tensorflow2.0 Post-training quantization
因为tensorflow2.0版本对比tensorflow1.0版本变化较大,所支持的量化方式方法都有所改变,所以重新写一篇文档记录。
先附上官方文档:
https://www.tensorflow.org/lite/performance/post_training_quantization?hl=en
因为aware-quantization操作实现起来较为复杂,所以这篇文章重点简述Post-training quantization。如果要了解aware-quantization,最好把版本更新退回至1.6版本。具体使用文档可看我另一篇文档:
https://blog.csdn.net/qq_16564093/article/details/78996563
先介绍下Post-training quantization,Post-training quantization是在损失一点精度的情况下,使模型的大小得到缩小,同时,在CPU,硬件上的运行速度也得到相应的提高。
Post-training quantization可分为以下三种方式:

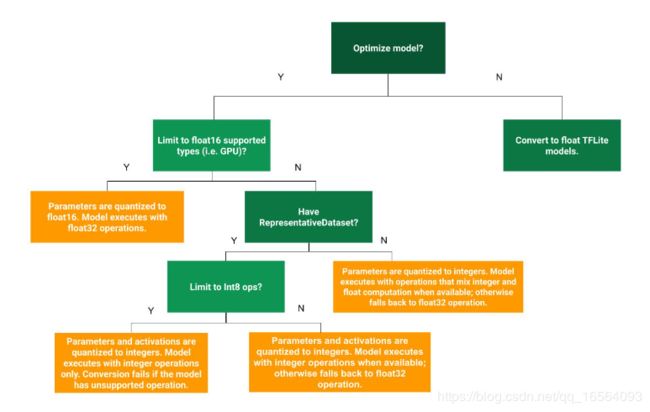
先简单分别介绍一下:
weight quantization:
将模型weight从float转换成8bits,在计算过程中依然使用float进行运算,而为了加快速度,对于某些activation ops,使用8bits进行激活,计算结果再转换成float。
Full integer quantization:
将模型weight完全从float转换成8bits,即使在计算过程中依然使用8bits进行运算,速度得到明显提高,但需要一个代表性的数据集去测量每一层输入及激活的数值范围。而对于不支持8bits的op或者不支持8bits运算的加速器,则会在计算过程中将8bite反量化成float去计算。
Float16 quantization:
将模型weight完全从float32转换成float16,即使在计算过程中依然使用float16进行运算,但只有在支持float16运算的GPU上才会使用float16进行运算,不然在CPU上,依然转换回float32进行运算。
接下来代码实现:
convert model to tflite:
#直接将模型转换成lite模型,不进行量化处理
model = tf.keras.models.load_model('model.h5')
converter = tf.lite.TFLiteConverter.from_keras_model(model)
tflite_model = converter.convert()
f = open('save/pruned_final_model.tflite','wb')
f.write(tflite_model)
f.close()weight quantization:
model = tf.keras.models.load_model('model.h5')
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.optimizations = [tf.lite.Optimize.OPTIMIZE_FOR_SIZE]
tflite_quant_weight_model = converter.convert()
f = open('tflite_quant_weight_model.tflite','wb')
f.write(tflite_quant_weight_model)
f.close()Full integer quantization:
# 生成代表性数据集
def get_representative_dataset_gen():
path = '/dataSet/'
imgSet = [os.path.join(path, f) for f in os.listdir(path) if os.path.isfile(os.path.join(path, f))]
for name in imgSet:
img = Image.open(name)
img = np.array(img.resize((224,224)))
img = (img/255.0)
img = np.array([img.astype('float32')])
yield [img]
#如果使用官方文档提供的下面的converter获取方法,会发现,最后转成出来的lite模型的输入依然为float类型。
#converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter = tf.compat.v1.lite.TFLiteConverter.from_keras_model_file('model.h5')
converter.representative_dataset = get_representative_dataset_gen
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
converter.inference_input_type = tf.uint8
converter.inference_output_type = tf.uint8
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_quant_integer_model = converter.convert()
import pathlib
tflite_quant_integer_model_dir = pathlib.Path('tflite_quant_integer_model.tflite')
tflite_quant_integer_model_dir.write_bytes(tflite_quant_integer_model)Float16 quantization:
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_types = [tf.compat.v1.lite.constants.FLOAT16]
tflite_fp16_model = converter.convert()
import pathlib
tflite_quant_fp16_model_dir = pathlib.Path('tflite_quant_fp16_model.lite')
tflite_quant_fp16_model_dir.write_bytes(tflite_fp16_model)
tflite模型的python调用方法如下:
def eval_model(interpreter,input_index,output_index,img):
interpreter.set_tensor(input_index, img)
interpreter.invoke()
predictions = interpreter.get_tensor(output_index)
return predictions
def get_interpreter(path):
interpreter = tf.lite.Interpreter(model_path=path)
interpreter.allocate_tensors()
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
input_index = input_details[0]["index"]
output_index = output_details[0]["index"]
return (interpreter,input_index,output_index)
interpreter , input_index , output_index = get_interpreter('model.tflite')
result = eval_model(interpreter,input_index,output_index,img)
print (result)
讲过测试:
model_size:
Float16 quant > weight quant ~ Full integer quant
speed:
Float16 quant > weight quant > Full integer quant
至于为什么 Full integer quant速度反而最慢,我猜测是因为我的环境是CPU,他们得不到速度的提升,反而在推导过程中,还需要把8bit转换成float,消耗时间。