基于mini-db对索引的进一步思考以及分析比较fseek与fgets偏移光标的异同
这篇博客是这个栏目的第一篇文章,因此在此之前有必要介绍一下这个项目的大概情况。要求就是要通过C或C++实现一个简单的数据库,要有最基本的增删改查功能,之后要通过为字段创建索引数据结构提高SELECT查找的效率。项目链接:https://github.com/HuangFuGui/Software-engineering-practice/tree/master/mini-db
项目题公布后,很多小组有一个相同的想法就是,可以实现一个“内存”数据库,就是在最开始把磁盘文件的全部内容加载到内存中,所有的操作都是在内存进行,在最后把在内存中操作好的数据同步到磁盘中即可。确实这种方法是可以的,项目要求就是一个数据库中最多只有10张表,每个表最多10个字段,每个字段最多256个字符,还有就是每张表中最多10000条记录。这样算一下,不妨设表中的数据全是中文,中文的编码方式是GBK,一个中文字符占用2个字节。那么将数据库中的记录全部加载到内存中最多需要2*256*10*10000*10/(1024*1024) ≈ 48.83MB的空间,这个数值当然是可以接受的。使用“内存”数据库,所有的增删改查操作都在内存进行,没有跟磁盘打交道,效率当然高。但是我个人没有哪怕一点点的实现“内存”数据库的倾向,因为所谓的“内存”数据库必须建立在数据量不大的基础上,试想像Mysql,Oracle这样的数据库,难道会把全球多到无法估量的数据记录一次性载入内存进行处理吗?所以,我的想法就是,只有用户需要用到时,才将记录从磁盘文件中读取。
项目进行一个星期后,基本功能增删改查都实现了,附加功能也实现了一些,例如SELECT后多条件的与或非(AND,OR,NOT)查找。但目前为止的所有SELECT实现,都是内存对磁盘文件进行全盘扫描读取while(fgets(buffer,1024,file)!=NULL){//逻辑判断},每扫描一行,就会对该行进行预先写好的逻辑判断,判断该行是不是符合查找条件的记录,判断该行记录的哪几个字段是要显示给用户等…很多时候这样的FTS对WHERE查找是不够好的。例如有这样一个查找语句:SELECT id,username,address FROM client WHERE username = '黄复贵'; 现在就是对磁盘文件进行FTS将每一行记录读入内存(存在局部变量buffer字符型数组中,即栈,当使用完后就会被释放掉),经过一些特定的处理后得到这个记录的username字段,判断username是否为‘黄复贵’。如果是,就显示其中的三个字段;如果不是,就不显示,重复循环直至读完整个磁盘文件。当磁盘文件中有5000条数据但真正username=‘黄复贵’的记录只有4条时,就会有很多无谓的磁盘IO,以及多了很多本可以不用进行的字符型数组处理和逻辑判断。显然这样的SELECT查找有待优化,数据库中优化查找无非就是通过创建索引。索引数据结构记录下所有username为‘黄复贵’的记录的行号(第3行,第8行,第24行….),这样用户进行查找的时候就会先查找索引直接得到记录所在磁盘文件的行号,然后通过行号偏移磁盘文件中的光标(fseek),再直接fgets就可以得到想要的记录,这样就会减少很多无谓的磁盘IO以及多余的字符处理和逻辑判断时间,而且索引说白了其实就是排好序的数据结构,遍历时间复杂度一般都比FTS的O(n)小。
但话说回来,索引本不应该存数据所在磁盘文件的行号。索引存的应该是数据记录的物理地址(在存储器里以字节为单位存储信息,为正确地存放或取得信息,每一个字节单元给以一个唯一的存储器地址)或是指针,通过物理地址或指针,就能一下定位到记录,这样就不需要fseek偏移光标了,毕竟fseek移光标也是需要一点时间的。但是没有办法,物理地址涉及到操作系统层面的东西,还没有上这门课目前不了解如果获取物理地址以及通过物理地址定位并获取数据;索引存数据记录的指针目前也无法实现,为内存中的块建立指针我会,但是怎么为磁盘中的数据记录建立指针并持久化到磁盘中,需要的时候怎样调用这些都不知道。所以退而求其次的办法就是索引中记录行号。
所以,在这个项目中索引存的是数据记录所在的行数以及每一行的字节数,有了这两个参数,就能使用fseek准确偏移光标,得到想要的数据行。但是我又思考一个问题,想要得到指定的行,除了fseek外,还可以for(j=0;j<18889;j++){fgets(buffer,1024,file);},虽然fseek没有磁盘IO,但是它的偏移效率怎么样?如果它的偏移效率还不如这个for循环的读取偏移,那fseek就没优势了。下面就比较fseek与循环fgets的偏移效率开始探索。
Debug fgets查看运行情况:
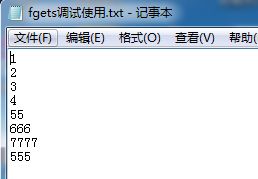
#includefgets调试使用.txt内容:
debug过程*file的信息:
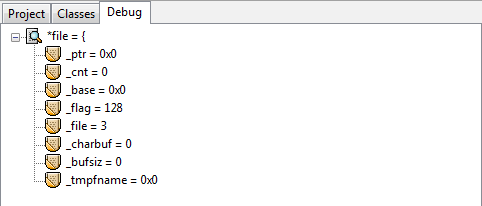
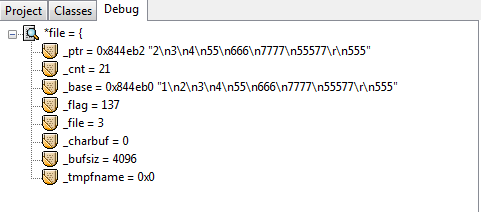
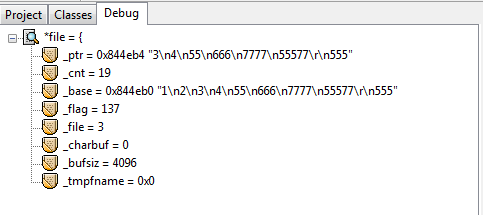
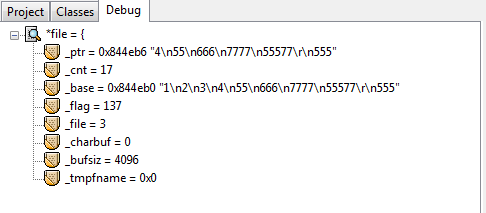
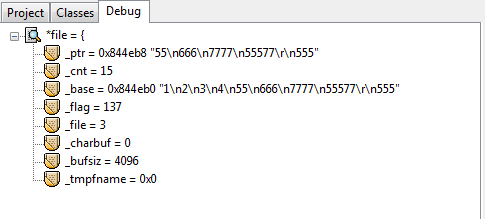
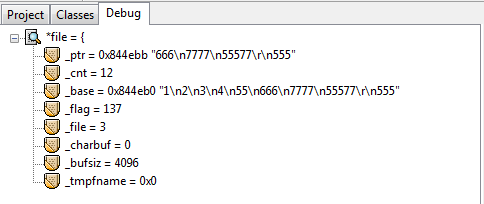
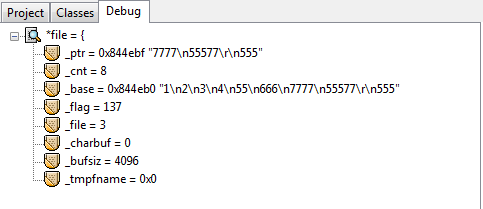
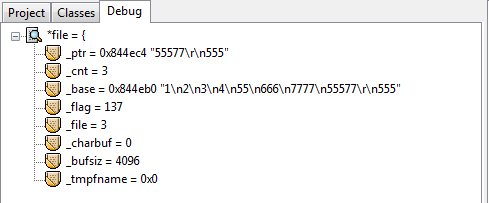
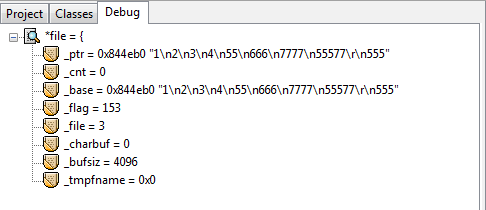
在这些debug信息中有一个很重要的观察点:_cnt,它的值从最大的21降为0。为什么是21呢,其实是这样的,首先文本中最后一行的555后是没有换行’\n’字符的,但是这样算来也是23个字符,比21多了两个。正是因为第一次显示debug信息的时候已经读了第一行了,所以少了2是预料之中。每往下fgets一行,这个_cnt就会减去当前被读行的总字节数。所以,fgets内部是可以计算当前行字节数的,并且也有一种偏移光标的效果使得每读一行就偏移掉当前被读行的总字节数。这么说来,用fseek也是偏移的效果,两者方式岂不是一样?因此不能确定fseek比循环的fgets偏移效率好,即使“循环”这个词总会给人一种效率低下的感觉。当前唯一能说出的区别就是循环的fgets偏移会有磁盘IO,仅此而已。
一:为了实际查看两者的偏移时间效率,我写了下面两个小程序:
fseek偏移:
#include
int main(){
FILE *file = fopen("比较fseek与fgets使用.txt","a+");
char buffer[1024] = "\0";
int i=0,j=0;
if(file!=NULL){
fseek(file,1567787,0);
fgets(buffer,1024,file);
printf("%s\n",buffer);
fclose(file);
}
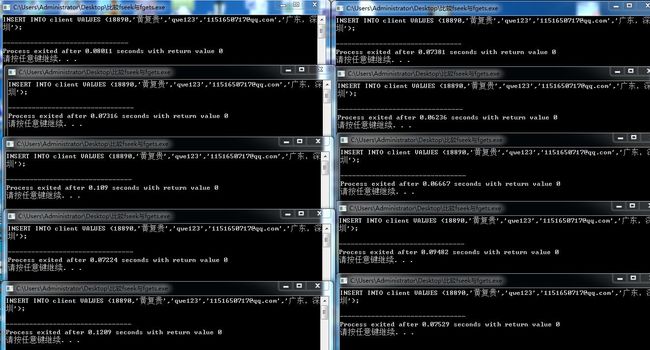
} 运行结果:
循环fgets偏移:
#include
int main(){
FILE *file = fopen("比较fseek与fgets使用.txt","a+");
char buffer[1024] = "\0";
int i=0,j=0;
if(file!=NULL){
for(j=0;j<18889;j++){
fgets(buffer,1024,file);
}
fgets(buffer,1024,file);
printf("%s\n",buffer);
fclose(file);
}
} 运行结果:
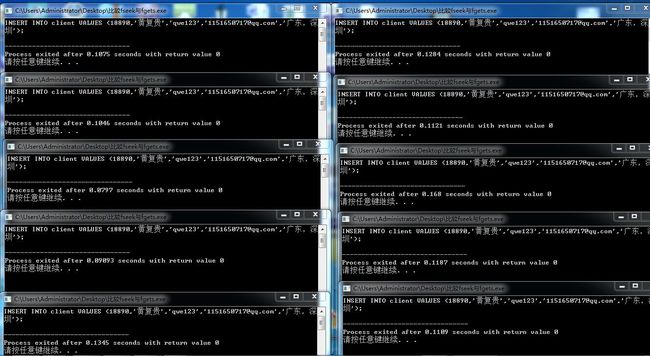
比较fseek与fgets使用.txt这个文本中共有18890条数据,前面18889条数据的每一行字节共有83个字节。fseek中的参数就是从0开始偏移,共偏移18889*83 = 1567787个字节,这样就会得到最后一行数据。
多次运行这两个程序,运行结果都相同,看程序执行完的时间,在共10次的运行下,fseek时间似乎优于循环的fgets,但是测试组数太小,所以这里用了“似乎”这个词,还是不能下结论。
二:在上述基础上循环进行100次初步制造压力:
fseek偏移:
#include
int main(){
FILE *file = fopen("比较fseek与fgets使用.txt","a+");
char buffer[1024] = "\0";
int i=0,j=0;
if(file!=NULL){
for(i=0;i<100;i++){
fseek(file,1567787,0);
fgets(buffer,1024,file);
printf("%s\n",buffer);
}
fclose(file);
}
} 运行结果:
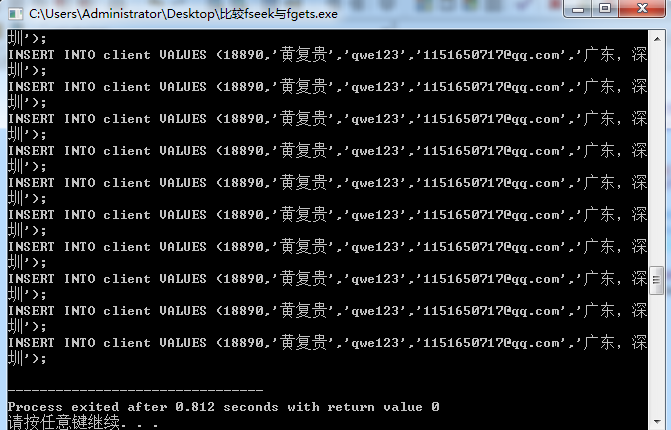
循环fgets偏移:
#include
int main(){
FILE *file = fopen("比较fseek与fgets使用.txt","a+");
char buffer[1024] = "\0";
int i=0,j=0;
if(file!=NULL){
for(i=0;i<100;i++){
for(j=0;j<18889;j++){
fgets(buffer,1024,file);
}
fgets(buffer,1024,file);
printf("%s\n",buffer);
}
fclose(file);
}
} 运行结果:
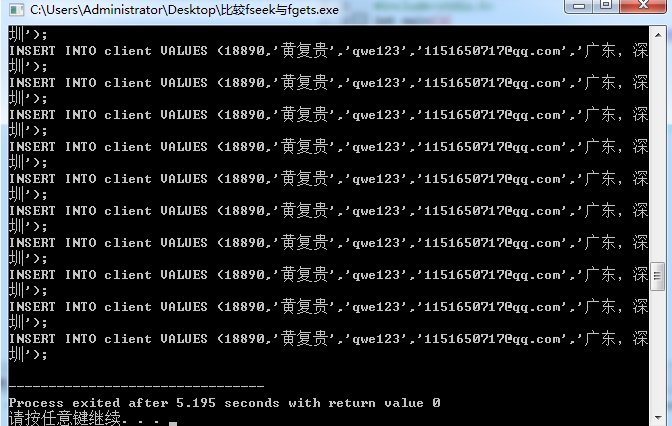
这种情况下,fseek偏移光标输出100条数据所用时间为0.812s,但循环的fgets偏移光标输出100条数据用了5.195s,这样看来,在有压力的情况下,有IO阻塞的循环fgets偏移光标处于劣势。
三:同时运行多个.exe模拟并发进一步制造压力:
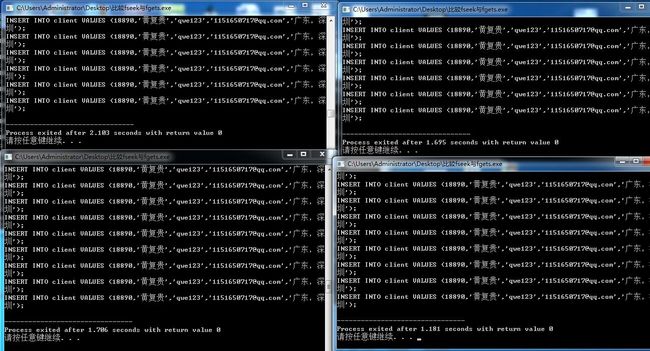
fseek运行结果:
循环fgets运行结果:
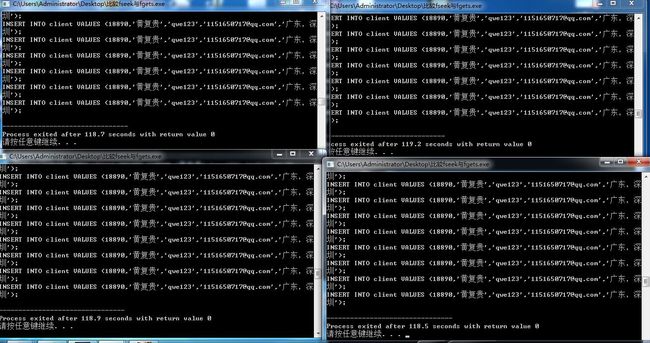
通过比较可以看到,在模拟并发的情况下,循环fgets偏移方式的磁盘IO缺点被再度放大,造成大量的阻塞,严重影响程序运行效率。因此现在可以下结论了。
总结:
1. fseek偏移与循环fgets偏移的方式本身就是一样的,都是由偏移量来控制光标的位置得到特定行。在单次执行情况下,二者效率没有差别,几乎一样,不能随便下定论二者谁更优。
2. 但在有压力的情况下,循环fgets偏移方式有磁盘IO的缺点就会被放大,放大的程度跟压力大小成正比。当IO过大(达到系统磁盘IO瓶颈)时,运行效率将大打折扣。这个时候,fseek更优。
3. 综上所述,该项目中索引记录的是数据记录在磁盘文件中的行号,并且通过fseek(file,offset,origin)的方式进行偏移得到指定数据。
如有问题或补充,请大家在评论中尽管提,共同交流^~^。