Cracer渗透视频课程学习笔记——信息搜集
信息搜集
渗透一个网站收集这部分信息基本就够用了。

常用渗透测试系统:Back track5 ,parrot(新出来的),Kali(最好用的使用的人最多的)
一、DNS收集
域名--IP收集:
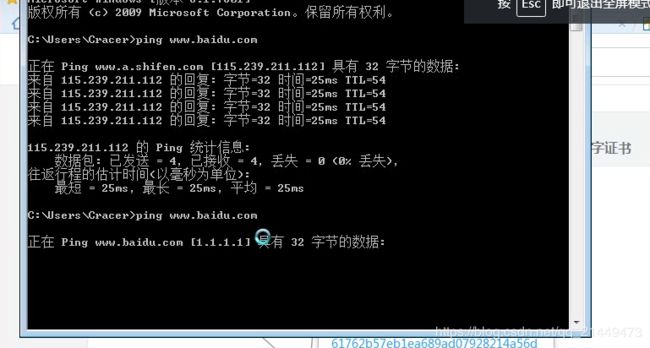
- 相关域名对应ip,相关工具:nslookup、一些工具网站
子域名收集:
- 工具:layer、subDomainsBrute

whois查询:
- 站长工具:http://tool.chinaz.com/ 爱站网
netcraft:http://searchdns.netcraft.com(国外的工具型网站)
DNS--IP 查询
查询内容 查询工具
主机【A】记录 站长之家
别名【CNAME】 Netcraft
主机信息【HINFO】 Dnsenum
邮件交换器【MK】 Dig
指针记录【PTP】 Lbd
服务记录【SKV】
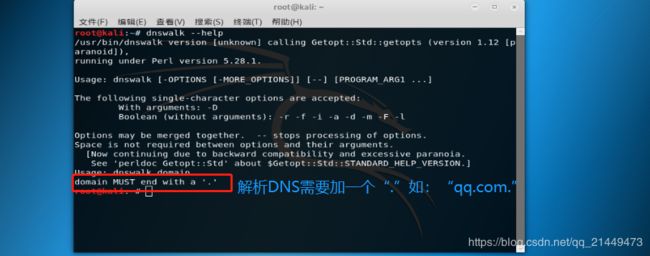
Kali里面解析DNS工具:
dnswalk:
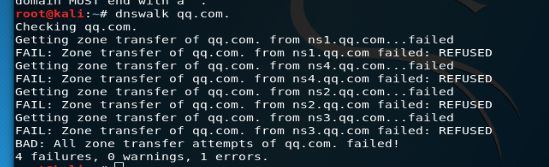
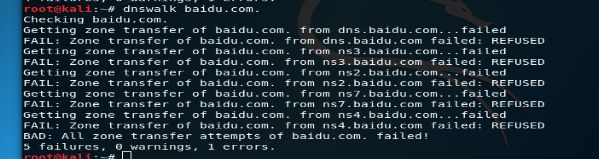
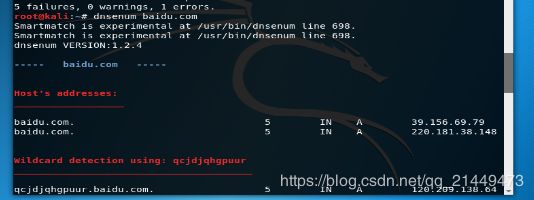
dnsenum:
小知识:如何查看kali里面关于DNS的工具输入dns按下两次tab键就会出来如下的界面

通过kali进行Whois查询 :例如:whois baidu.com 不用输入主机名,直接域名就可以了,前面www就不需要了
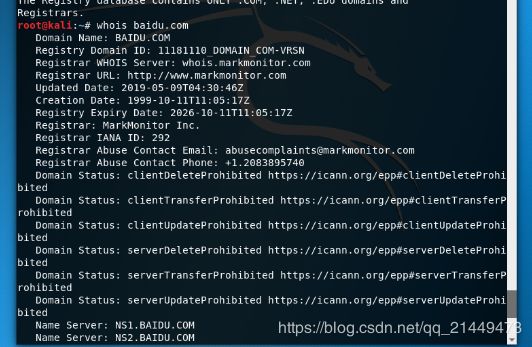
whois查询
(1)根据已知域名反查,分析此域名的注册人、邮箱、电话等字段,执行以下(2)至(5)反查方式
(2)根据已知域名WHOIS中注册邮箱来反查得出其他域名WHOIS中注册邮箱与此相同的域名列表
(3)根据已知域名WHOIS中的注册人来反查得出其他域名WHOIS中注册人与此相同的域名列表;
(4)根据已知域名WHOIS中联系电弧来反查得出其他域名WHOIS中联系电话与此相同域名列表;
(5)其他反查方式:比如可以根据注册机构、传真、地址、注册商等等方式来反查。
二、敏感目录收集
-
收集方向 常用工具
- mysql管理接口 wwwscan
- 后台目录 御剑
- 上传目录 Cansina
- phpinfo burpsuit
- robots.txt webrobot
- 安装包 skipfish
- 安装界面 uniscan
- 爬行 websploit
实战案例:搜索曲阜团,在网址后面加上“/manage/”会发现出来管理界面
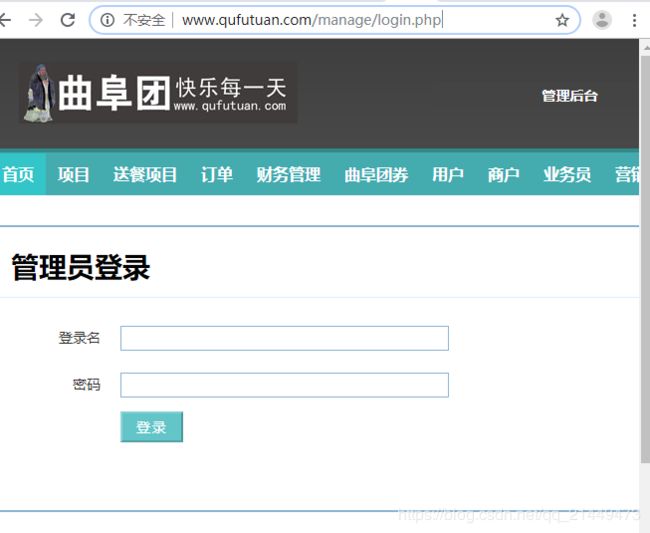
用工具包御剑进行目录扫描,两个御剑


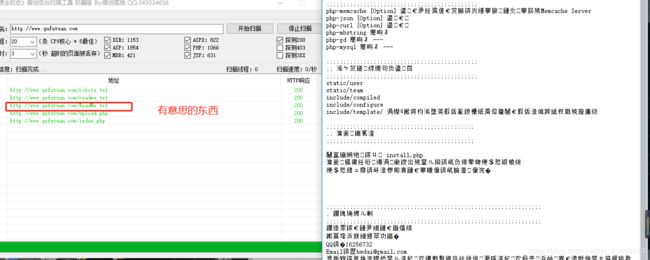
WeRobot使用:
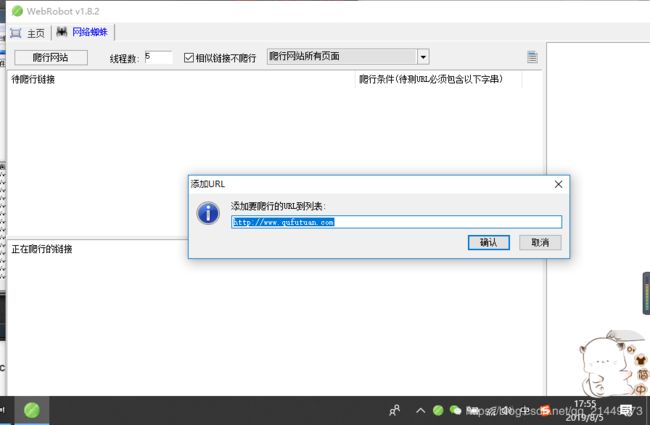
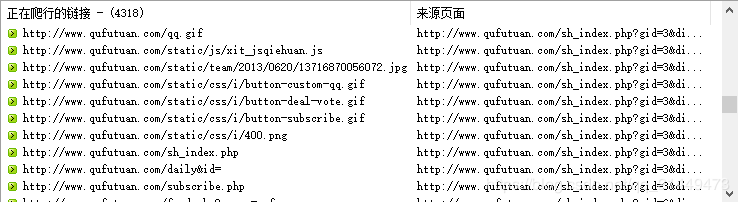
然后点击链接,点击开始爬行

之后下面就开始爬行数据了
skipfishs的使用:这是一个在kali里面的命令
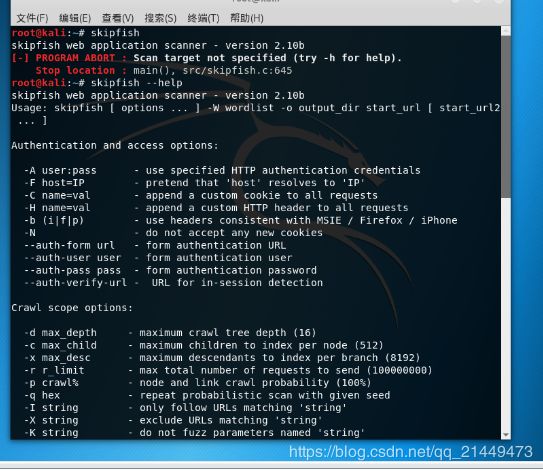
skipfish web application scanner - version 2.10b
Usage: /home/admin/workspace/skipfish/skipfish [ options ... ] -W wordlist -o output_dir start_url [ start_url2 ... ]
Authentication and access options:
验证和访问选项:
-A user:pass - use specified HTTP authentication credentials
使用特定的http验证
-F host=IP - pretend that 'host' resolves to 'IP'
-C name=val - append a custom cookie to all requests
对所有请求添加一个自定的cookie
-H name=val - append a custom HTTP header to all requests
对所有请求添加一个自定的http请求头
-b (i|f|p) - use headers consistent with MSIE / Firefox / iPhone
伪装成IE/FIREFOX/IPHONE的浏览器
-N - do not accept any new cookies
不允许新的cookies
--auth-form url - form authentication URL
--auth-user user - form authentication user
--auth-pass pass - form authentication password
--auth-verify-url - URL for in-session detection
Crawl scope options:
-d max_depth - maximum crawl tree depth (16)最大抓取深度
-c max_child - maximum children to index per node (512)最大抓取节点
-x max_desc - maximum descendants to index per branch (8192)每个索引分支抓取后代数
-r r_limit - max total number of requests to send (100000000)最大请求数量
-p crawl% - node and link crawl probability (100%) 节点连接抓取几率
-q hex - repeat probabilistic scan with given seed
-I string - only follow URLs matching 'string' URL必须匹配字符串
-X string - exclude URLs matching 'string' URL排除字符串
-K string - do not fuzz parameters named 'string'
-D domain - crawl cross-site links to another domain 跨域扫描
-B domain - trust, but do not crawl, another domain
-Z - do not descend into 5xx locations 5xx错误时不再抓取
-O - do not submit any forms 不尝试提交表单
-P - do not parse HTML, etc, to find new links 不解析HTML查找连接
Reporting options:
-o dir - write output to specified directory (required)
-M - log warnings about mixed content / non-SSL passwords
-E - log all HTTP/1.0 / HTTP/1.1 caching intent mismatches
-U - log all external URLs and e-mails seen
-Q - completely suppress duplicate nodes in reports
-u - be quiet, disable realtime progress stats
-v - enable runtime logging (to stderr)
Dictionary management options:
-W wordlist - use a specified read-write wordlist (required)
-S wordlist - load a supplemental read-only wordlist
-L - do not auto-learn new keywords for the site
-Y - do not fuzz extensions in directory brute-force
-R age - purge words hit more than 'age' scans ago
-T name=val - add new form auto-fill rule
-G max_guess - maximum number of keyword guesses to keep (256)
-z sigfile - load signatures from this file
Performance settings:
-g max_conn - max simultaneous TCP connections, global (40) 最大全局TCP链接
-m host_conn - max simultaneous connections, per target IP (10) 最大链接/目标IP
-f max_fail - max number of consecutive HTTP errors (100) 最大http错误
-t req_tmout - total request response timeout (20 s) 请求超时时间
-w rw_tmout - individual network I/O timeout (10 s)
-i idle_tmout - timeout on idle HTTP connections (10 s)
-s s_limit - response size limit (400000 B) 限制大小
-e - do not keep binary responses for reporting 不报告二进制响应
Other settings:
-l max_req - max requests per second (0.000000)
-k duration - stop scanning after the given duration h:m:s
--config file - load the specified configuration file
Send comments and complaints to . 使用例子:skipfish -o cracer http://www.cracer.com
扫描成功会有一个html文件,查看这个文件就好

三、端口扫描:

以下为网上找的常用端口介绍部分:https://www.jianshu.com/p/fed5dcdeadd5
| 端口类型 | 端口号 |
|---|---|
| IMAP 常规端口 | 143 |
| POP3 常规端口 | 110 |
| SMTP 常规端口 | 25 |
| IMAP SSL 端口 | 993 |
| POP3 SSL 端口 | 995 |
| SMTP SSL 端口 | 465 |
本文介绍端口的概念,分类,以及如何关闭/开启一个端口。
| 端口 | 作用说明 |
|---|---|
| 21 | 21端口主要用于FTP(File Transfer Protocol,文件传输协议)服务。 |
| 23 | 23端口主要用于Telnet(远程登录)服务,是Internet上普遍采用的登录和仿真程序。 |
| 25 | 25端口为SMTP(Simple Mail Transfer Protocol,简单邮件传输协议)服务器所开放,主要用于发送邮件,如今绝大多数邮件服务器都使用该协议。 |
| 53 | 53端口为DNS(Domain Name Server,域名服务器)服务器所开放,主要用于域名解析,DNS服务在NT系统中使用的最为广泛。 |
| 67、68 | 67、68端口分别是为Bootp服务的Bootstrap Protocol Server(引导程序协议服务端)和Bootstrap Protocol Client(引导程序协议客户端)开放的端口。 |
| 69 | TFTP是Cisco公司开发的一个简单文件传输协议,类似于FTP。 |
| 79 | 79端口是为Finger服务开放的,主要用于查询远程主机在线用户、操作系统类型以及是否缓冲区溢出等用户的详细信息。 |
| 80 | 80端口是为HTTP(HyperText Transport Protocol,超文本传输协议)开放的,这是上网冲浪使用最多的协议,主要用于在WWW(World WideWeb,万维网)服务上传输信息的协议。 |
| 99 | 99端口是用于一个名为“Metagram Relay”(亚对策延时)的服务,该服务比较少见,一般是用不到的。 |
| 109、110 | 109端口是为POP2(Post Office Protocol Version 2,邮局协议2)服务开放的,110端口是为POP3(邮件协议3)服务开放的,POP2、POP3都是主要用于接收邮件的。 |
| 111 | 111端口是SUN公司的RPC(Remote ProcedureCall,远程过程调用)服务所开放的端口,主要用于分布式系统中不同计算机的内部进程通信,RPC在多种网络服务中都是很重要的组件。 |
| 113 | 113端口主要用于Windows的“Authentication Service”(验证服务)。 119端口:119端口是为“Network News TransferProtocol”(网络新闻组传输协议,简称NNTP)开放的。 |
| 135 | 135端口主要用于使用RPC(Remote Procedure Call,远程过程调用)协议并提供DCOM(分布式组件对象模型)服务。 |
| 137 | 137端口主要用于“NetBIOS Name Service”(NetBIOS名称服务)。 |
| 139 | 139端口是为“NetBIOS Session Service”提供的,主要用于提供Windows文件和打印机共享以及Unix中的Samba服务。 |
| 143 | 143端口主要是用于“Internet Message Access Protocol”v2(Internet消息访问协议,简称IMAP)。 |
| 161 | 161端口是用于“Simple Network Management Protocol”(简单网络管理协议,简称SNMP)。 |
| 443 | 443端口即网页浏览端口,主要是用于HTTPS服务,是提供加密和通过安全端口传输的另一种HTTP。 |
| 554 | 554端口默认情况下用于“Real Time Streaming Protocol”(实时流协议,简称RTSP)。 |
| 1024 | 1024端口一般不固定分配给某个服务,在英文中的解释是“Reserved”(保留)。 |
| 1080 | 1080端口是Socks代理服务使用的端口,大家平时上网使用的WWW服务使用的是HTTP协议的代理服务。 |
| 1755 | 1755端口默认情况下用于“Microsoft Media Server”(微软媒体服务器,简称MMS)。 |
| 4000 | 4000端口是用于大家经常使用的QQ聊天工具的,再细说就是为QQ客户端开放的端口,QQ服务端使用的端口是8000。 |
| 5554 | 在今年4月30日就报道出现了一种针对微软lsass服务的新蠕虫病毒——震荡波(Worm.Sasser),该病毒可以利用TCP 5554端口开启一个FTP服务,主要被用于病毒的传播。 |
| 5632 | 5632端口是被大家所熟悉的远程控制软件pcAnywhere所开启的端口。 |
| 8080 | 8080端口同80端口,是被用于WWW代理服务的,可以实现网页。 |
【端口概念】
在网络技术中,端口(Port)大致有两种意思:一是物理意义上的端口,比如,ADSL Modem、集线器、交换机、路由器用于连接其他网络设备的接口,如RJ-45端口、SC端口等等。二是逻辑意义上的端口,一般是指TCP/IP协议中的端口,端口号的范围从0到65535,比如用于浏览网页服务的80端口,用于FTP服务的21端口等等。我们这里将要介绍的就是逻辑意义上的端口。
【端口分类】
逻辑意义上的端口有多种分类标准,下面将介绍两种常见的分类:
1、 按端口号分布划分
(1)知名端口(Well-Known Ports)
知名端口即众所周知的端口号,范围从0到1023,这些端口号一般固定分配给一些服务。比如21端口分配给FTP服务,25端口分配给SMTP(简单邮件传输协议)服务,80端口分配给HTTP服务,135端口分配给RPC(远程过程调用)服务等等。
(2)动态端口(Dynamic Ports)
动态端口的范围从1024到65535,这些端口号一般不固定分配给某个服务,也就是说许多服务都可以使用这些端口。只要运行的程序向系统提出访问网络的申请,那么系统就可以从这些端口号中分配一个供该程序使用。比如1024端口就是分配给第一个向系统发出申请的程序。在关闭程序进程后,就会释放所占用的端口号。
不过,动态端口也常常被病毒木马程序所利用,如冰河默认连接端口是7626、WAY 2.4是8011、Netspy 3.0是7306、YAI病毒是1024等等。
2、按协议类型划分
按协议类型划分,可以分为TCP、UDP、IP和ICMP(Internet控制消息协议)等端口。下面主要介绍TCP和UDP端口:
(1)TCP端口
TCP端口,即传输控制协议端口,需要在客户端和服务器之间建立连接,这样可以提供可靠的数据传输。常见的包括FTP服务的21端口,Telnet服务的23端口,SMTP服务的25端口,以及HTTP服务的80端口等等。
(2)UDP端口
UDP端口,即用户数据包协议端口,无需在客户端和服务器之间建立连接,安全性得不到保障。常见的有DNS服务的53端口,SNMP(简单网络管理协议)服务的161端口,QQ使用的8000和4000端口等等。
【查看端口】
在Windows 2000/XP/Server 2003中要查看端口,可以使用Netstat命令: 依次点击“开始→运行”,键入“cmd”并回车,打开命令提示符窗口。在命令提示符状态下键入
netstat -a -n
按下回车键后就可以看到以数字形式显示的TCP和UDP连接的端口号及状态(如图)。
小知识:Netstat命令用法
命令格式:
Netstat -a -e -n -o -s
-a 表示显示所有活动的TCP连接以及计算机监听的TCP和UDP端口。
关于扫描工具ScanPort使用:
四、旁站C段
- 旁站:同服务器其他站点
- C段:同一网段其他服务器
- 常用工具:
- web>>K8旁站、御剑1.5
- 端口>>portscan
五、整站分析
-
服务器类型
-
服务器平台、版本等
-
- 网站容器
- 搭建网址的服务组件,例如:iis、Apache、nginx、tomcat
- 脚本类型
- ASP、PHP、JSP、ASPX等
- 数据库类型
- access、sqlserver、mysql、oracle、postgresql
- CMS类型
- WAF
六、谷歌hacker
- 1. Intext:(有些管理员登陆在网页中显示)
- 查找网页中含有XX关键字的网址 例:Intext:管理员登陆
- 2. Intitle:(有些管理员登陆在标题中显示)
- 查找某个标题 例:intitle 后台登陆
- 3. Filetype:
- 查找某个文件类型的文件 例:数据挖掘filetype
- 4. Inurl
- 查找url中带有某字段的网站 例:inurl:php?id=
- 5. Site:
- 在某域名中查找信息
七、URL采集
- 采集相关url的同类网站
- 例如
- php?id=
- 漏洞网站
- 相同某种指纹网站
- 常用工具
- 谷歌hacker
- url采集器
八、后台查找
- 弱口令默认后台:admin,admin/login.asp,manage,login,asp等等常见后台
- 查看网页的链接:一般来说,网站的主页有管理登陆类似的东西,有些可能被管理员删除
- 查看网站图片的属性
- 查看网站使用的管理系统,从而确定后台
- 用工具查找:wwwscan,intellitamper,御剑
- robots.txt的帮助:robots.txt文件告诉蜘蛛程序在服务器上什么样的文件可以被查看
- GoogleHacker
- 查看网站使用的编辑器是否有默认后台
- 短文件利用
- sqlmap -sql-shell load_file('d:/wwwroot/index.php')
九、CDN绕过方法
- 什么是CDN
- 如何判断网站有没使用CDN(超级ping)
- 查找二级域名
- 让服务器主动给你发包(邮件)
- 敏感文件泄露
- 查询历史解析IP(ip138,微步在线)


- 访问绕过cdn
- 修改hosts文件
当已经收集到真实IP修改hosts文件即可绕过CDN,如下目录找到hosts文件
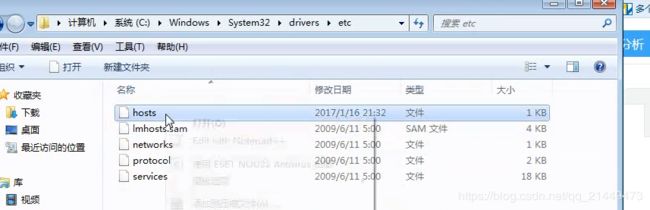
假设已知百度真实IP为1.1.1.1,如下修改然后在ping百度就会访问1.1.1.1,因为hosts解析域名优先级优先级高于dns