xv6源码分析—第一个用户进程
关于进程
进程是一个抽象概念,它让一个程序可以假设它独占一台机器。进程向程序提供“看上去”私有的,其他进程无法读写的内存空间,以及“看上去”仅执行该程序的CPU。xv6使用页表(硬件)来为每个进程提供其独有的地址空间,页表将虚拟地址映射为物理地址。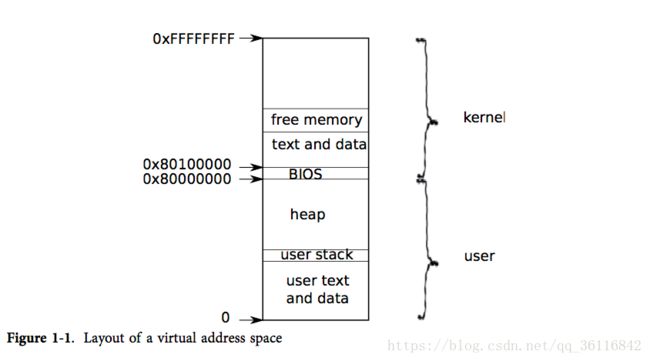
xv6为每个进程虚拟出一个0xFFFFFFFF的内存地址,包含了从虚拟地址0开始的用户内存。它的地址最低处放置进程的指令,接下来则是全局变量,栈区,以及用户可以按照需要扩展的“堆”区(malloc用)。
内核的指令和数据也会被映射到每个进程的地址空间中。当进程使用系统调用时,系统调用实际上会在进程地址空间的内核区域执行。这种设计使得内核的系统调用代码可以直接指向用户内存。为了给用户留下足够的内存空间,xv6将内核映射到了地址空间的高地址处,即从0x80100000开始。
xv6使用结构体struct proc来维护一个进程的众多状态。
// Per-process state
struct proc {
uint sz; // Size of process memory (bytes)
pde_t* pgdir; // Page table 页表
char *kstack; // Bottom of kernel stack for this process内核栈栈底
enum procstate state; // Process state 运行状态
int pid; // Process ID 进程号
struct proc *parent; // Parent process
struct trapframe *tf; // Trap frame for current syscall当前系统调用保存的寄存器
struct context *context; // swtch() here to run process进程切换的上下文信息
void *chan; // If non-zero, sleeping on chan
int killed; // If non-zero, have been killed
struct file *ofile[NOFILE]; // Open files
struct inode *cwd; // Current directory
char name[16]; // Process name (debugging)
};一个进程最为重要的状态是进程的页表,内核栈和当前运行状态。
每个进程都有一个运行线程(Thread)来执行进程的指令。线程可以被暂时挂起,稍后再恢复运行。系统在进程之间切换实际上就是挂起当前运行的线程,恢复另一个进程的线程。线程的大多数状态(局部变量和函数调用返回地址)都保存在线程的栈上。
每个进程都有用户栈和内核栈(p->kstack)。当进程运行用户指令时,只有其用户栈被使用,其内核栈则是空的。然而当进程(通过系统调用或中断)进入内核时,内核代码就在内核栈中执行。进程处于内核中时,其用户栈仍然保存着数据,只是暂时处于不活跃状态。进程的线程交替地使用着用户栈和内核栈。要注意内核栈是用户代码无法使用的,这样即使一个进程破坏了自己的用户栈,内核也能保持运行。
当进程使用系统调用时,处理器转入内核栈,提升硬件的特权级,然后运行系统调用对应的内核代码。当系统调用完成时,又从内核空间回到用户空间:降低硬件特权级,转入用户栈,恢复执行系统调用指令后面的那条用户指令。线程可以在内核中“阻塞”,等待I/O,在I/O结束后再恢复运行。
p->state指示了进程的状态:新建、就绪、运行、等待I/O或者退出状态中。
新建:进程正在被创建,尚未转到就绪状态。
就绪:进程已经获得了除处理机之外的一切所需资源。
运行:进程正在处理机上运行。
阻塞:进程正在等待某一事件而暂停运行。
退出:进程正从系统中消失,分为正常结束和异常退出。
第一个地址空间
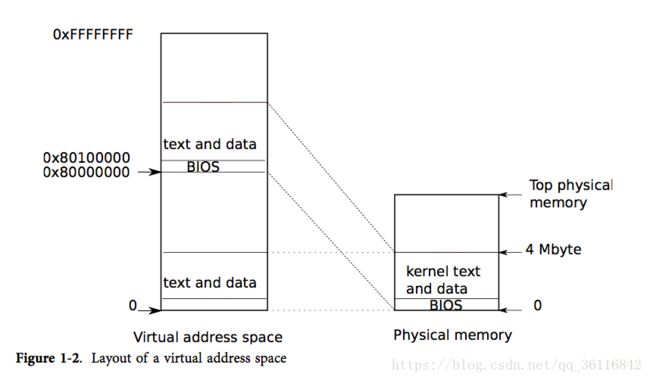
当PC开机时,它会初始化自己然后从磁盘中载入boot loader到内存并运行。然后,boot loader把xv6内核从磁盘中载入并从entry开始运行。xv6的分页硬件在此时还没有开始工作;所以这时的虚拟地址是直接映射到物理地址上的。
boot loader把x86内核装载到物理地址0x100000处。之所以没有装载到内核指令和内核数据应该出现的0x80100000,是因为小型机器上很可能没有这么大的物理内存。而之所以在0x100000而不是0x0则是因为地址0xa0000到0x100000是属于I/O设备的。
为了让内核的剩余部分能够运行,entry的代码设置了页表,将0x80000000开始的虚拟地址映射到物理地址到物理地址0x0处。
// The boot page table used in entry.S and entryother.S.
// Page directories (and page tables) must start on page boundaries,
// hence the __aligned__ attribute.
// PTE_PS in a page directory entry enables 4Mbyte pages.
__attribute__((__aligned__(PGSIZE)))
pde_t entrypgdir[NPDENTRIES] = {//pde_t uint
// Map VA's [0, 4MB) to PA's [0, 4MB)
[0] = (0) | PTE_P | PTE_W | PTE_PS,
// Map VA's [KERNBASE, KERNBASE+4MB) to PA's [0, 4MB)
[KERNBASE>>PDXSHIFT] = (0) | PTE_P | PTE_W | PTE_PS,
};entry中的页表的定义在main.c中,页表项0将虚拟地址0:0x400000映射到物理地址0:0x400000。只要entry的代码还运行在内存的低地址处,我们就必须这样设置,但最后这个页表项是会被移除的。页表项512将虚拟地址的KERNBASE:KERNBASE+0x400000映射到物理地址0:0x400000。这个页表项将在entry的代码结束后被使用;它将内核指令和内核数据应该出现的高虚拟地址处映射到了boot loader实际将它们载入的低物理地址处。这个映射就限制内核指令+代码必须在4MB以内。
entry:
# Turn on page size extension for 4Mbyte pages
#设置cr4,使用4M页,这样创建的页表比较简单
movl %cr4, %eax
orl $(CR4_PSE), %eax
movl %eax, %cr4
# Set page directory 将 entrypgdir 的物理地址载入到控制寄存器 %cr3 中
movl $(V2P_WO(entrypgdir)), %eax
movl %eax, %cr3
# Turn on paging. 开启分页
movl %cr0, %eax
orl $(CR0_PG|CR0_WP), %eax
movl %eax, %cr0
# Set up the stack pointer.创建CPU栈
movl $(stack + KSTACKSIZE), %esp
# Jump to main(), and switch to executing at
# high addresses. The indirect call is needed because
# the assembler produces a PC-relative instruction
# for a direct jump.
mov $main, %eax
jmp *%eax
#开辟stack区域,大小为KSTACKSIZE
.comm stack, KSTACKSIZE
让我们回到entry中继续页表的设置工作,它将entrypgdir的物理地址载入到控制寄存器%cr3中。分页硬件必须知道entrypdgir的物理地址,因为此时它还不知道如何翻译虚拟地址;它还没有页表。entrypgdir这个符号指向内存的高地址处,但只要用宏V2P_WO减去KERNBASE便可以找到其物理地址。为了让分页硬件运行起来,xv6会设置控制寄存器%cr0中的标志位CR0_PG。
现在entry就要跳转到内核的c代码,并在内存的高地址中执行它了。首先它将栈指针%esp指向被用作栈的一段内存。所有的符号包括stack都在高地址,所以当低地址的映射被移除时,栈仍然是可用的。最后entry跳转到高地址的main代码中。main不会返回,因为栈上并没有返回PC值。现在内核已经运行在高地址处的函数main中了。
创建第一个进程
main函数在初始化了一些设备和子系统后,它通过调用userinit建立了第一个进程。
// Bootstrap processor starts running C code here.
// Allocate a real stack and switch to it, first
// doing some setup required for memory allocator to work.
int
main(void)
{
kinit1(end, P2V(4*1024*1024)); // phys page allocator分配物理页面
kvmalloc(); // kernel page table内核页表
mpinit(); // detect other processors 检测其他处理器
lapicinit(); // interrupt controller中断控制器
seginit(); // segment descriptors段描述符号
picinit(); // disable pic停用图片
ioapicinit(); // another interrupt controller另一个中断控制器
consoleinit(); // console hardware控制台硬件
uartinit(); // serial port穿行端口
pinit(); // process table进程表
tvinit(); // trap vectors中断向量
binit(); // buffer cache缓冲区缓存
fileinit(); // file table文件表
ideinit(); // disk 磁盘
startothers(); // start other processors启动其他处理器
kinit2(P2V(4*1024*1024), P2V(PHYSTOP)); // must come after startothers()
userinit(); // first user process 第一个用户进程
mpmain(); // finish this processor's setup 完成此处理器的设置
}userinit首先调用allocproc。
//PAGEBREAK: 32
// Set up first user process.
void
userinit(void)
{
struct proc *p;
extern char _binary_initcode_start[], _binary_initcode_size[];
p = allocproc();
.....
}allocproc的工作是在进程表中分配一个proc,并初始化进程的状态,然后分配内核堆栈内存,初始化内核栈。为其内核线程的运行做准备。
//PAGEBREAK: 32
// Look in the process table for an UNUSED proc.
// If found, change state to EMBRYO and initialize
// state required to run in the kernel.
// Otherwise return 0.static struct proc*
allocproc(void)
{
struct proc *p;
char *sp;
acquire(&ptable.lock);
for(p = ptable.proc; p < &ptable.proc[NPROC]; p++)
if(p->state == UNUSED) //找到未被使用的结构体
goto found;
release(&ptable.lock);
return 0;
found:
p->state = EMBRYO;//更改状态为使用
p->pid = nextpid++;//设置进程号
release(&ptable.lock);
// Allocate kernel stack.尝试分配内核栈
if((p->kstack = kalloc()) == 0){//kalloc返回分配内存的虚拟地址
p->state = UNUSED;
return 0;
}注意一点:userinit仅仅在创建第一个进程时被调用,而allocproc创建每个进程时都会被调用。allocproc会在进程表中找到一个标记为UNUSED的位置。当它找到这样一个没有被使用的位置后,allocproc将其状态设置为EMBRYO,使其标记为被使用并给这个进程一个独有的pid。接下来,它尝试为进程的内核线程分配内核栈。如果分配失败了,allocproc会把这个位置的状态恢复为UNUSED并返回0来标记失败。
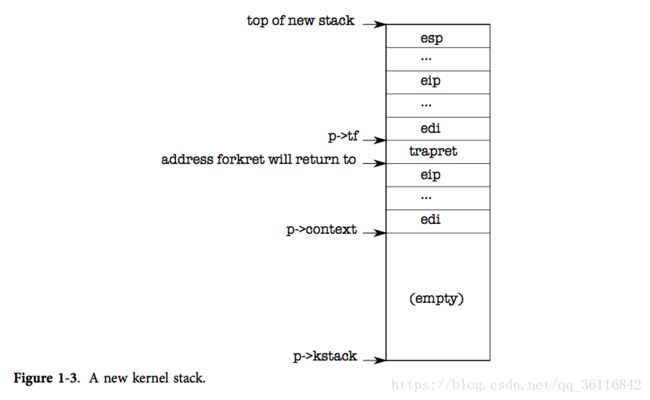
内核堆栈从底向上分为三部分:
struct trapframe:系统调用或者中断发生时,需要保存的信息
trapret
struct context:进程切换需要保存的上下文
sp = p->kstack + KSTACKSIZE;//栈顶指针
// Leave room for trap frame.
sp -= sizeof *p->tf;
p->tf = (struct trapframe*)sp;
// Set up new context to start executing at forkret,
// which returns to trapret.
sp -= 4;
*(uint*)sp = (uint)trapret;
sp -= sizeof *p->context;
p->context = (struct context*)sp;
memset(p->context, 0, sizeof *p->context);//上下文内容清0
p->context->eip = (uint)forkret;//内核线程从forkret开始运行
return p;
}sp = p->kstack + KSTACKSIZE;//栈顶指针
// Leave room for trap frame.
sp -= sizeof *p->tf;
p->tf = (struct trapframe*)sp;
// Set up new context to start executing at forkret,
// which returns to trapret.
sp -= 4;
*(uint*)sp = (uint)trapret;
sp -= sizeof *p->context;
p->context = (struct context*)sp;
memset(p->context, 0, sizeof *p->context);//上下文内容清0
p->context->eip = (uint)forkret;//内核线程从forkret开始运行
return p;
}现在allocproc必须设置新进程的内核栈,它以巧妙的方式,使其既能在创建第一个进程时被使用,又能在fork操作时被使用。alloproc为新进程设置好一个内核栈和一系列内核寄存器,使得进程第一次运行时会“返回”到用户空间,allocproc通过设置返回程序计数器的值,使得新进程的内核线程首先运行在forkret的代码中,然后返回到trapret中运行。内核线程会从p->context中拷贝的内容开始运行,所以可以通过将p->context->eip指向forkret从而让内核线程从forkret的开头开始运行。这个函数会返回到那个时刻栈底的地址。
context switch的代码把栈指针指向p->context结尾。allocproc又将p->context放在栈上,并在其上方放一个指向trapret的指针;这样运行完的forkret就会返回到trapret中了。trapret接着从栈顶恢复用户寄存器然后跳转到用户进程执行。这样的设置对于普通fork和建立第一个进程都是适用的,虽然后一种情况进程会从用户空间的地址0处开始执行而非真正的从fork返回。
将控制权从用户转到内核是通过中断机制实现的,每当进程运行中要将控制权交到内核时,硬件和xv6的trap entry代码就会在进程的内核栈栈上保存用户寄存器。userinit把值写在新建的栈的顶部,使之就像进程是通过中断进入内核的一样。所以用于从内核返回到用户的通用代码也就能适用于第一个进程。这些保存的值就构成了一个结构体struct trapframe,其中保存的是用户寄存器。现在进程的内核栈已经完全准备好了。
void
userinit(void)
{
struct proc *p;
extern char _binary_initcode_start[], _binary_initcode_size[];
p = allocproc();
initproc = p;
if((p->pgdir = setupkvm()) == 0)//setupkvm创建页表 只映射了内核区域
panic("userinit: out of memory?");
inituvm(p->pgdir, _binary_initcode_start, (int)_binary_initcode_size);
p->sz = PGSIZE;
memset(p->tf, 0, sizeof(*p->tf));
p->tf->cs = (SEG_UCODE << 3) | DPL_USER;
p->tf->ds = (SEG_UDATA << 3) | DPL_USER;
p->tf->es = p->tf->ds;
p->tf->ss = p->tf->ds;
p->tf->eflags = FL_IF;
p->tf->esp = PGSIZE;
p->tf->eip = 0; // beginning of initcode.S
safestrcpy(p->name, "initcode", sizeof(p->name));
p->cwd = namei("/");
// this assignment to p->state lets other cores
// run this process. the acquire forces the above
// writes to be visible, and the lock is also needed
// because the assignment might not be atomic.
acquire(&ptable.lock);
p->state = RUNNABLE;
release(&ptable.lock);
}userinit(void)
{
struct proc *p;
extern char _binary_initcode_start[], _binary_initcode_size[];
p = allocproc();
initproc = p;
if((p->pgdir = setupkvm()) == 0)//setupkvm创建页表 只映射了内核区域
panic("userinit: out of memory?");
inituvm(p->pgdir, _binary_initcode_start, (int)_binary_initcode_size);
p->sz = PGSIZE;
memset(p->tf, 0, sizeof(*p->tf));
p->tf->cs = (SEG_UCODE << 3) | DPL_USER;
p->tf->ds = (SEG_UDATA << 3) | DPL_USER;
p->tf->es = p->tf->ds;
p->tf->ss = p->tf->ds;
p->tf->eflags = FL_IF;
p->tf->esp = PGSIZE;
p->tf->eip = 0; // beginning of initcode.S
safestrcpy(p->name, "initcode", sizeof(p->name));
p->cwd = namei("/");
// this assignment to p->state lets other cores
// run this process. the acquire forces the above
// writes to be visible, and the lock is also needed
// because the assignment might not be atomic.
acquire(&ptable.lock);
p->state = RUNNABLE;
release(&ptable.lock);
}
第一个进程会先运行一个小程序(initcode.S),于是进程需要找到物理内存来保存这段程序。程序不仅需要被拷贝到内存中,还需要页表来指向那段内存。
最初,userinit调用setupkvm来为进程创建一个只映射了内核区的页表。第一个进程内存中的初始内存是汇编过的initcode.S;作为建立进程内核区的一步,连接器将这段二进制代码嵌入内核中并定义两个特殊的符号:_binary_initcode_start和_binary_initcode_size,用于表示这段代码的位置和大小。然后,userinit调用inituvm,分配一页物理内存,将虚拟地址0映射到那一段内存,并把这段代码拷贝到那一页中。
// Load the initcode into address 0 of pgdir.
// sz must be less than a page.
void
inituvm(pde_t *pgdir, char *init, uint sz)
{
char *mem;
if(sz >= PGSIZE)
panic("inituvm: more than a page");
mem = kalloc();//分配一块内存
memset(mem, 0, PGSIZE);
mappages(pgdir, 0, PGSIZE, V2P(mem), PTE_W|PTE_U);//映射到从0开始的虚拟地址
memmove(mem, init, sz);//将initcode存入内存
}inituvm(pde_t *pgdir, char *init, uint sz)
{
char *mem;
if(sz >= PGSIZE)
panic("inituvm: more than a page");
mem = kalloc();//分配一块内存
memset(mem, 0, PGSIZE);
mappages(pgdir, 0, PGSIZE, V2P(mem), PTE_W|PTE_U);//映射到从0开始的虚拟地址
memmove(mem, init, sz);//将initcode存入内存
}
接下来,userinit把trap frame设置为用户模式:%cs寄存器保存着一个段选择器,指向段SEG_UCODE,它处于特权级DPL_USER(即在用户模式而非内核模式)。类似的,%ds,%es,%ss的段选择器指向段SEG_UDATA并处于特权级DPL_USER。%eflags的FL_IF位被设置为允许中断。
memset(p->tf, 0, sizeof(*p->tf));
p->tf->cs = (SEG_UCODE << 3) | DPL_USER;
p->tf->ds = (SEG_UDATA << 3) | DPL_USER;
p->tf->es = p->tf->ds;
p->tf->ss = p->tf->ds;
p->tf->eflags = FL_IF;
p->tf->esp = PGSIZE;//进程最大有效虚拟地址
p->tf->eip = 0; // beginning of initcode.S指令指针指向初始化代码
safestrcpy(p->name, "initcode", sizeof(p->name));
p->cwd = namei("/");
// this assignment to p->state lets other cores
// run this process. the acquire forces the above
// writes to be visible, and the lock is also needed
// because the assignment might not be atomic.
acquire(&ptable.lock);
p->state = RUNNABLE;
release(&ptable.lock);
} memset(p->tf, 0, sizeof(*p->tf));
p->tf->cs = (SEG_UCODE << 3) | DPL_USER;
p->tf->ds = (SEG_UDATA << 3) | DPL_USER;
p->tf->es = p->tf->ds;
p->tf->ss = p->tf->ds;
p->tf->eflags = FL_IF;
p->tf->esp = PGSIZE;//进程最大有效虚拟地址
p->tf->eip = 0; // beginning of initcode.S指令指针指向初始化代码
safestrcpy(p->name, "initcode", sizeof(p->name));
p->cwd = namei("/");
// this assignment to p->state lets other cores
// run this process. the acquire forces the above
// writes to be visible, and the lock is also needed
// because the assignment might not be atomic.
acquire(&ptable.lock);
p->state = RUNNABLE;
release(&ptable.lock);
}
栈指针%esp被设为了进程的最大有效虚拟内存地址,即p->sz。指令指针则指向初始化代码的入口点,即地址0。
函数userinit把p->name设置为initcode,这主要是为了方便调试。还要将p->cwd设置为进程当前的工作目录;
一旦初始化完毕,userinit将p->state设置为RUNNABLE,使进程能够被调度。
initcode.S
# Initial process execs /init.
# This code runs in user space.
#include "syscall.h"
#include "traps.h"
# exec(init, argv)
.globl start
start:
pushl $argv
pushl $init
pushl $0 // where caller pc would be
movl $SYS_exec, %eax
int $T_SYSCALL
# for(;;) exit();
exit:
movl $SYS_exit, %eax
int $T_SYSCALL
jmp exit
# char init[] = "/init\0";
init:
.string "/init\0"
# char *argv[] = { init, 0 };
.p2align 2
argv:
.long init
.long 0
运行第一个进程
// Common CPU setup code.
static void
mpmain(void)
{
cprintf("cpu%d: starting %d\n", cpuid(), cpuid());
idtinit(); // load idt register
xchg(&(mycpu()->started), 1); // tell startothers() we're up
scheduler(); // start running processes
}在main调用userinit之后,mpmain调用scheduler开始运行进程。
void
scheduler(void)
{
struct proc *p;
struct cpu *c = mycpu();
c->proc = 0;
for(;;){
// Enable interrupts on this processor.
sti();
// Loop over process table looking for process to run.
acquire(&ptable.lock);
for(p = ptable.proc; p < &ptable.proc[NPROC]; p++){
if(p->state != RUNNABLE)
continue;
// Switch to chosen process. It is the process's job
// to release ptable.lock and then reacquire it
// before jumping back to us.
c->proc = p;
switchuvm(p);
p->state = RUNNING;
swtch(&(c->scheduler), p->context);
switchkvm();
// Process is done running for now.
// It should have changed its p->state before coming back.
c->proc = 0;
}
release(&ptable.lock);
}
}
scheduler会找到一个p->state为RUNNABLE的进程initproc,然后将per-cpu的变量proc指向该进程,接着调用switchuvm通知硬件开始使用目标进程的页表。scheduler接着把p->state设置为RUNNING,调用swtch,切换上下文到目标进程的内核线程中。swtch会保存当前的寄存器,并把目标内核线程中保存的寄存器(proc->context)载入到x86的硬件寄存器中,其中也包括栈指针和指令指针。当前的上下文并非是进程的,而是一个特殊的per-cpu调度器的上下文。所以scheduler会让swtch把当前的硬件寄存器保存在per-cpu的存储(cpu->scheduler)中,而非进程的内核线程的上下文中。
# Context switch
#
# void swtch(struct context **old, struct context *new);
#
# Save the current registers on the stack, creating
# a struct context, and save its address in *old.
# Switch stacks to new and pop previously-saved registers.
.globl swtch
swtch:
movl 4(%esp), %eax
movl 8(%esp), %edx
# Save old callee-save registers
pushl %ebp
pushl %ebx
pushl %esi
pushl %edi
# Switch stacks
movl %esp, (%eax)
movl %edx, %esp
# Load new callee-save registers
popl %edi
popl %esi
popl %ebx
popl %ebp
ret
最后的ret指令从栈中弹出目标进程的%eip,从而结束上下文切换工作。现在处理器就运行在进程p的内核栈上了。
allocproc通过把initproc的p->context->eip设置为forkret使得ret开始执行forkret的代码。第一次被使用(也就是这一次)时,forkret会调用一些初始化函数。不能在main中调用,因为他们I必须在一个拥有自己的内核栈的普通进程中运行。接下来forkret返回。
// A fork child's very first scheduling by scheduler()
// will swtch here. "Return" to user space.
void
forkret(void)
{
static int first = 1;
// Still holding ptable.lock from scheduler.
release(&ptable.lock);
if (first) {
// Some initialization functions must be run in the context
// of a regular process (e.g., they call sleep), and thus cannot
// be run from main().
first = 0;
iinit(ROOTDEV);
initlog(ROOTDEV);
}
// Return to "caller", actually trapret (see allocproc).
}
// will swtch here. "Return" to user space.
void
forkret(void)
{
static int first = 1;
// Still holding ptable.lock from scheduler.
release(&ptable.lock);
if (first) {
// Some initialization functions must be run in the context
// of a regular process (e.g., they call sleep), and thus cannot
// be run from main().
first = 0;
iinit(ROOTDEV);
initlog(ROOTDEV);
}
// Return to "caller", actually trapret (see allocproc).
}
由于allocproc的设计,目前栈上再p->context之后即将被弹出的字是trapret,因而接下来会运行trapret,此时%esp保存着p->tf。
# Return falls through to trapret...
.globl trapret
trapret:
popal
popl %gs
popl %fs
popl %es
popl %ds
addl $0x8, %esp # trapno and errcode
iret# Return falls through to trapret...
.globl trapret
trapret:
popal
popl %gs
popl %fs
popl %es
popl %ds
addl $0x8, %esp # trapno and errcode
irettrapret用弹出指令从trapframe中恢复寄存器,就像swtch对上下文的操作一样:popal恢复通用寄存器,popl恢复%gs,%fs,%es,%ds。addl跳过trapno和errcode两个数据,最后iret弹出%cs,%eip,%flags,%esp,%ss。trap frame的内容以经转移到CPU状态中,所以处理器会从trap frame中的%eip的值继续执行。对于initproc来说,这个值就是虚拟地址0,即initcode.S的第一个指令。这时%eip和%esp的值为0和4096,这是进程地址空间中的虚拟地址。处理器的分页硬件会把它们翻译为物理地址。allocuvm为进程建立了页表,所以现在虚拟地址0会指向为该进程分配的物理地址处。allocuvm还会设置标志位PTE_U来让分页硬件允许用户代码访问内存。userinit设置了%cs的低位,使得进程的用户代码运行在CPL=3的情况下,这意味着用户代码只能使用带有PTE_U设置的页,而且无法修改像%cr3这样的敏感的硬件寄存器。这样,处理器就受限只能使用自己的内存了。