Neon内部函数---部分基本函数、数据处理 类型转换
对于neon内置函数的概念相关定义网上很多,下面是对最近用的Neon函数的记录,以便方便查找。
必须使用头文件arm_neon.h来使用内部函数,并为矢量操作定义C样式类型。 C类型以以下形式编写:
uint8x16_t:这是一个包含无符号8位整数的向量。向量中有16个元素。因此,向量必须位于128位Q寄存器中。
int16x4_t:这是一个包含有符号16位整数的向量。向量中有4个元素。因此,向量必须位于64位D寄存器中。
一、 常用函数(基础函数)
注意:q标志,以指定内部函数对128位vector进行操作。
Result_t vld1_type(Scalar_t* N); //后缀不带有q,输出向量是D寄存器的64位向量
Result_t vld1q_type(Scalar_t* N); //带有q后缀,输出向量是128位向量,使用Q寄存器
从数组arr中依次Load 4个元素存到寄存器中:
float32x2_t temp = vld1_f32(int32_t arr);//
float32x4_t temp = vld1q_f32(int32_t arr); //
将寄存器中的值写入数组中:(temp中的四个元素以此存入数组ptr中)
void vst1q_f32 (float32_t * ptr, float32x4_t temp )
将常量value复制4份到寄存器的每个元素中:
float32x4_t sum_vec = vdupq_n_f32(value);
将结果移回普通变量中。即从NEON寄存器中访问具体元素:
float sum = vgetq_lane_f32(sum_vec, i); //i取值:0-3。表示从寄存器sum_vec中通道i中提取一个 float数
返回两个寄存器对应元素之和 r = a+b:
float32x4_t vaddq_f32 (float32x4_t a, float32x4_t b);返回两个寄存器对应元素之差 r = a-b:
float32x4_t vsubq_f32 (float32x4_t a, float32x4_t b);
返回两个寄存器对应元素之积 r = a*b,寄存器a中的对应元素与b中的对应元素相乘:
float32x4_t vmulq_f32 (float32x4_t a, float32x4_t b);
返回r = a +b*c;寄存器b中的对应元素与c中的对应元素相乘,结果再与寄存器a中的对应元素相加。
float32x4_t vmlaq_f32 (float32x4_t a, float32x4_t b, float32x4_t c);
拼接两个寄存器并返回从第n位开始的大小为4的寄存器 0<=n<=3
float32x4_t vextq_f32 (float32x4_t a, float32x4_t b, const int n);
neon函数加法运算图解:

float SumFloat32Neon(float *array, int len)
{
float *arr=array;
int dim4; // 数组长度除4整数
int left4; // 数组长度除4余数
float32x4_t sum_vec;//定义用于暂存累加结果的寄存器且初始化为0
float sum=0.0;
dim4 = len >> 2; // 数组长度除4整数
left4 = len & 3; // 数组长度除4余数
sum_vec = vdupq_n_f32(0.0);//将常量0复制4份到寄存器sum_vec中
for (; dim4>0; dim4--, arr+=4) //每次同时访问4个数组元素
{
float32x4_t data_vec = vld1q_f32(arr); //依次取4个元素存入寄存器vec
sum_vec = vaddq_f32(sum_vec, data_vec);//ri = ai + bi 计算两组寄存器对应元素之和并存放到相应结果
}
//将累加结果寄存器中的所有元素相加得到最终累加值
sum = vgetq_lane_f32(sum_vec, 0)+vgetq_lane_f32(sum_vec, 1)+
vgetq_lane_f32(sum_vec, 2)+vgetq_lane_f32(sum_vec, 3);
for (; left4>0; left4--, arr++)
sum += (*arr) ; //对于剩下的少于4的数字,依次计算累加即可
return sum;
}二、 特殊函数
1. vget_low_type(Vector_t low): 返回128位输入向量的低位的半部分。输出是一个64位矢量,其元素数量是输入矢量的一半。
float32x2_t low = vget_low_f32(q0); // 取寄存器q0的低2位元素,q0定义为:float32x4_t2. vget_high_type(Vector_t low): 返回128位输入向量的高半部分。输出是一个64位矢量,其元素数量是输入矢量的一半。
float32x2_t high= vget_high_f32(q0); // 取寄存器q0的高2位元素3. vcombine_type(Vector1_t low, Vector2_t high) : 将两个64位矢量连接成单个128位矢量。输出矢量包含的元素数量是每个输入矢量的两倍。
float32x2_t a = vget_low_f32(q0); // 取寄存器q0的低2位元素,q0定义为:float32x4_t
float32x2_t b = vget_high_f32(q0); // 取寄存器q0的高2位元素。寄存器a,b均为float32x2_t , 64位
float32x4_t ret = vcombine_f32 (a, b);//寄存器ret为float32x4_t
数据类型转换:
vcombine_type(); vmovl_type(); vmovn_type(); vqmovn_type(); vqmovun_type();
1. Result_t vmovl_type(Vector_t N):将其扩展为原始长度的两倍,单字向量扩展为双字,双字向量扩展为四字:u8转u16; s8转s16; u16转u32; s16转s32
输入与输出vector类型:
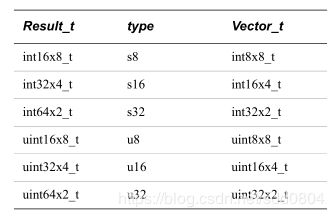
//arr表示一个 uint8的数组,下面实现u8转u16
uint8x8_t temp=vld1_u8(&arr);//从数组arr中依次Load 8个元素存到寄存器temp中
uint16x8_t result=vmovl_u8(temp);//寄存器中的每个元素的长度都扩展为原来的两倍,u8扩展为u162. Result_t vqmovn_type(Vector_t N); 将操作数向量的每个元素复制到目标向量的相应元素。结果元素是操作数元素宽度的一半,并且值饱和到结果宽度。双字转单字,四字转双字:u16转u8; s16转s8; u32转u16; s32转s16。
输入与输出vector类型:
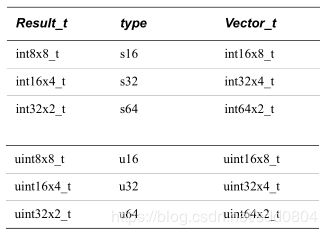
uint16x8_t temp = vld1q_u16(&arr);
uint8x8_t result = vqmovn_u16(temp);//result寄存器中的每个元素的长度都是原始长度的一半,u16转u83. Result_t vqmovun_type(Vector_t N); 将操作数向量的每个元素复制到目标向量的相应元素。结果元素是操作数元素宽度的一半,并且值饱和到结果宽度。有符号转无符号:s16转u8; s32转u16; s64转u32
输入与输出vector类型:
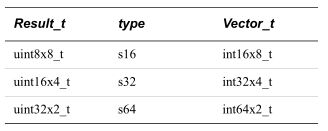
int16x8_t temp = vld1q_s16(&arr);
uint8x8_t result = vqmovun_s16(temp);4. Result_t vmovn_type(Vector_t N); 将四字向量的每个元素的最低有效一半复制到双字向量的相应元素中。s16转s8,s32转s16,s64转s32,u16转u8,u32转u16,u64转u32

5. Result_t vcombine_type(Vector1_t N, Vector2_t M); 将两个64位向量合并为一个128位向量。输出向量包含的元素数量是每个输入向量的两倍。输出向量的low半部分包含第一个输入向量的元素。
输入与输出vector类型:
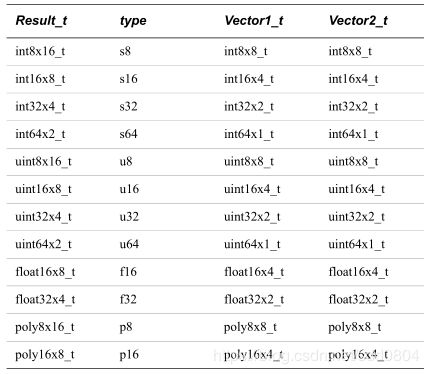
int16x4_t temp0 = vld1q_s16(&arr0);//从内存中加载4个元素到寄存器temp0中
int16x4_t temp1 = vld1q_s16(&arr1);
int16x8_t temp = vcombine_s16(temp0, temp1);6. VCVT在单精度和双精度数字之间转换。f32转s32,f32转u32
- 整数或定点到浮点的转换使用四舍五入到最接近的值;
- 浮点数到整数或定点转换使用向零舍入(正数向下舍入,负数向上舍入,例:2.3 -> 2; -2.7 -> -2)。
Result_t vcvt_type_f32(Vector_t N);
 VCVT
VCVT
Result_t vcvtq_type_f32(Vector_t N);
 VCVTQ
VCVTQ
VCVT_N:
Result_t vcvt_n_type_f32(Vector_t N, int n);
 VCVT_N
VCVT_N
Result_t vcvtq_n_type_f32(Vector_t N, int n);
 VCVTQ_N
VCVTQ_N
更多neon 内部函数请到官网:https://developer.arm.com/architectures/instruction-sets/simd-isas/neon/intrinsics