【paper reading】Recurrent Models of Visual Attention

原文地址 https://arxiv.org/abs/1406.6247
1 background and motivation
神经网络在CV任务上逐年取得突破性成就,但是如今的硬件设备限制了输入图像的尺寸。这是14年的文章,即使在今天,仍然会面临着图像过大而带来巨大的训练及推理代价。本文的出发点就是要解决这些computational cost.
从人类的认知领域出发,人类观察一张图片往往是按照某个顺序依次查看的,比如观察一个人像可能是从上到下的顺序。专注于某个局部,这也正是如今attention机制所强调的。本文的attention从直觉上看与如今的attention机制是一回事,但算法原理却很不一样。以免混淆,将本文的attention叫做glimpse会好一点,也正如文章中的描述一样。
通过获取一定数量的glimpse,模拟人对图像的观察过程,便可以不用计算所有的pixel,使得模型的计算量与图像的尺寸无关。这也是本文的主要贡献。(就是说对任意图像都采样固定量的局部图像,就通过采的这几个局部图像作出判断)。很明显,采到的图像是否具有判断力便是其性能的关键,因此不能随机抽取,需要按照某种模式去采得。
2 Method
如何去选取关键的glipmse, 也就是本文所提出的方法了—Recurrent Attention Model (RAM)。
核心思想就是将对glimpse的选取作为一个序列化决策的过程,就是强化学习嘛,也就是本文所说的control problem。

具体方法总结如下:
水平方向上是类似一个RNN, 是hidden state.
是hidden state.![]() 是位置信息(0,0)表示图像中央,(-1,-1)表示左上角。整个数据流程如上图所示。每一个时刻t要作两个决策,一个是对具体任务的判断,如这里是分类,另一个则是预测下一个glimpse的位置。
是位置信息(0,0)表示图像中央,(-1,-1)表示左上角。整个数据流程如上图所示。每一个时刻t要作两个决策,一个是对具体任务的判断,如这里是分类,另一个则是预测下一个glimpse的位置。
损失函数:
对于分支 采用正常的分类损失,从直觉上看在终止时刻T之前的预测对其计算损失是不应该的,因为在T时刻之前可能还没有选到关键的glimpse,对其进行back propagation是不合理的,因此只计算最后时刻的分类损失。
采用正常的分类损失,从直觉上看在终止时刻T之前的预测对其计算损失是不应该的,因为在T时刻之前可能还没有选到关键的glimpse,对其进行back propagation是不合理的,因此只计算最后时刻的分类损失。
而对于![]() 这一分支,是不可直接作微分的。这里要通过policy gradient使得累积reward 对其概率分布最大化。即下式所示
这一分支,是不可直接作微分的。这里要通过policy gradient使得累积reward 对其概率分布最大化。即下式所示
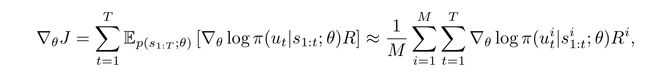
注意,这里获得的![]() 其实是这预测值上的一个高斯分布采样值
其实是这预测值上的一个高斯分布采样值
def forward(self, h):
l_mu = self.fc(h) # compute mean of Gaussian
pi = Normal(l_mu, self.std) # create a Gaussian distribution
l = pi.sample() # sample from the Gaussian
logpi = pi.log_prob(l) # compute log probability of the sample
l = torch.tanh(l) # squeeze location to ensure sensing within the boundaries of an image
return logpi, lR是对决策过程的反馈,若分类正确则R为1,否则为0。
完整loss定义如下
def forward(self, recon_a, a, logpi):
self.t += 1
self.logpi += [logpi]
if self.t==self.T:
R = self.compute_reward(recon_a, a) # reward is given at the end of the episode
a_loss = F.cross_entropy(recon_a, a, reduction='sum') # supervised objective for action network
l_loss = 0
R_b = (R - self.baseline.detach()) # centered rewards
for logpi in reversed(self.logpi):
l_loss += - (logpi.sum(-1) * R_b).sum() # REINFORCE
R_b = self.gamma * R_b # discounted centered rewards (although discount factor is always 1)
b_loss = ((self.baseline - R)**2).sum() # minimize SSE between reward and the baseline
return a_loss , l_loss , b_loss, R.sum()
else:
return None, None, None, None代码引自https://github.com/samrudhdhirangrej/Recurrent-Model-of-Visual-Attention
3 experiment
实验主要是在MNIST及其增强版的数据集上的实验,具体见原文,放两张可视化的结果看其做序列决策效果。

4 Summary
本文提出的RAM结构在解决计算量问题上确实是一个很好的尝试,motivation也十分直觉。为了更多的任务提供了一个可选的解决方案。不直接对整幅图像处理,而是对一系列的patch预测,可有效减少大量的计算量,同时也可以降低噪声的影响。但是毕竟还是相当于对原图像进行采样,似乎只能适用于分类这一任务?