;在像素变化大的区域,滤波效果减小,即保留其信息。
参考原理:https://blog.csdn.net/lxy201700/article/details/25136651
代码网上找找还是有的
2.频域上的滤波
其实频域上的滤波我实在用的不多。这里提及到这个主要是因为有一个思想和CNN中池化的思想差不多,但是是属于频域的应用,那就是——高斯金字塔
高斯金字塔主要是用于图像的大小压缩,主要是使得图像在缩小的情况下能尽量保留有效信息,即图像的低频信息。我们都是知道,图像的高频信息保留的是图像的细节,就是变化很大的地方;而图像的低频信息保留的则是图像的轮廓,即图像的基本内容。
高斯金字塔的原理就是低通滤波器滤波,然后对图像进行抽样。如此就能保证其在小图像上仍具有图像的基本信息。
CNN中池化的思想和它差不多。
根据高斯金字塔提出了拉布拉斯金字塔用于缩小的图像复原的算法。(具体算法……我没用过,理论参考上面那个网址)
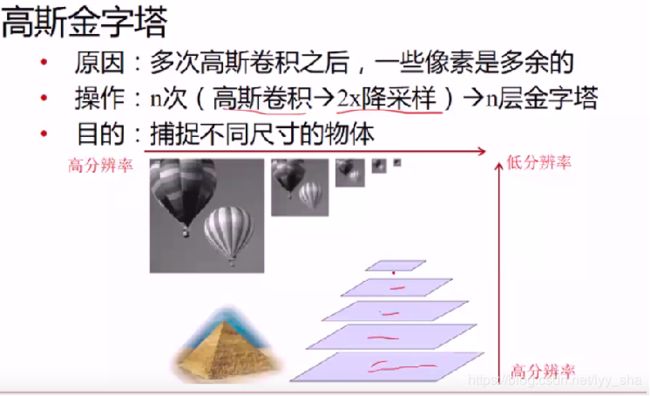
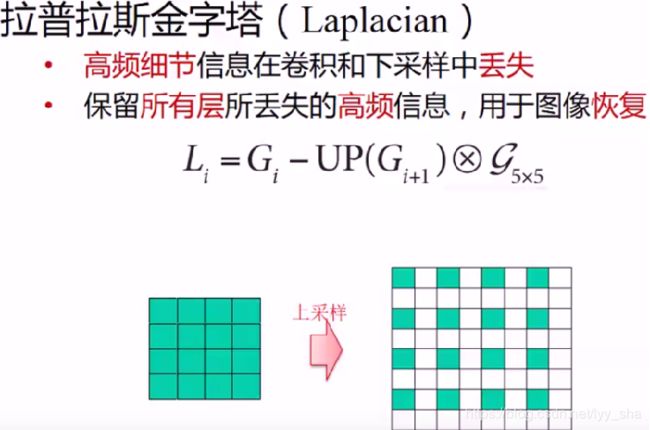
python-opencv 中的resize 用的就是高斯金字塔的思想。
3.关于直方图
直方图不仅仅只有灰度直方图一种,事实上梯度直方图也很常用。梯度直方图指的是在该点上的梯度值。
梯度直方图常用于特征匹配方面,特别是关键点和兴趣点以及纹理特征方面。
4.关于聚类
最常用的是kmeans 算法,但是由于kmeans的计算迭代次数多,且常限于局部最优解,所以有了kmeans++算法。依旧参考上面那个网址的讲课视频。



5.canny
另外一个常用的是canny边缘检测器,这个基本上是霍夫变换的标配了。
edges = cv2.Canny(image, 50, 70, apertureSize=3) 其中50,70是两个边缘像素的阈值。
梯度像素>70: 强边缘像素;50<梯度像素<70:弱边缘像素; 梯度像素<50:被抑制;
apertureSize 指边缘检测器的大小。canny使用非极大值抑制的方法来判断弱边缘像素是不是该图像的边缘信息。这个方法使得canny不像sobel算法一样,使得canny对于图像的边缘信息定位准确,而又不像laplacian 算子那样对图像的噪声十分敏感。
但同样由于该算法的原理性问题,使得该边缘检测出来的边缘线经常是断裂的。所以这个时候就需要用膨胀算法对检测得到的边缘进行膨胀,随后再使用霍夫变换得到霍夫线。
6.ostu 阈值分割法
ret2,th2 = cv2.threshold(img,0,255,cv2.THRESH_BINARY+cv2.THRESH_OTSU)
该算法的方法为:
1)先计算图像的直方图,即将图像所有的像素点按照0~255共256个bin,统计落在每个bin的像素点数量
2) 归一化直方图,也即将每个bin中像素点数量除以总的像素点
3) i表示分类的阈值,也即一个灰度级,从0开始迭代
4) 通过归一化的直方图,统计0~i 灰度级的像素(假设像素值在此范围的像素叫做前景像素) 所占整幅图像的比例w0,并统计前景像素的平均灰度u0;统计i~255灰度级的像素(假设像素值在此范围的像素叫做背景像素) 所占整幅图像的比例w1,并统计背景像素的平均灰度u1;
5) 计算前景像素和背景像素的方差 g = w0*w1*(u0-u1) (u0-u1)
6) i++;转到4),直到i为256时结束迭代
7)将最大g相应的i值作为图像的全局阈值
这个也是网上找来的,其主要的思想就是因为图像的背景和物体之间的灰度值差值最大,所以需要迭代来找到这个最大的阈值的分割线。
这个分割方法比自适应的阈值分割法好用,因为自适应的局部阈值分割的原理使得二值化的图像会有许多不必要的小块,而OSTU并没有这方面的困扰,该阈值分割出来的二值图相对简洁,整齐。
6.regionprops属性
在python-opencv中连通域的筛选是通过label标记之后,根据连通域的属性进行筛选的,该属性有:
参考网址为:https://wenku.baidu.com/view/2c1a1df285868762caaedd3383c4bb4cf7ecb78c.html

反正很多了,下面是使用连通域筛选的代码:
label_img =measure.label(label)
props = measure.regionprops(label_img)
for prop in props:
area_list.append(prop.area)
id_max = np.argmax(area_list)
res[label_img == id_max+1] = 0
7.膨胀腐蚀
kernel = np.ones((5,5),np.uint8)
dst= cv2.erode(im,kernel) 这个是腐蚀
dst= cv2.dilate(im,kernel)这个是膨胀
opening=cv2.morphologyEx(th3, cv2.MORPH_OPEN, kernel)这个是开运算
closed=cv2.morphologyEx(th3, cv2.MORPH_CLOSE, kernel)这个是关用算
还有个图像锐化:
im =ImageEnhance.Sharpness (im).enhance(15.0)
这个图像锐化要注意的是im不是一个数组类型,im是个图像类型的数据。所以在滤波完需要锐化什么的还需要把数组类型的图像变回图片类型的图像。
im = Image.fromarray(im, mode='L') 就是这个函数啦
以上就是基本上图像处理会用到的所有函数了,剩下的就是超参数的设置了。祝各位图像处理愉快!!!