Tensorflow2.0学习(四) — Keras基础应用(泰坦尼克生存率预测)
前几节分享的内容都是基于图片数据进行了简单的分类工作,这节内容将应用keras对泰坦尼克旅客的文本数据进行预测,主要是做一个二分类的工作,根据官方提供的数据中的各项特征预测每个旅客生存的概率是多少。
一.Titanic3数据集的下载
1.导入相关使用到的库。这里的urllib库的作用主要是用于下载数据,os库用于判断文件是否存在,sklearn的preprocessing用于对文本数据进行预处理。
import os
import urllib.request
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow.keras import layers
from sklearn import preprocessing
import matplotlib.pyplot as plt2.下载数据集。
#下载的网页路径
url='http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic3.xls'
filepath="titanic3.xls" #文件路径
if not os.path.isfile(filepath):
result = urllib.request.urlretrieve(url,filepath) #该函数可以将远程数据下载到本地
print(result)3.使用pandas读取文件,并显示查看。
all_df = pd.read_excel(filepath)
4.数据集特征名字的解释。survival:是否生存,pclass:舱级别,如一等二等舱等,name:名字,sex:性别,age:年龄,sibsp:手足或配偶也在船上的数量,parch:双亲或子女也在船上的数量,fare:旅客费用,embarked:登船港口地点。
二.Titanic3数据集的预处理
1.选取有用的特征信息。数据集的特征不一定都有用,冗余的特征对于分析帮助不大且会增加训练参数量,因此我们第一步根据需求选取指定特征。
cols = ['survived','name','pclass','sex','age','sibsp','parch','fare','embarked']
all_df=all_df[cols]
2.数据集中有很多特征值为空值NULL,这种数据信息缺失的情况在绝大多数数据集中都可能会存在,因此我们需要填补上这些空缺的信息。我们可以用下面这个函数进行查看缺失数据的特征对象和数量。
all_df.isnull().sum()
3.接下来这一步,我直接包装了一个函数方便使用。首先我们去除名字信息,名字在训练中没有用到,但在预测时需要使用。另外在知道了缺失的特征之后我们需要补充其它值上去,很多人会补充0,但比如在年龄、费用这些特征上,0值是不符合实际情况的,比较合理的一个补充方式是补充它们的平均值上去。然后接着我们会发现性别特征和embarked特征上的值是字母地点,由于深度学习模型只能处理数字信息,因此我们先要用map函数将性别值映射为数字1和0,接着对embarked这个特征进行One-Hot编码将其转为数字。其次我们要将pandas的DataFrame格式转为数值矩阵以便神经网络可以训练。最后我们提取出数据中的特征和标签并用preprocessing对所有值进行标准化。
流程:去除名字信息->用平均值补充缺失值->map将性别映射为数字->对embarked特征进行One-Hot编码->DataFrame转数值矩阵->所有特征标准化。
def Processing_Data(raw_df):
df = raw_df.drop(['name'],axis=1) #去除名字特征
age_mean = df['age'].mean() #求年龄平均值
df['age'] = df['age'].fillna(age_mean) #用fillna填充缺失值
fare_mean = df['fare'].mean() #求费用平均值
df['fare'] = df['fare'].fillna(fare_mean) #填充缺失值
df['sex'] = df['sex'].map({'female':0,'male':1}).astype(int) #map映射性别为数字
X_Onehot_df = pd.get_dummies(data=df,columns=['embarked']) #One-Hot编码embarked特征
ndarray = X_Onehot_df.values #转为array
Features = ndarray[:,1:] #提取特征
Labels = ndarray[:,0] #提取标签
minmax_scale = preprocessing.MinMaxScaler(feature_range=(0,1))
scaledFeature = minmax_scale.fit_transform(Features) #所有特征标准化
return scaledFeature,Labels显示前五行预处理后的特征的数值。
feature,label = Processing_Data(all_df)
print(feature[:5])
4.按8:2的比例随机将数据集分割训练集和测试集。
msk = np.random.rand(len(all_df))<0.8 #使用numpy生成正态分布的点,并取80%
train_df = all_df[msk]
test_df = all_df[~msk]
train_Features,train_Label = Processing_Data(train_df)
test_Featuress,test_Label = Processing_Data(test_df)
print(train_Features.shape)
print(test_Featuress.shape)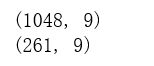
三.模型搭建
1.构建Sequential线性堆叠模型。
model = tf.keras.models.Sequential()2.叠加相关层。
model.add(layers.Dense(units=30,input_dim=9,activation='relu',kernel_initializer='uniform'))
model.add(layers.Dense(units=20,kernel_initializer='uniform',activation='relu'))
model.add(layers.Dense(units=1,kernel_initializer='uniform',activation='sigmoid'))四.模型训练
1.模型设置及训练。因为最后判别的结果是0(死)或1(生),因此这里要使用二值损失函数。
model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['accuracy'])
train_history = model.fit(x=train_Features,y=train_Label,validation_split=0.2,epochs=100,batch_size=30,verbose=1)

2.定义曲线显示函数并显示。
def show_train_history(train_history,train,validation):
plt.plot(train_history.history[train])
plt.plot(train_history.history[validation])
plt.title('Train History')
plt.xlabel('epoch')
plt.ylabel(train)
plt.legend(['train','validation'],loc='upper left')
show_train_history(train_history,'accuracy','val_accuracy')

五.模型测试及预测
1.模型测试。
scores = model.evaluate(x=test_Featuress,y=test_Label,verbose=2)
print(scores[1])

2.模型预测。
这里我们根据指定信息人为的生成两个数据点Jack和Rose进行测试,也就是大家熟知的电影男女主角。
Jack = pd.Series([0,'Jack','3','male',23,1,0,5,'S'])
Rose = pd.Series([1,'Rose','1','female',23,1,0,5,'S'])
JR_df = pd.DataFrame([list(Jack),list(Rose)],columns=['survived','name','pclass','sex','age','sibsp','parch','fare','embarked'])
将生成数据放到原数据中,并重新对数据进行标准化处理。
all_df = pd.concat([all_df,JR_df])
all_Features,Label = Processing_Data(all_df)最后对模型进行预测,显示最后两个点也就是Jack和Rose的生存概率。从值中我们可以看到,Rose生存率远大于Jack,符合电影最后结局。
all_Features,Label = Processing_Data(all_df)
all_probabiblity = model.predict(all_Features)
all_probabiblity[-2:]
以上是这一节的所有内容的分享,谢谢大家的观看。如有不足或有疑问的地方可以一起探讨,谢谢。