Protege、D2RQ、JENA与SPARQL
引言
关于的知识图谱的相关概念在从语义网络到知识图谱这篇博文中有简单的描述,下面介绍一下在知识图谱实际使用中的一些工具。
数据
来源于The Movie Database (TMDb)抓取的电影数据,统计如下:
- 演员数量:505人
- 电影数量:4518部
- 电影类型:19类
- 人物与电影的关系:14451
- 电影与类型的关系:7898
演员的基本信息包括:姓名、英文名、出生日期、死亡日期、出生地、个人简介。
电影的基本信息包括:电影名称、电影简介、电影评分、电影发行日期、电影类型。
从这里可以获取处理好的mysql文件。
Protege
Protégé,又常常简单地拼写为“Protege”,是一个斯坦福大学开发的本体编辑和知识获取软件。开发语言采用Java,属于开放源码软件。由于其优秀的设计和众多的插件,Protégé已成为目前使用最广泛的本体论编辑器之一。
本体的构建大体有两种方式:自顶向下和自底向上。一般在开放域使用自底向上的方法,这里在电影领域则采用自顶向下的方式建立本体。
IRI
打开Protege,在Ontology IRI中填写本体资源的IRI,格式可以参考以下图片:

Class
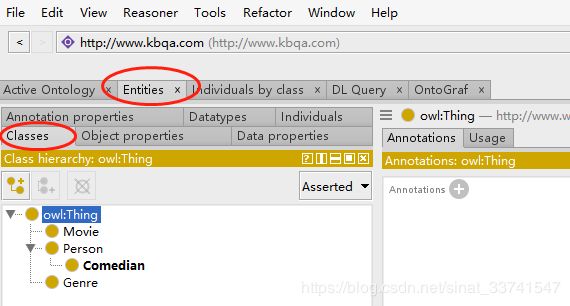
切换到如下界面,创建电影知识图谱的类/概念。
这里创建了三个类,“人物”、“电影”、“类别”,注意,所有的类都是“Thing”的子类。
Object Properties
接着创建类之间的关系,即对象属性。
这里创建了三个对象属性,"hasActor"表示某电影有某人参演,"domain"表示该属性是属于哪个类的,“range"表示该属性的取值范围。
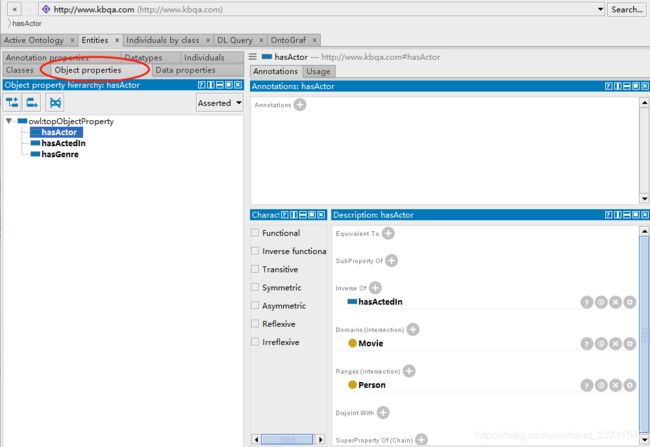
注意“Inverse Of”表示该属性的逆属性是"hasActedIn”,这代表着推理的功能,即使在RDF数据中没有显性的定义A参演了某部电影,但拥有这个属性也能够推理出来。
Data properties
然后创建类的属性,即数据属性。
定义方法与定义对象属性,但这里更多的是定义数据的类型及拥有该属性的实体,如下:

OntoGraf
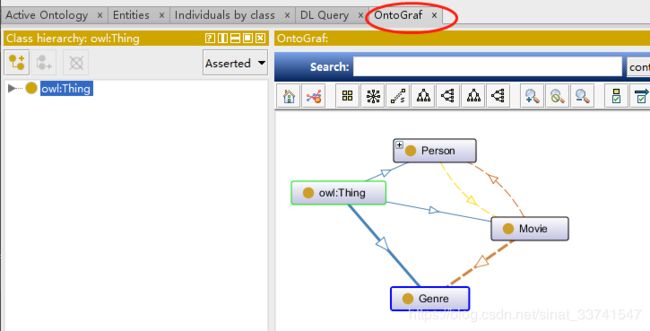
定义完本体,可以用可视化的方式形象的了解目前的层次结构,点击"Windows==>Tabs==>OntoGraf",如下:
Export
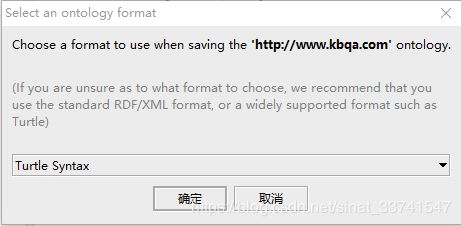
确定本体定义完成后,就可以导出本体文件了,直接点击“save as”另存为’turtle‘格式的文件:
D2RQ
前面给出的数据是存在Mysql中,所以这里需要一个处理,将数据转换为RDF格式。
D2RQ支持的数据库有Oracle、MySQL、PostgreSQL、SQL
Server、HSQLDB、Interbase/Firebird。也支持其他某些数据库,但可能会有限制。
使用D2RQ进行数据导出主要分为两个步骤,第一个是建立数据库文件到定义好的本体之间的映射;之后再根据映射文件导出RDF数据。
Mapping
D2RQ定义了自己的Mapping language,用户可以自行编写,但一般推荐使用D2RQ工具自动生成后再进行修改,会节省大部分时间:
generate-mapping -u user -p pwd -o kg_movie_mapping.ttl jdbc:mysql:///kg_demo_movie
执行上述命令生成mysql的默认mapping文件,之后再根据前面定义好的本体文件进行修改,修改方式暂时不做详细介绍,后续会上传修改前后文件。
Mapping语法可参考:The D2RQ Mapping Language
Export
修改完mapping文件后,就可以将Mysql数据库里的数据,根据映射文件导出为RDF三元组了,
dump-rdf.bat -o kg_movie_rdf.nt kg_movie_mapping.ttl
D2R Server
D2RQ还可以虚拟RDF的方式来访问关系数据库中的数据,即我们不需要显式地把数据转为RDF形式。
通过Web Server的方式,根据Mapping文件,用查询RDF数据的方式来查询关系数据库中的数据,即:
SPARQL==>D2RQ==>SQL==>Mysql
启动D2R Server的方式如下:
d2r-server.bat kg_movie_mapping.ttl
启动完成后,即可在 http://localhost:2020/ 中查看到启动的页面,并进行SPARQL查询,如:
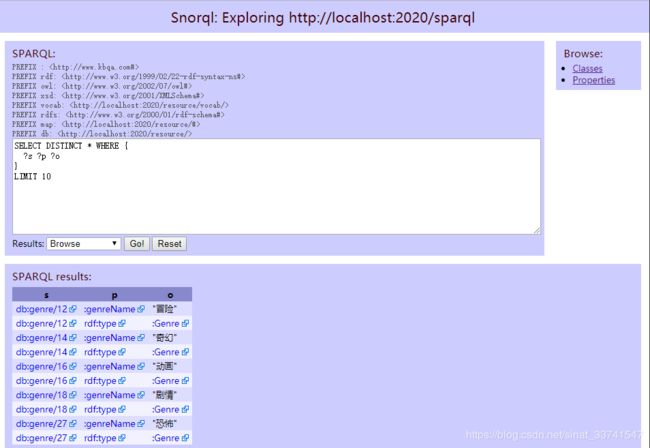
详情可查看官方文档:http://d2rq.org/d2r-server
JENA
前面介绍了D2RQ可以提供虚拟的RDF查询方式,但实际上数据依旧在Mysql中,这种方式在频繁访问的情况下开销会很大,所以需要一个可以访问本地RDF文件的工具。
Apache Jena(后文简称Jena),是一个开源的Java语义网框架(open source Semantic Web Framework for Java),用于构建语义网和链接数据应用。
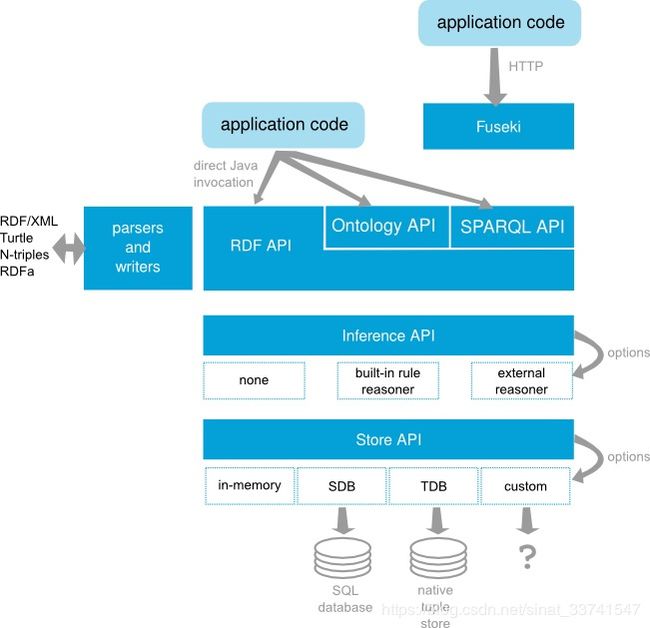
我们这里只需要关注:TDB、Rule Reasoner和Fuseki。
TDB:Jena用于存储RDF的组件,能够提供非常高的RDF存储性能。
Rule Reasoner:Jena的RDFS、OWL和通用规则推理机。
Fuseki:Jena的SPARQL服务器,也就是SPARQL endpoint。
安装包下载地址:http://archive.apache.org/dist/jena/binaries/ ,分别下载apache-jena-fuseki-3.5.0,与apache-jena-3.5.0。
TDB
首先需要将RDF数据存到TDB数据库中,当然也可以后续再添加:
建立文件夹"tdbfiles"作为TDB的本地存储路径
进入apache-jena-3.5.0/bat路径
tdbloader.bat --loc="tdbfiles" "kg_movie_rdf.nt“
”–loc”指定TDB的本地存储路径,第二个参数则是在前面导出的RDF数据。
Fuseki
启动Fuseki服务前,需要编写配置文件。
首先进入“apache-jena-fuseki-3.5.0”路径,运行“fuseki-server.bat”退出后会在当前目录下自动创建”run”文件夹;
创建名为“fuseki_3.5_conf.ttl”的文件,移动到"run/configuration"中,再次启动fuseki服务,具体配置内容在我的github上可以找到;
启动完成后,即可在 http://localhost:3030/ 中查看到启动的页面,并进行SPARQL查询,如:
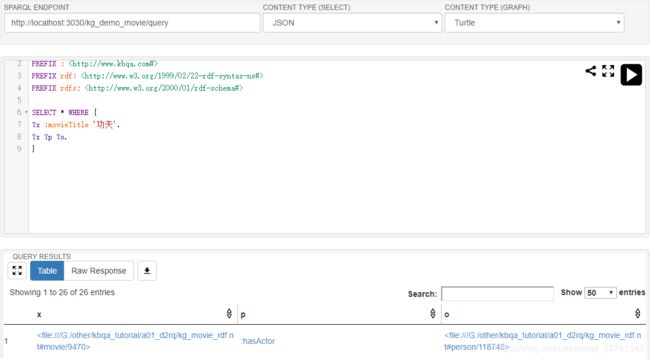
可以看到“hasActor"属性是通过推理得到的,原本的RDF数据中并不存在,这也是JENA比D2RQ更优秀的地方。
Rule Reasoner
在前面其实已经使用JENA的OWL推理机,但是如果想自定义规则,可以使用自定义的推理机。
新建规则文件“rules.ttl”,同时新建另一个配置文件“fuseki_3.5_rule_conf.ttl”添加自定义推理功能,再启动服务:
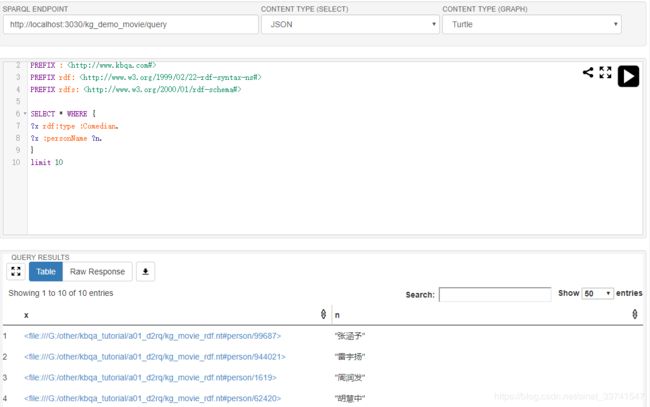 这里定义一个规则,如果有一个演员,出演了一部喜剧电影,那么他就是一位喜剧演员,可以看到查询出来的结果。
这里定义一个规则,如果有一个演员,出演了一部喜剧电影,那么他就是一位喜剧演员,可以看到查询出来的结果。
SPARQL
上面在查询时都使用了SPARQL语言,与SQL用与数据库查询一样,SPARQL也是一种查询语言,用于RDF数据的查询。
SPARQL即SPARQL Protocol and RDF Query
Language的递归缩写,专门用于访问和操作RDF数据,是语义网的核心技术之一。W3C的RDF数据存取小组(RDF Data Access
Working Group, RDAWG)对其进行了标准化。
从SPARQL的全称我们可以知道,其由两个部分组成:协议和查询语言。
查询:像SQL用于查询关系数据库中的数据,XQuery用于查询XML数据,SPARQL用于查询RDF数据。
协议:指我们可以通过HTTP协议在客户端和SPARQL服务器(SPARQL endpoint)之间传输查询和结果,这也是和其他查询语言最大的区别。
具体的使用方式不做详细说明,可以参考:https://www.w3.org/TR/rdf-sparql-query/
引用
1、https://zhuanlan.zhihu.com/knowledgegraph