21.构建memcached服务、LNMP+memcached、PHP的本地Session信息、PHP实现session共享
*******************************
完整部署:一台前端调度服务器:proxy,两台后端LNMP WebServer
项目要求:01.Proxy部署Nginx调度器负载后端两台Web服务器,调度算法为轮询。
02.Proxy部署Mencache缓存服务器,后端WebServer配置php连接Proxy的Memcached服务,将本地Session缓存在Memcached服务器,实现后端两台WebServer Session共享。
03.Proxy部署Varnish加速WebServer。
Client请求 --> (Proxy)Varnish(未缓存) --> (Proxy)Nginx(轮询) --> WebServer --> (Proxy)Varnish(缓存) --> Client
*******************************
1> 构建memcached服务
安装包:memcached
配置文件:/etc/sysconfig/memcached
默认端口:11211
服务:memcached
访问:]# telnet 192.168.4.5 11211
常用命令:
set name 0 180 3
plj
get name
add replace append delete stats flush_all quit
总结:本质上,它是一个简洁的key-value存储系统。
特点: 01.全内存运转
02.哈希方式存储
03.简单文本协议进行数据通信
04.只操作字符型数据
05.其它类型数据由应用解释,序列化以及反序列化
06.集群也由应用进行控制,采用一致性散列(哈希)算法
缺点: 01.数据是保存在内存当中的,一旦服务进程重启,数据会全部丢失
对策:可以采取更改Memcached的源代码,增加定期写入硬盘的功能
02.Memcached以root权限运行,而且Memcached本身没有任何权限管理和认证功能,安全性不足。
对策:可以将Memcached服务绑定在内网IP上,通过防火墙进行防护
整理:特性、优点和限制
Memory :内存存储,速度快,对于内存的要求高,所缓存的内容非持久化。对于 CPU 要求很低,所以常常采用将Memcached 服务端和一些 CPU 高消耗 Memory 低消耗应用部属在一起 。(否则会互相挤占资源)
集中式 Cache :避开了分布式 Cache 的传播问题,但是需要非单点保证其可靠性,这需要 cluster 的工作,可以将多个Memcached 作为一个虚拟的 cluster ,同时对于 cluster 的读写和普通的 memcached 的读写性能没有差别。
分布式扩展: Memcached 很突出的一个优点,就是采用了可分布式扩展的模式。可以将部属在一台机器上的多个 Memcached 服务端或者部署在多个机器上的 Memcached 服务端组成一个虚拟的服务端,对于调用者来说完全屏蔽和透明。提高的单机器的内存利用率 。
Socket 通信:传输内容的大小以及序列化的问题需要注意,虽然 Memcached 通常会被放置到内网作为 Cache, Socket 传输速率应该比较高(当前支持 Tcp 和 udp 两种模式,同时根据客户端的不同可以选择使用 nio 的同步或者异步调用方式),但是序列化成本和带宽成本还是需要注意。这里也提一下序列化,对于对象序列化的性能往往让大家头痛,但是如果对于同一类的 Class 对象序列化传输,第一次序列化时间比较长,后续就会优化,其实也就是说序列化最大的消耗不是对象序列化,而是类的序列化。如果穿过去的只是字符串,那么是最好的,省去了序列化的操作,因此在 Memcached 中保存的往往是较小的内容 。
特殊的内存分配机制:首先要说明的是 Memcached 支持最大的存储对象为 1M (page)。它的内存分配比较特殊,但是这样的分配方式其实也是对于性能考虑的,简单的分配机制可以更容易回收再分配,节省对于 CPU 的使用(前面的文章中有描述) 。
Cache 机制简单: 首先它没有什么同步,消息分发,两阶段提交等等,它就是一个很简单的 Cache ,把东西放进去,然后可以取出来,如果发现所提供的 Key 没有命中,那么就很直白的告诉你,你这个 key 没有任何对应的东西在缓存里,去数据库或者其他地方取,当你在外部数据源取到的时候,可以直接将内容置入到 Cache 中,这样下次就可以命中了 。这里会提到怎么去同步这些数据,两种方式,一种就是在你修改了以后立刻更新 Cache内容,这样就会即时生效。另一种是说容许有失效时间,到了失效时间,自然就会将内容删除,此时再去去的时候就会命中不了,然后再次将内容置入 Cache ,用来更新内容。后者用在一些时时性要求不高,写入不频繁的情况。
客户端的重要性: 客户端设计的合理十分重要,同时也给使用者提供了很大的空间去扩展和设计客户端来满足各种场景的需要,包括容错,权重,效率,特殊的功能性需求,嵌入框架等等。
2> LNMP+memcached+session共享
部署:两台WebServer部署LNMP,配置PHP连接Memcached数据库。
Proxy调度:查看《思维导图(1-20)》
实现方式:
web1 web2
]# vim /etc/php-fpm.d/www.conf //文件的最后2行
php_value[session.save_handler] = memcache
php_value[session.save_path] = "tcp://192.168.2.5:11211"
]# systemctl restart php-fpm
总结:还可以部署高可用,待续...
*************************************
22.安装部署Tomcat服务器、使用Tomcat部署虚拟主机、使用Varnish加速Web
1> Tomcat
Tomcat 服务器是一个免费的开放源代码的Web 应用服务器,Tomcat是Apache 软件基金会(Apache Software Foundation)的Jakarta 项目中的一个核心项目,它早期的名称为catalina,后来由Apache、Sun 和其他一些公司及个人共同开发而成,并更名为Tomcat。Tomcat 是一个小型的轻量级应用服务器,在中小型系统和并发访问用户不是很多的场合下被普遍使用,是开发和调试JSP 程序的首选,因为Tomcat 技术先进、性能稳定,成为目前比较流行的Web 应用服务器。Tomcat是应用(java)服务器,它只是一个servlet容器,是Apache的扩展,但它是独立运行的。目前最新的版本为Tomcat 8.0.24 Released。
Tomcat不是一个完整意义上的Jave EE服务器,它甚至都没有提供对哪怕是一个主要Java EE API的实现;但由于遵守apache开源协议,tomcat却又为众多的java应用程序服务器嵌入自己的产品中构建商业的java应用程序服务器,如JBoss和JOnAS。尽管Tomcat对Jave EE API的实现并不完整,然而很企业也在渐渐抛弃使用传统的Java EE技术(如EJB)转而采用一些开源组件来构建复杂的应用。这些开源组件如Structs、Spring和Hibernate,而Tomcat能够对这些组件实现完美的支持。
总结:
缺点:01. 是轻量级的Web 容器,无法满足复杂业务场景的要求。J2EE规范中的标准容器是web container和EJB containor。另外还要提供诸如JNDI,JMS, JDBC,JMAIL等等的服务,TOMCAT把这些都省略了,要想满足这些功能必须带另外的开源框架产品。
02. 配置简单,但是图形化做的不好,不直观,给非技术用户感觉比较不好
03. 缺少更多的监控功能和接口。运行状态(runtime)的统计数据不多,展示界面不好。
04. 性能稍差
05. 不支持session复制这样的高级功能
06. 缺少多个实例协同工作的设置,集群,多服务器
07. 自动化管理等功能缺失
2> 安装部署Tomcat服务器
环境:java-1.8.0-openjdk ava-1.8.0-openjdk-headless
版本:apache-tomcat-8.0.30
工作目录:/usr/local/tomcat
启动:/usr/local/tomcat/bin/startup.sh
关闭:/usr/local/tomcat/bin/shutdown.sh
端口:tcp6 0 0 :::8080 :::* LISTEN 12448/java
tcp6 0 0 127.0.0.1:8005 :::* LISTEN 12448/java
tcp6 0 0 :::8009 :::* LISTEN 12448/java
配置文件:/usr/local/tomcat/conf/server.xml
3> Tomcat部署虚拟主机 (Proxy调度两台Tomcat WebServer)
配置文件:/usr/local/tomcat/conf/server.xml
支持:页面跳转、SSL加密、日志配置
配置Tomcat集群:
http...
upstream toms {
server web1:8080;
server web2:8080;
...
}
...
location / {
proxy_pass http://toms;
...
4> 部署Varnish加速Web
Varnish:是一个cache型的HTTP反向代理。
原理:Varnish部署上之后,web请求的处理过程会有一些变化。客户端的请求将首先被Varnish接受。Varnish将分析接收的请求,并将其转发到后端的web服务器上。后端的web服务器对请求进行常规的处理,并将依次将处理结果返回给Varnish。
但Varnish的功能并非仅限于此。Varnish的核心功能是能能将后端web服务器返回的结果缓存起来,如果发现后续有相同的请求,Varnish将不会将这个请求转发到web服务器,而是返回缓存中的结果。这将有效的降低web服务器的负载,提升响应速度,并且每秒可以响应更多的请求。Varnish速度很快的另一个主要原因是其缓存全部都是放在内存里的,这比放在磁盘上要快的多。诸如此类的优化措施使得Varnish的相应速度超乎想象。但考虑到实际的系统中内存一般是有限的,所以需要手工配置一下缓存的空间限额,同时避免缓存重复的内容。
环境包:gcc readline-devel ncurses-devel pcre-devel python-docutils-0.11-0.2.20130715svn7687.el7.noarch.rpm
安装包:varnish-5.2.1
启动脚本(配置文件):/varnish-5.2.1/etc/example.vcl
Varnishd 的启动选项
-f : 指定配置文件位置
-a : varnish监听的本地地址和端口。
-P :PID文件位置,用来关闭Varnish
-s :cache配置。默认使用256M内存
启动:
]# varnishd -f /usr/local/etc/default.vcl
//varnishd –s malloc,256M 定义varnish使用内存作为缓存,空间为128M
//varnishd –s file,/var/lib/varnish_storage.bin,1G 定义varnish使用文件作为缓存
总结:Client请求 --> Varnish(未缓存) --> Proxy(轮询) --> WebServer -->Varnish(缓存) --> Client
*************************************
23.Subversion基本操作、使用Subversion协同工作、制作nginx的RPM包
1> Subversion
Subversion是一个自由开源的版本控制系统。在Subversion管理下,文件和目录可以超越时空。Subversion将文件存放在中心版本库里,这个版本库很像一个普通的文件服务器,不同的是,它可以记录每一次文件和目录的修改情况,这样就可以借此将数据恢复到以前的版本,并可以查看数据的更改细节。正因为如此,许多人将版本控制系统当作一种神奇的“时间机器”。
安装包:subversion
主配置文件:/var/svn/project/conf/svnserve.conf
用户密码配置文件:/var/svn/project/conf/passwd
访问权限配置文件:/var/svn/project/conf/authz
常用命令:
]# svnadmin create /var/svn/project
]# svn import . file:///var/svn/project/ -m "Init data"
]# svn --username harry --password 123456 co svn://192.168.2.100/ code
]# svn ci -m
]# svnadmin dump /var/svn/project > project.bak
]# svnadmin load /var/svn/project2 < project.bak
添加文件:add
提交更新:commit(ci)
检出代码:checkout(co)
查看内容:cat
删除文件:del
文件对比:diff
导入代码:import
查看版本:info
文件列表:list
版本历史:log
更新目录:update
创建目录:mkdir
2> Subversion 协同工作
总结:如果多个用户修改相同文件的相同行,则保留冲突,人工解决冲突。
3> 制作RPM包
RPM介绍
RPM 前是Red Hat Package Manager 的缩写,本意是Red Hat 软件包管理,顾名思义是Red Hat 贡献出来的软件包管理;现在应为RPM Package Manager的缩写。在Fedora、Redhat、Mandriva、SuSE、YellowDog等主流发行版本,以及在这些版本基础上二次开发出来的发行版采用; RPM包中除了包括程序运行时所需要的文件,也有其它的文件;一个RPM 包中的应用程序,有时除了自身所带的附加文件保证其正常以外,还需要其它特定版本文件,这就是软件包的依赖关系。
RPM可以让用户直接以binary方式安装软件包,并且可替用户查询是否已经安装了有关的库文件;在用RPM删除程序时,它又会聪明地询问用户是否要删除有关的程序。如果使用RPM来升级软件,RPM会保留原先的配置文件,这样用户就不用重新配置新的软件了。RPM保留一个数据库,这个数据库中包含了所有的软件包的资料,通过这个数据库,用户可以进行软件包的查询。RPM虽然是为Linux而设计的,但是它已经移值到SunOS、Solaris、AIX、Irix等其它UNIX系统上了。RPM遵循GPL版权协议,用户可以在符合GPL协议的条件下自由使用及传播RPM。
安装包:rpm-build
生成rpm包环境:gcc pcre-devel openssl-devel
常用命令:
]# rpmbuild -ba nginx.spec
]# cp nginx-1.12.2.tar.gz /root/rpmbuild/SOURCES/
]# vim /root/rpmbuild/SPECS/nginx.spec //制作
Version:1.12.2
Release: 100
%post
useradd nginx
...
]# rpmbuild -ba /root/rpmbuild/SPECS/nginx.spec //生成
]# rpm -qpi /root/rpmbuild/RPMS/x86_64/nginx-1.12.2-100.x86_64.rpm //查看包信息
]# rpm -ivh /root/rpmbuild/RPMS/x86_64/nginx-1.12.2-100.x86_64.rpm
总结:制作自己的RPM包,YUM源。
*************************************
24.配置GRE VPN,创建PPTP VPN,创建L2TP+IPSec VPN,NTP时间同步,pssh远程套件工具
1> VPN
Virtual Private Network,虚拟专用网络。在公用网络上建立专用网络,进行加密通讯。在企业网络中有广泛应用。VPN网关通过对数据包的加密和数据包目标地址的转换实现远程访问。VPN有多种分类方式,主要是按协议进行分类。VPN可通过服务器、硬件、软件等多种方式实现。
理解:在去北京的高铁(公网)上,给北京的朋友打电话(VPN)。
2> GRE VPN
GRE VPN(Generic Routing Encapsulation)即通用路由封装协议,是对某些网络层协议(如IP和IPX)的数据报进行封装,使这些被封装的数据报能够在另一个网络层协议(如IP)中传输。
GRE是VPN(Virtual Private Network)的第三层隧道协议,即在协议层之间采用了一种被称之为Tunnel(隧道)的技术。
GRE的特点
GRE是一个标准协议
支持多种协议和多播
能够用来创建弹性的VPN
支持多点隧道
能够实施QOS
GRE的缺点
缺乏加密机制
没有标准的控制协议来保持GRE隧道(通常使用协议和keepalive)
隧道很消耗CPU
出现问题要进行DEBUG很困难
MTU和IP分片是一个问题
IPSec VPN 为什么通常要与GRE VPN一起使用?
IPSec建立的隧道在设计时就只支持IP单播,并且也不支持组播,所以IGP动态路由协议的流量不可能穿越IPSec隧道, 并且也不支持非IP协议的流量。
另外,GRE只提供了数据包的封装,它并没有加密功能来防止网络侦听和攻击,不支持对于数据完整性以及身份认证的验证功能。而IPSEC则可以,二者互补。
3> PPTP VPN
PPTP(Point to Point Tunneling Protocol),即点对点隧道协议。该协议是在PPP协议的基础上开发的一种新的增强型安全协议,支持多协议虚拟专用网(VPN),可以通过密码验证协议(PAP)、可扩展认证协议(EAP)等方法增强安全性。可以使远程用户通过拨入ISP、通过直接连接Internet或其他网络安全地访问企业网。
点对点隧道协议(PPTP)是一种支持多协议虚拟专用网络的网络技术,它工作在第二层。
4> L2TP
L2TP,Layer 2 Tunneling Protocol,是一种工业标准的Internet隧道协议,功能大致和PPTP协议类似,比如同样可以对网络数据流进行加密。不过也有不同之处,比如PPTP要求网络为IP网络,L2TP要求面向数据包的点对点连接;PPTP使用单一隧道,L2TP使用多隧道;L2TP提供包头压缩、隧道验证,而PPTP不支持。
5> IPSec
互联网安全协议(Internet Protocol Security,缩写为IPsec),是一个协议包,透过对IP协议的分组进行加密和认证来保护IP协议的网络传输协议族(一些相互关联的协议的集合)。
IPsec协议工作在OSI模型的第三层,使其在单独使用时适于保护基于TCP或UDP的协议(如安全套接子层(SSL)就不能保护UDP层的通信流)。这就意味着,与传输层或更高层的协议相比,IPsec协议必须处理可靠性和分片的问题,这同时也增加了它的复杂性和处理开销。相对而言,SSL/TLS依靠更高层的TCP(OSI的第四层)来管理可靠性和分片。
总结:
一、PPTP
点对点隧道协议 (PPTP) 是由包括微软和3Com等公司组成的PPTP论坛开发的一种点对点隧道协,基于拨号使用的PPP协议使用PAP或CHAP之类的加密算法,或者使用 Microsoft的点对点加密算法MPPE。其通过跨越基于 TCP/IP 的数据网络创建 VPN 实现了从远程客户端到专用企业服务器之间数据的安全传输。PPTP 支持通过公共网络(例如 Internet)建立按需的、多协议的、虚拟专用网络。PPTP 允许加密 IP 通讯,然后在要跨越公司 IP 网络或公共 IP 网络(如 Internet)发送的 IP 头中对其进行封装。
二、L2TP
第 2 层隧道协议 (L2TP) 是IETF基于L2F (Cisco的第二层转发协议)开发的PPTP的后续版本。是一种工业标准 Internet 隧道协议,其可以为跨越面向数据包的媒体发送点到点协议 (PPP) 框架提供封装。PPTP和L2TP都使用PPP协议对数据进行封装,然后添加附加包头用于数据在互联网络上的传输。PPTP只能在两端点间建立单一隧道。 L2TP支持在两端点间使用多隧道,用户可以针对不同的服务质量创建不同的隧道。L2TP可以提供隧道验证,而PPTP则不支持隧道验证。但是当L2TP 或PPTP与IPSEC共同使用时,可以由IPSEC提供隧道验证,不需要在第2层协议上验证隧道使用L2TP。 PPTP要求互联网络为IP网络。L2TP只要求隧道媒介提供面向数据包的点对点的连接,L2TP可以在IP(使用UDP),桢中继永久虚拟电路 (PVCs),X.25虚拟电路(VCs)或ATM VCs网络上使用。
三、IPSec
IPSec 隧道模式隧道是封装、路由与解封装的整个过程。隧道将原始数据包隐藏(或封装)在新的数据包内部。该新的数据包可能会有新的寻址与路由信息,从而使其能够 通 过网络传输。隧道与数据保密性结合使用时,在网络上窃听通讯的人将无法获取原始数据包数据(以及原始的源和目标)。封装的数据包到达目的地后,会删除封 装,原始数据包头用于将数据包路由到最终目的地。
隧道本身是封装数据经过的逻辑数据路径,对原始的源和目的端,隧道是不可见的,而只能看到网络路径中的点对点连接。连接双方并不关心隧道起点和终点之间的任何路由器、交换机、代理服务器或其他安全网关。将隧道和数据保密性结合使用时,可用于提供VPN。
封装的数据包在网络中的隧道内部传输。在此示例中,该网络是 Internet。网关可以是外部 Internet 与专用网络间的周界网关。周界网关可以是路由器、防火墙、代理服务器或其他安全网关。另外,在专用网络内部可使用两个网关来保护网络中不信任的通讯。
当以隧道模式使用 IPSec 时,其只为 IP 通讯提供封装。使用 IPSec 隧道模式主要是为了与其他不支持 IPSec 上的 L2TP 或 PPTP VPN 隧道技术的路由器、网关或终端系统之间的相互操作。
四、SSL VPN
SSL协议提供了数据私密性、端点验证、信息完整性等特性。SSL协议由许多子协议组成,其中两个主要的子协议是握手协议和记录协议。握手协议允许 服务器和客户端在应用协议传输第一个数据字节以前,彼此确认,协商一种加密算法和密码钥匙。在数据传输期间,记录协议利用握手协议生成的密钥加密和解密后 来交换的数据。
SSL独立于应用,因此任何一个应用程序都可以享受它的安全性而不必理会执行细节。SSL置身于网络结构体系的 传输层和应用层之间。此外,SSL本身就被几乎所有的Web浏览器支持。这意味着客户端不需要为了支持SSL连接安装额外的软件。这两个特征就是SSL能 应用于VPN的关键点。
典型的SSL VPN应用如OpenVPN,是一个比较好的开源软件。PPTP主要为那些经常外出移动或家庭办公的用户考虑;而OpenVPN主要是针对企业异地两地总分公司之间的VPN不间断按需连接,例如ERP在企业中的应用。
案例:
]# echo "1" > /proc/sys/net/ipv4/ip_forward //开启路由转发
公网:100.100.100.1 100.100.100.2
隧道:10.10.10.1 10.10.10.2
6> NTP时间同步
TP是网络时间协议(Network Time Protocol),它是用来同步网络中各个计算机的时间的协议。
在计算机的世界里,时间非常地重要,例如对于火箭发射这种科研活动,对时间的统一性和准确性要求就非常地高,是按照A这台计算机的时间,还是按照B这台计算机的时间?NTP就是用来解决这个问题的,NTP(Network Time Protocol,网络时间协议)是用来使网络中的各个计算机时间同步的一种协议。它的用途是把计算机的时钟同步到世界协调时UTC,其精度在局域网内可达0.1ms,在互联网上绝大多数的地方其精度可以达到1-50ms。
安装包:chrony
配置文件:/etc/chrony.conf
服务:chronyd
服务端:allow/deny 192.168.4.0/24
客户端:server 192.168.4.5 iburst
总结:为网络内设备提供标准的时间基准。
7> pssh远程套件工具
安装包:pssh-2.3.1-5.el7.noarch.rpm
常用参数:pssh提供并发远程连接功能
-A 使用密码远程其他主机(默认使用密钥)
-i 将输出显示在屏幕
-H 设置需要连接的主机
-h 设置主机列表文件
-p 设置并发数量
-t 设置超时时间
-o dir 设置标准输出信息保存的目录
-e dir 设置错误输出信息保存的目录
-x 传递参数给ssh
pscp.pssh:批量、多并发拷贝数据到其他主机
pslurp :批量、多并发从其他主机下载数据到本机
pnuke :批量、多并发杀死其他主机的进程
]# pssh -h host.txt -o /tmp/ echo hello
]# pscp.pssh -r(递归) -h host.txt /etc /tmp
]# pslurp -h host.txt /etc/passwd /pass(文件,不是文件夹)
]# pnuke -h host.txt test.sh
总结:批量部署文件
*************************************
25.存储技术与应用 iSCSI技术应用 、 udev配置 NFS网络文件系统 、 Multipath多路径
1> udev配置
udev:一个用户空间程序
总结:udev负责在用户空间,根据用户设置的规则,在监测到设备被插入后,在/dev/下自动创建并命名设备文件节点(实际上只能做一个已存在节点的链接文件),也可以自动设置设备属性。
2> NFS网络文件系统
NFS,(Network File System)即网络文件系统,是FreeBSD支持的文件系统中的一种,它允许网络中的计算机之间通过TCP/IP网络共享资源。在NFS的应用中,本地NFS的客户端应用可以透明地读写位于远端NFS服务器上的文件,就像访问本地文件一样。
优点:
1. 节省本地存储空间,将常用的数据存放在一台NFS服务器上且可以通过网络访问,那么本地终端将可以减少自身存储空间的使用。
2. 用户不需要在网络中的每个机器上都建有Home目录,Home目录可以放在NFS服务器上且可以在网络上被访问使用。
3. 一些存储设备如软驱、CDROM和Zip(一种高储存密度的磁盘驱动器与磁盘)等都可以在网络上被别的机器使用。这可以减少整个网络上可移动介质设备的数量。
服务端:
安装包:nfs-utils rpcbind
配置 :/etc/exports
/root 192.168.2.100(rw,no_root_squash)
/usr/src 192.168.2.0/24(ro)
服务:rpcbiind、nfs
查看:showmount -e localhost
客户端:
安装包:rpcbind
服务 :rpcbind
查看 :showmount -e ServerIP
挂载:192.168.2.5:/usr/src /mnt/nfsdir nfs default,ro 0 0
总结:主要功能是通过网络让不同的机器系统之间可以彼此共享文件和目录。NFS服务器可以允许NFS客户端将远端NFS服务器端的共享目录挂载到本地的NFS客户端中。在本地的NFS客户端的机器看来,NFS服务器端共享的目录就好像自己的磁盘分区和目录一样。一般客户端挂载到本地目录的名字可以随便,但为方便管理,我们要和服务器端一样比较好。
*************************************
26.集群及LVS简介 LVS-NAT集群 LVS-DR集群
1> LVS简介
LVS(Linux Virtual Server)即Linux虚拟服务器。LVS主要用于多服务器的负载均衡。它工作在网络层,可以实现高性能,高可用的服务器集群技术。它廉价,可把许多低性能的服务器组合在一起形成一个超级服务器。它易用,配置非常简单,且有多种负载均衡的方法。它稳定可靠,即使在集群的服务器中某台服务器无法正常工作,也不影响整体效果。另外可扩展性也非常好。
使用LVS架设的服务器集群系统有三个部分组成:最前端的负载均衡层(Loader Balancer),中间的服务器群组层,用Server Array表示,最底层的数据共享存储层,用Shared Storage表示。在用户看来所有的应用都是透明的,用户只是在使用一个虚拟服务器提供的高性能服务。
安装包:ipvsadm
模式:
基于NAT的LVS模式负载均衡 -m
基于DR的LVS负载均衡 -g
基于TUN的LVS负载均衡 -i
算法:
轮询调度: rr (Round Robin)
加权轮询调度: wrr (Weight Round Robin)
最小连接调度: lc (Least Connections)
加权最小连接调度: wlc (Weight Least Connections)
2> LVS集群:虚拟服务器里添加真实服务器
虚拟服务器设置算法:轮询、加权轮询、最少连接算法
真实服务器设置工作模式:DR模式、隧道模式、NAT模式
3> LVS-NAT模式 每个RS都有VIP(隐藏的)
CIP-->VIP ...IPVS... CIP-->RIP ...RS回数据包... RIP-->CIP...IPVS...VIP-->CIP
client发送request到LVS的VIP上,VIP根据负载算法选择一个Real-server,并记录连接信息到hash表中,然后修改client的request的目的IP地址为Real-server的地址,将请求发给Real-server; Real-server收到request包后,发现目的IP是自己的IP,于是处理请求,然后发送reply给LVS; LVS收到reply包后,修改reply包的的源地址为VIP,发送给client。
从client来的属于本次连接的包,查hash表,然后发给对应的Real-server; 当client发送完毕,此次连接结束或者连接超时,那么LVS自动从hash表中删除此条记录。(20-30台)
总结:real-server,集群组提供相同服务,LVS实现负载均衡(算法),调度器配置http的80端口,新加的RS同步80端口,设置工作模式。
4> LVS-DR模式(数据链路层)
CIP-->VIP ...DIR-算法-修改数据包目标mac地址-->real server... CIP-->VIP ...RS回数据包... VIP-->CIP
每个Real Server上都有两个IP:VIP和RIP,但是VIP是隐藏的,就是不能提供解析等功能,只是用来做请求回复的源IP的,Director上只需要一个网卡,然后利用别名来配置两个IP:VIP和DIP,在DIR接收到客户端的请求后,DIR根据负载算法选择一台RS的网卡mac作为客户端请求包中的目标mac,通过arp转交给后端RS处理,后端再通过自己的路由网关回复给客户端。(100台左右)。`
5> LVS-TUN模式 每个RS都有VIP
CIP-->VIP ...DR添加一层包头(DIP-->RIP,可以是外网)...RS拆包发现(CIP-VIP),自己有VIP...RS回包...VIP-->CIP
它的连接调度和管理与VS/NAT中的一样,利用ip隧道技术的原理,即在原有的客户端请求包头中再加一层IP Tunnel的包头ip首部信息,不改变原来整个请求包信息,只是新增了一层ip首部信息,再利用路由原理将请求发给RS,不过要求的是所有的server必须持”IPTunneling”或者”IP Encapsulation”协议。(300台左右)
总结:默认LVS不带健康检查功能
NAT模式--修改CIP-->VIP,DR修改目标地址为RIP,CIP-->RIP,RS有VIP;
DR模式 --修改mac为RS的mac,即CIP-->VIP(DR的mac),修改为CIP-->VIP(RS的mac),RS有VIP;
TUN模式--CIP-->VIP,DR封装一层包头:(DIP-->RIP),内部还是CIP-->VIP,RS有VIP。
负载均衡:nginx负载均衡,LVS负载均衡
*************************************
27.Keepalived热备 Keepalived+LVS 、HAProxy服务器
1> Keepalived
keepalived是基于VRRP协议实现的保证集群高可用的一个服务软件,主要功能是实现真机的故障隔离和负载均衡器间的失败切换,防止单点故障。在了解keepalived原理之前先了解一下VRRP协议。
VRRP协议:Virtual Route Redundancy Protocol,虚拟路由冗余协议。是一种容错协议,保证当主机的下一跳路由出现故障时,由另一台路由器来代替出现故障的路由器进行工作,从而保持网络通信的连续性和可靠性。
虚拟路由器:由一个 Master 路由器和多个 Backup 路由器组成。主机将虚拟路由器当作默认网关。
Keepalived是Linux下一个轻量级别的高可用解决方案。高可用:广义来讲,是指整个系统的高可用行;狭义的来讲就是主机的冗余和接管。
软件包:keepalived
配置文件:/etc/keepalived/keepalived.conf
服务:keepalived
案例:多台WebServer部署keepalived
主(master)服务器的priority最高,浮动IP绑定主服务器。
测试:Master宕机,查看浮动IP绑定情况,以及主备服务器变化。
总结:Keepalived是Linux下一个轻量级别的高可用解决方案。高可用:广义来讲,是指整个系统的高可用行;狭义的来讲就是主机的冗余和接管。
web1、web2配置了部署Keepalived高可用软件,客户端在访问浮动IP的时候,访问的是master节点的服务器,master宕机后,浮动IP漂浮到backup节点,客户端访问浮动IP的时候,实际访问的是backup节点。
2> Keepalived+LVS
原因:LVS调度器实现了WebServer的负载均衡,那LVS调度器挂了怎么办?
配置两台主备LVS调度服务器,实现LVS调度器的高可用。
Keepalived的项目实现的主要目标是简化LVS项目的配置并增强其稳定性,即Keepalived是对LVS项目的扩展增强。Keepalived为Linux系统和基于Linux 的架构提供了负载均衡和高可用能力,其负载均衡功能主要源自集成在Linux内核中的LVS项目模块IPVS( IP Virtual Server ),基于IPVS提供的4 层TCP/IP协议负载均衡,Keepalived也具备负载均衡的功能。
此外, Keepalived还实现了基于多层TCP/IP 协议( 3 层、4 层、5/7 层)的健康检查机制,因此,Keepalived在LVS负载均衡功能的基础上,还提供了LVS集群物理服务器池健康检查和故障节点隔离的功能。
除了扩展LVS的负载均衡服务器健康检查能力,Keepalived 还基于虚拟路由冗余协议( Virtual Route Redundancy Protocol, VRRP )实现了LVS负载均衡服务器的故障切换转移,即Keepalived还实现了LVS负载均衡器的高可用性。Keepalived 就是为LVS 集群节点提供健康检查和为LVS负载均衡服务器提供故障切换的用户空间进程。
3> HAProxy服务器
HAProxy是一个使用C语言编写的自由及开放源代码软件,其提供高可用性、负载均衡,以及基于TCP和HTTP的应用程序代理。HAProxy特别适用于那些负载特大的web站点,这些站点通常又需要会话保持或七层处理。HAProxy运行在当前的硬件上,完全可以支持数以万计的并发连接。并且它的运行模式使得它可以很简单安全的整合进您当前的架构中,同时可以保护你的web服务器不被暴露到网络上。
HAProxy跟LVS类似,本身就只是一款负载均衡软件;单纯从效率上来讲,HAProxy会比Nginx有更出色的负载均衡速度,在并发处理上也是优于Nginx的。
软件包:haproxy
配置文件:/etc/haproxy/haproxy.cfg
服务:haproxy
访问:firefox http://192.168.4.5:1080/stats ;
应用:Proxy安装haproxy软件调度(算法)后端WebServer,自带健康检查和可视化管理与查看。
总结:Nginx调度 LVS调度 Haproxy调度
*************************************
28.Ceph概述 部署Ceph集群 Ceph块存储
1> 分布式文件系统
分布式文件系统,Distributed File System,是指文件系统管理的物理存储资源不一定直接连接在本地节点上,而是通过计算机网络与节点相连。分布式文件系统的设计基于客户机/服务器模式。一个典型的网络可能包括多个供多用户访问的服务器。另外,对等特性允许一些系统扮演客户机和服务器的双重角色。
2> 软件定义存储
软件定义存储就是将存储硬件中的典型的存储控制器功能抽出来放到软件上。这些功能包括卷管理、RAID、数据保护、快照和复制等。软件定义存储允许用户不必从特定厂商采购存储控制器硬件如硬盘、闪存等存储介质。并且,如果存储控制器功能被抽离出来,该功能就可以放在基础架构的任何一部分。它可以运行在特定的硬件上,在hypervisor内部,或者与虚机并行,形成真正的融合架构。
3> 软件定义网络
软件定义网络SDN(Software Defined Network)是由美国斯坦福大学CLean State研究组提出的一种新型网络创新架构,可通过软件编程的形式定义和控制网络,其控制平面和转发平面分离及开放性可编程的特点,被认为是网络领域的一场革命,为新型互联网体系结构研究提供了新的实验途径,也极大地推动了下一代互联网的发展。
4> 软件定义数据中心
软件定义数据中心(Softwares Defined Data Center,SDDC)解决的最核心的问题是让客户以更小的代价来获得更灵活的、快速的业务部署、管理及实现。常说的互联网模式在技术核心上的问题几乎都可以归结为SDDC,三大优势:
01.敏捷性(agility): 更快、更灵活的业务支撑与实现(以及软件开发模式的优化与变更);
02.弹性(Elasticity):随业务需求的资源的动态可伸缩性(水平+垂直);
03.省钱(Cost-efficiency):软件实现避免了重复硬件投资和资源浪费。
5> 对象存储
对象存储,也叫做基于对象的存储,是用来描述解决和处理离散单元的方法的通用术语,这些离散单元被称作为对象。
就像文件一样,对象包含数据,但是和文件不同的是,对象在一个层结构中不会再有层级结构。每个对象都在一个被称作存储池的扁平地址空间的同一级别里,一个对象不会属于另一个对象的下一级。
文件和对象都有与它们所包含的数据相关的元数据,但是对象是以扩展元数据为特征的。每个对象都被分配一个唯一的标识符,允许一个服务器或者最终用户来检索对象,而不必知道数据的物理地址。这种方法对于在云计算环境中自动化和简化数据存储有帮助。
对象存储系统(Object-Based Storage System)是综合了NAS和SAN的优点,同时具有SAN的高速直接访问和NAS的数据共享等优势,提供了高可靠性、跨平台性以及安全的数据共享的存储体系结构。
6> DAS、SAN、NAS存储
DAS(Direct-attached Storage) 直连存储;
NAS(Network Attached Storage) 网络附加存储——是一个网络上的文件系统(文件系统存储,NFS);
SAN(Storage Area Network) 存储区域网络——是一个网络上的磁盘(块存储);
1.jpg
7> Ceph概述
Ceph是一个可靠地、自动负载均衡、自动恢复的分布式存储系统,根据场景划分可以将Ceph分为三大块,分别是对象存储、块设备存储和文件系统服务。在虚拟化领域里,比较常用到的是Ceph的块设备存储,比如在OpenStack项目里,Ceph的块设备存储可以对接OpenStack的cinder后端存储、Glance的镜像存储和虚拟机的数据存储,比较直观的是Ceph集群可以提供一个raw格式的块存储来作为虚拟机实例的硬盘。
Ceph相比其它存储的优势点在于它不单单是存储,同时还充分利用了存储节点上的计算能力,在存储每一个数据时,都会通过计算得出该数据存储的位置,尽量将数据分布均衡,同时由于Ceph的良好设计,采用了CRUSH算法、HASH环等方法,使得它不存在传统的单点故障的问题,且随着规模的扩大性能并不会受到影响。
8> ceph组件:
OSDs:数据存储设备
Monitors:集群监控组件
RBD:对象存储网关
MDSs:存放文件系统的元数据(对象存储和块存储不需要该组件)
Client:ceph客户端
9> 部署Ceph集群
软件包:ceph-deploy
过程:
01,部署Ceph集群(多台主机)
创建Ceph集群 --> 集群主机装包 --> 初始化所有节点的mon服务
02,创建OSD(多台主机)
创建JOURNAL缓存盘 关联 OSD存储设备,一一对应,一个存储设备对应一个缓存设备,缓存需要SSD,不需要很大。
集群所有OSD存储设备空间总和(缓存盘不算)为Ceph集群OSD总存储空间。
03,ceph -s #查看集群状态
10> Ceph块存储(磁盘)
Ceph集群池创建块存储镜像(支持动态调整)-->客户端映射镜像(将镜像映射为本地磁盘)-->格式化挂载使用(使用后客户端写入的数据在ceph磁盘里)
创建镜像快照:对客户端写入数据的ceph块磁盘做快照-->客户端误删数据-->客户端离线回滚-->数据恢复
快照克隆:复制一份已备份快照,如果希望克隆镜像可以独立工作,就需要将父快照中的数据,全部拷贝一份,但比较耗时。
*************************************
29.块存储应用案例 分布式文件系统 对象存储
1> 块存储应用案例
目标:真机创建虚拟机的时候,其配置文件调用Ceph集群块存储
实现:Ceph集群一台虚拟机创建磁盘镜像;
创建Ceph认证账户,客户端需要账户才可以访问Ceph块存储;
部署真机(客户端)环境(拷贝虚拟机Ceph配置文件,ceph.client.admin.keyring);
客户端使用XML配置文件创建secret,生成用户信息,用户名,秘钥;
客户端修改新创建的虚拟机配置文件,指向Ceph集群的块存储
2> 分布式文件系统
文件系统存储:不用分盘,不用格式化,直接使用
分布式文件系统:使用ceph磁盘镜像创建的文件系统,客户端挂载直接使用
用到组件:MDSs:存放文件系统的元数据(元数据服务器)
实现:创建存储池(cephfs_data:block数据盘,类似磁盘划分);
创建存储池(cephfs_metadata:元数据,类似格式化);
用元数据cephfs_metadata 和 数据盘cephfs_data 创建文件系统;
客户端挂载(不用格式化,已经是文件系统)。
(元数据 :真实数据的描述信息、指针(数据定位)
( block:真实数据)
3> 对象存储
对象存储:只能通过API访问
Ceph 对象存储可以简称为 RGW,Ceph RGW 是基于 librados,为应用提供 RESTful 类型的对象存储接口,其接口方式支持 S3(兼容 Amazon S3 RESTful API)和 Swift(兼容 OpenStack Swift API)两种类型。
用到组件:RBD(对象存储网关)
实现:新建网关实例,启动一个rgw服务;
修改端口(7480->8000),重启服务;
创建RGW访问账户 ,生成用户名和秘钥;
客户端通过s3cmd连接对象存储服务器。
*************************************
30.数据库服务概述 构建MySQL服务器 、数据库基本管理 MySQL数据类型
1> 数据库,简而言之可视为电子化的文件柜——存储电子文件的处所,用户可以对文件中的数据进行新增、截取、更新、删除等操作。
所谓“数据库”是以一定方式储存在一起、能与多个用户共享、具有尽可能小的冗余度、与应用程序彼此独立的数据集合。
2> 构建MySQL服务器
版本:5.7.17
配置文件:/etc/my.cnf
安装路径:/var/lib/mysql
服务:mysqld
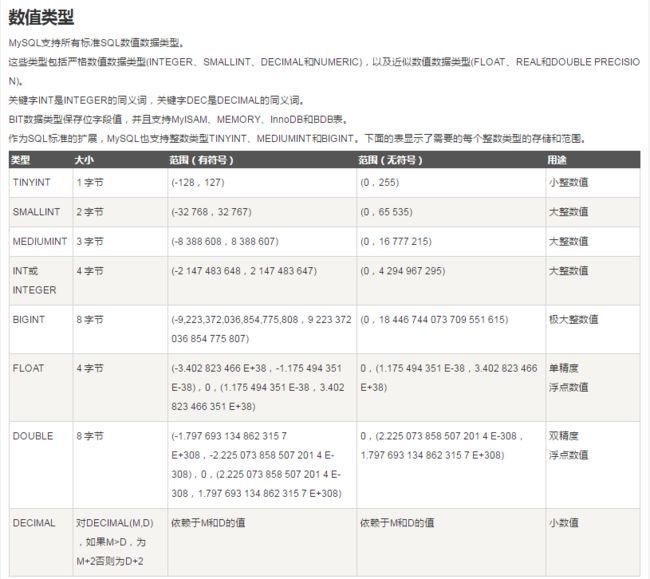
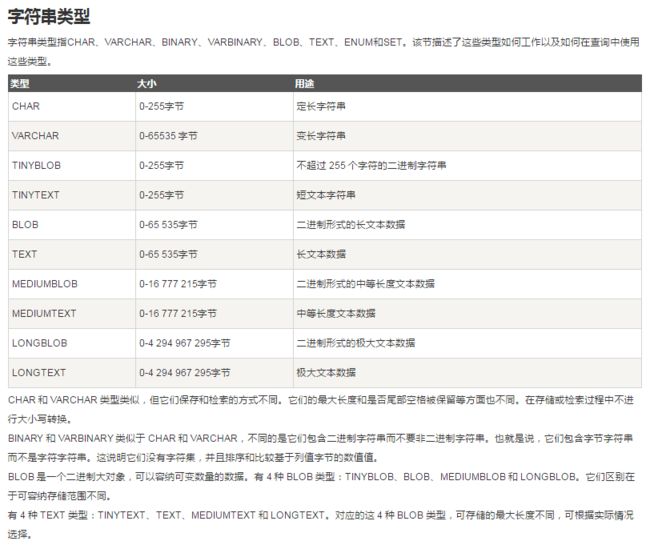
3> MySQL数据类型
*************************************
31.MySQL存储引擎 、 数据导入导出 管理表记录 匹配条件
1> MySQL存储引擎
如果要提供提交、回滚、崩溃恢复能力的事物安全(ACID兼容)能力,并要求实现并发控制,InnoDB是一个好的选择。
如果数据表主要用来插入和查询记录,则MyISAM引擎能提供较高的处理效率。
如果只是临时存放数据,数据量不大,并且不需要较高的数据安全性,可以选择将数据保存在内存中的Memory引擎,MySQL中使用该引擎作为临时表,存放查询的中间结果。
如果只有INSERT和SELECT操作,可以选择Archive,Archive支持高并发的插入操作,但是本身不是事务安全的。Archive非常适合存储归档数据,如记录日志信息可以使用Archive。
使用哪一种引擎需要灵活选择,一个数据库中多个表可以使用不同引擎以满足各种性能和实际需求,使用合适的存储引擎,将会提高整个数据库的性能。
2> 数据导入导出
mysql> LOAD DATA INFILE '/var/lib/mysql-files/passwd'
-> INTO TABLE user
-> FIELDS TERMINATED BY ':'
-> LINES TERMINATED BY '\n';(这条默认有,除非用其他分隔用)
mysql> SELECT * FROM userdb.user1 WHERE uid<5
-> INTO OUTFILE '/myload/user1.txt'
-> FIELDS TERMINATED BY ':';
*************************************
32.多表查询 MySQL管理工具 、用户授权及撤销
1> 部署LAMP+phpMyAdmin平台
版本:phpMyAdmin-2.11.11
MySQL:5.7.17
Nginx:1.12.2
php-fpm:5.4.16
配置文件:
phpMyAdmin]# cp config.sample.inc.php config.inc.php
2> 用户授权 与撤销
mysql> GRANT all ON *.* TO zs@localhost(仅本地可登)
-> IDENTIFIED BY '1234567'
-> WITH GRANT OPTION;
mysql> REVOKE all ON webdb.* FROM webuser@'%';
*************************************
33.mysqldump 实时增量备份、innobackupex
1.> mysqldump是mysql用于转存储数据库的实用程序。它主要产生一个SQL脚本,其中包含从头重新创建数据库所必需的命令CREATE TABLE INSERT等。
mysqldump 可产生两种类型的输出文件,取决于是否选用- -tab=dir_name选项。
不使用- -tab=dir_name选项,mysqldump产生的数据文件是纯文本的SQL文件,又CREATE(数据库、表、存储路径等)语句和INSERT(记录)语句组成。输出结果以一个文件保存,可以用mysql命令去恢复备份文件。
使用- -tab=dir_name选项,mysqldump对于每一个需备份的数据表产生两个输出文件:一个是带分隔符的文本文件,备份的数据表中的每行存储为文本中的一行,以“表名.txt”保存;另一个输出文件为数据表的CREATE TABLE语句,以“表名.sql”保存。
备份所有库:
]# mysqldump -u root -p123456 --all-databases > /root/alldb.sql
恢复userdb库:
]# mysql -u root -p123456 userdb2 < /root/userdb.sql
2> 对于MySQL的备份,可分为以下两种:
1. 冷备
2. 热备
其中,冷备,顾名思义,就是将数据库关掉,利用操作系统命令拷贝数据库相关文件。而热备指的是在线热备,即在不关闭数据库的情况下,对数据库进行备份。实际生产中基本上都是后者。
关于热备,也可分为两种方式:
1. 逻辑备份
2. 物理备份
对于前者,常用的工具是MySQL自带的mysqldump,对于后者,常用的工具是Percona提供的XtraBackup。
对于规模比较小,业务并不繁忙的数据库,一般都是选择mysqldump。
3> 开启binlog日志
server_id=50
log-bin=mysql50
binlog_format=STATEMENT
Binlog日志的三种模式
1.1 Statement Level模式
每一条修改数据的sql都会记录到master的bin_log中,slave在复制的时候sql进程会解析成master端执行过的相同的sql在slave库上再次执行。
优点:statement level下的优点首先就是解决了row level下的缺点,不需要记录每一行的变化,较少bin-log日志量,节约IO,提高性能。因为它只需要记录在master上所执行的语句的细节,以及执行语句时候的上下文信息。
缺点:由于它是记录执行语句,所以,为了让这些语句在slave端也能正确执行,那么它还必须记录每条语句在执行的时候的一些相关信息,也就是上下文信息,来保证所有语句在slave端能够得到和在master端相同的执行结果。由于mysql更新较快,使mysql的赋值遇到了不小的挑战,自然赋值的时候就会涉及到越复杂的内容,bug也就容易出现。在statement level下,目前就已经发现了不少情况会造成mysql的复制出现问题,主要是修改数据的时候使用了某些特定的函数或者功能的时候会出现。比如:sleep()函数在有些版本中就不能正确赋值,在存储过程中使用了last_insert_id()函数,可能会使slave和master上得到不一致的id等等。由于row level是基于每一行记录的裱花,所以不会出现类似的问题。
总结:
Statement level优点:
1、解决了row level的缺点,不需要记录每一行的变化。
2、日志量少,节约IO,从库应用日志块。
Statement level缺点:一些新功能同步可能会有障碍,比如函数、触发器等。
1.2 Row Level模式
日志中会记录成每一行数据修改的形式,然后在slave端再对相同的数据进行修改。
优点:在row level的模式下,bin_log中可以不记录执行的sql语句的上下文信息,仅仅只需要记录哪一条记录被修改,修改成什么样。所以row level的日志内容会非常清楚的记录每一行数据修改的细节,非常容易理解。而且不会出现某些特定情况下的存储过程,或fuction,以及trigger的调用或处罚无法被正确复制的问题。
缺点:row level模式下,所有的执行语句都会记录到日志中,同时都会以每行记录修改的来记录,这样可能会产生大量的日志内容。
总结:
row level的优点:
1、记录详细
2、解决statement level模式无法解决的复制问题。
row level的缺点:日志量大,因为是按行来拆分。
1.3 Mixed模式(混合模式)
实际上就是前两种模式的结合,在mixed模式下,mysql会根据执行的每一条具体的sql语句来区分对待记录的日志形式,也是在statement和row之间选择一种。
新版本中的mysql中对row level模式也做了优化,并不是所有的修改都会以row level来记录,像遇到表结构变更的时候就会以statement模式来记录,如果sql语句确实就是update或者delete等修改数据的语句,那么还是会记录所有行的变更。
1.4 通过binlog日志恢复数据
# at 645...
INSERT INTO...
... ...
COMMIT/*!*/;
# at 799
4> innobackupex备份工具
innobackupex是percona提供的一个使用perl语言完成的脚本工具。此工具调用xtrabackup和tar4ibd工具,实现很多对性能要求并不高的任务和备份逻辑。
完整备:
]# innobackupex --user=root --password=1234567 /backup --no-timestamp
增量备1:
]# innobackupex --user=root --password=1234567 --incremental /incr01 --incremental-basedir=/backup --no-timestamp
增量备2:
]# innobackupex --user=root --password=1234567 --incremental /incr02 --incremental-basedir=/incr01 --no-timestamp
准备恢复:
]# innobackupex --user=root --password=1234567 --apply-log --redo-only /backup/
to_lsn = 2994642
last_lsn = 2994651
合并/incr01
]# innobackupex --user=root --password=1234567 --apply-log --redo-only /backup/ --incremental-dir=/incr01
to_lsn = 3000744
last_lsn = 3000753
合并/incr02
]# innobackupex --user=root --password=1234567 --apply-log --redo-only /backup/ --incremental-dir=/incr02
to_lsn = 3011372
last_lsn = 3011381
]# cat /incr01/xtrabackup_checkpoints
from_lsn = 2994642
to_lsn = 3000744
last_lsn = 3000753
]# cat /incr02/xtrabackup_checkpoints
from_lsn = 3000744
to_lsn = 3011372
last_lsn = 3011381
恢复所有数据
]# innobackupex --copy-back /backup
#########################################
#########备份过程#########
如果在程序启动阶段未指定模式,innobackupex将会默认以备份模式启动。
默认情况下,此脚本以--suspend-at-end选项启动xtrabackup,然后xtrabackup程序开始拷贝InnoDB数据文件。当xtrabackup程序执行结束,innobackupex将会发现xtrabackup创建了xtrabackupsuspended2文件,然后执行FLUSH TABLES WITH READ LOCK,此语句对所有的数据库表加读锁,然后开始拷贝其他类型的文件。
如果--ibbackup未指定,innobackupex将会自行尝试确定使用的xtrabackup的binary。其确定binary的逻辑如下:首先判断备份目录中xtrabackup_binary文件是否存在,如果存在,此脚本将会依据此文件确定使用的xtrabackup binary。否则,脚本将会尝试连接database server,通过server版本确定binary。如果连接无法建立,xtrabackup将会失败,需要自行指定binary文件。
在binary被确定后,将会检查到数据库server的连接是否可以建立。其执行逻辑是:建立连接、执行query、关闭连接。若一切正常,xtrabackup将以子进程的方式启动。
FLUSH TABLES WITH READ LOCK是为了备份MyISAM和其他非InnoDB类型的表,此语句在xtrabackup已经备份InnoDB数据和日志文件后执行。在这之后,将会备份 .frm, .MRG, .MYD, .MYI, .TRG, .TRN, .ARM, .ARZ, .CSM, .CSV, .par, and .opt 类型的文件。
当所有上述文件备份完成后,innobackupex脚本将会恢复xtrabackup的执行,等待其备份上述逻辑执行过程中生成的事务日志文件。接下来,表被解锁,slave被启动,到server的连接被关闭。接下来,脚本会删掉xtrabackupsuspended2文件,允许xtrabackup进程退出。
#########恢复过程#########
为了恢复一个备份,innobackupex需要以--copy-back选项启动。
innobackupex将会首先通过my.cnf文件读取如下变量:datadir, innodb_data_home_dir, innodb_data_file_path, innodb_log_group_home_dir,并确定这些目录存在。
接下来,此脚本将会首先拷贝MyISAM表、索引文件、其他类型的文件(如:.frm, .MRG, .MYD, .MYI, .TRG, .TRN, .ARM, .ARZ, .CSM, .CSV, par and .opt files),接下来拷贝InnoDB表数据文件,最后拷贝日志文件。拷贝执行时将会保留文件属性,在使用备份文件启动MySQL前,可能需要更改文件的owener(如从拷贝文件的user更改到mysql用户)。
#########################################
*************************************
34.MySQL主从同步、主从同步模式
mysql主从复制用途
实时灾备,用于故障切换
读写分离,提供查询服务
备份,避免影响业务
主从部署必要条件:
主库开启binlog日志(设置log-bin参数)
主从server-id不同
从库服务器能连通主库
mysql主从复制原理:
从库生成两个线程,一个I/O线程,一个SQL线程;
i/o线程去请求主库 的binlog,并将得到的binlog日志写到relay log(中继日志) 文件中;
主库会生成一个 log dump 线程,用来给从库 i/o线程传binlog;
在没开启log_slave_updates时, Replay log的记录操作不会写进binlog里.
SQL 线程,会读取relay log文件中的日志,并解析成具体操作,来实现主从的操作一致,而最终数据一致;
同步模式
异步复制(Asynchronous replication)
主库在执行完客户端提交的事务后会立即将结果返给客户端,并不关心从库是否已经接收并处理。
全同步复制(Fully synchronous replication)
当主库执行完一个事务,所有的从库都执行了该事务才返回给客户端。
半同步复制(Semisynchronous replication)
介于异步复制和全同步复制之间,主库在执行完客户端提交的事务后不是立刻返回给客户端,而是等待至少一个从库接收到并写到relay log中才返回给客户端。
-- 基本应用
单向复制:主 --> 从
-- 扩展应用
链式复制:主 --> 从 --> 从
双向复制:主 <--> 从
放射式复制:从 <-- 主 --> 从
配置:主 --> 从
实现:配置文件:
[mysqld]
log-bin=master51
server_id=51
binlog_format="mixed"
...
主库授权;
从库指定主库;
测试:Master写的数据可以同步到Slave上
配置:主(51) --> 从(52) --> 从(53)
实现:配置文件:
[mysqld]
log-bin=master51
server_id=51
binlog_format="mixed"
...
主库授权;
从库指定主库;
检测:
51写的数据会同步到52,53
52写的数据会同步到53
配置半同步复制模式
plugin-load=rpl_semi_sync_master=semisync_master.so
rpl_semi_sync_master_enabled=1
plugin-load=rpl_semi_sync_slave=semisync_slave.so
rpl_semi_sync_slave_enabled=1
*************************************
35.MySQL读写分离 MySQL多实例 、MySQL性能调优
1> MySQL 主从复制+读写分离
Mysql作为目前世界上使用最广泛的免费数据库,相信所有从事系统运维的工程师都一定接触过。但在实际的生产环境中,由单台Mysql作为独立的数据库是完全不能满足实际需求的,无论是在安全性,高可用性以及高并发等各个方面。
因此,一般来说都是通过 主从复制(Master-Slave)的方式来同步数据,再通过读写分离(MySQL-Proxy)来提升数据库的并发负载能力 这样的方案来进行部署与实施的。
what 读写分离
读写分离,基本的原理是让主数据库处理事务性增、改、删操作(INSERT、UPDATE、DELETE),而从数据库处理SELECT查询操作。数据库复制被用来把事务性操作导致的变更同步到集群中的从数据库。
why 那么为什么要读写分离呢?
因为数据库的“写”(写10000条数据到oracle可能要3分钟)操作是比较耗时的。
但是数据库的“读”(从oracle读10000条数据可能只要5秒钟)。
所以读写分离,解决的是,数据库的写入,影响了查询的效率。
when 什么时候要读写分离?
数据库不一定要读写分离,如果程序使用数据库较多时,而更新少,查询多的情况下会考虑使用,利用数据库 主从同步 。可以减少数据库压力,提高性能。当然,数据库也有其它优化方案。memcache 或是 表折分,或是搜索引擎。都是解决方法。
复制的工作过程
1) 在每个事务更新数据完成之前,master在二进制日志记录这些改变。写入二进制日志完成后,master通知存储引擎提交事务。
2) Slave将master的binary log复制到其中继日志。首先slave开始一个工作线程(I/O),I/O线程在master上打开一个普通的连接,然后开始binlog dump process。binlog dump process从master的二进制日志中读取事件,如果已经跟上master,它会睡眠并等待master产生新的事件,I/O线程将这些事件写入中继日志。
3) Sql slave thread(sql从线程)处理该过程的最后一步,sql线程从中继日志读取事件,并重放其中的事件而更新slave数据,使其与master中的数据一致,只要该线程与I/O线程保持一致,中继日志通常会位于os缓存中,所以中继日志的开销很小。
2> 配置读写分离服务器 MaxScale
MaxScale是maridb开发的一个mysql数据中间件,其配置简单,能够实现读写分离,并且可以根据主从状态实现写库的自动切换。
Client-->sql请求-->MaxScale(路由转发):
非读:Master
读:Slave1、Slave2...
MaxScale 是MySQL的兄弟公司 MariaDB 开发的,现在已经发展得非常成熟。MaxScale 是插件式结构,允许用户开发适合自己的插件。
MaxScale 目前提供的插件功能分为5类:
认证插件
提供了登录认证功能,MaxScale 会读取并缓存数据库中 user 表中的信息,当有连接进来时,先从缓存信息中进行验证,如果没有此用户,会从后端数据库中更新信息,再次进行验证。
协议插件
包括客户端连接协议,和连接数据库的协议。
路由插件
决定如何把客户端的请求转发给后端数据库服务器,读写分离和负载均衡的功能就是由这个模块实现的。
监控插件
对各个数据库服务器进行监控,例如发现某个数据库服务器响应很慢,那么就不向其转发请求了。
日志和过滤插件
提供简单的数据库防火墙功能,可以对SQL进行过滤和容错。
版本:maxscale-2.1.2-1
配置文件:/etc/maxscale.cnf
读写分离服务器:调度器,跳板,读就到从库,写,就到主库。
3> MySQL多实例:单台主机运行多个独立mysqld服务。
4> MySQL性能调优
并发连接数量:Max_used_connections | 4
默认的最大连接数: max_connections | 151
连接超时时间:"%timeout%"
允许保存在缓存中被重用的线程数量: thread_cache_size | 9
引擎的关键索引缓存大小: key_buffer_size | 8388608
为每个要排序的线程分配此大小的缓存空间:sort_buffer_size | 262144
为顺序读取表记录保留的缓存大小 read_buffer_size | 131072
为所有线程缓存的打开的表的数量: table_open_cache | 2000
SQL查询优化 启用慢查询日志
MySQL的慢查询日志是MySQL提供的一种日志记录,它用来记录在MySQL中响应时间超过阀值的语句,具体指运行时间超过long_query_time值的SQL,则会被记录到慢查询日志中。long_query_time的默认值为10,意思是运行10S以上的语句。默认情况下,Mysql数据库并不启动慢查询日志,需要我们手动来设置这个参数,当然,如果不是调优需要的话,一般不建议启动该参数,因为开启慢查询日志会或多或少带来一定的性能影响。慢查询日志支持将日志记录写入文件,也支持将日志记录写入数据库表。
并发连接数量:Max_used_connections | 4
查看默认的最大连接数:max_connections | 151
连接超时时间: show variables like "%timeout%";
允许保存在缓存中被重用的线程数量:| thread_cache_size | 9
用于MyISAM引擎的关键索引缓存大小:| key_buffer_size | 8388608
为每个要排序的线程分配此大小的缓存空间:sort_buffer_size | 262144
为顺序读取表记录保留的缓存大小:read_buffer_size | 131072
为所有线程缓存的打开的表的数量:| table_open_cache | 2000
启用慢查询日志:
slow_query_log=1
slow_query_log_file=mysql-slow.log
long_query_time=5
log_queries_not_using_indexes=1
查看缓存的大小
mysql> show variables like "query_cache%";
查看当前的查询缓存统计
mysql> show global status like "qcache%";
查看慢查询日志
]# mysqldumpslow /var/lib/mysql/mysql-slow.log
*************************************
36.MHA集群概述 、部署MHA集群 测试配置
MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司youshimaton(现就职于Facebook公司)开发,是一套优秀的作为MySQL高可用性环境下故障切换和主从提升的高可用软件。在MySQL故障切换过程中,MHA能做到在0~30秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中,MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用。
该软件由两部分组成:MHA Manager(管理节点)和MHA Node(数据节点)。MHA Manager可以单独部署在一台独立的机器上管理多个master-slave集群,也可以部署在一台slave节点上。MHA Node运行在每台MySQL服务器上,MHA Manager会定时探测集群中的master节点,当master出现故障时,它可以自动将最新数据的slave提升为新的master,然后将所有其他的slave重新指向新的master。整个故障转移过程对应用程序完全透明。
1> 配置MHA集群
51主节点,52,53备用主节点,54,55从节点,56MHA Manager VIP:51上
实现:
在管理主机上安装mha_node 和 mha-manager包(56操作);
配置主节点 master51;
配置两个备用主节点 master52、master53;
配置两个从节点 slave54、slave55;
配置管理节点 mgm56;
验证配置;
*************************************
37.MySQL视图 MySQL存储过程
1> MySQL视图
什么是视图:是一种虚拟存在的表
内容与真实的表相似,包含一系列带有名称的列和行数据。
视图并不在数据库中以存储的数据的形式存在。
行和列的数据来自定义视图时查询所引用的基本表,并且在具体引用视图时动态生成。
更新视图的数据,就是更新基表的数据,更新基表数据,视图的数据也会跟着改变。
总结:视图数据来源相当于查询基表数据时产生的动态缓存。
2> WITH LOCAL CHECK OPTION
WITH LOCAL CHECK OPTION
会检验视图v4 WHERE 子句下的条件,然后检验底层视图v3的WHERE子句条件
WITH CASCADED CHECK OPTION
会检查视图v4 WHERE子句下的条件,然后检查底层视图v3的WHERE子句条件
没有check option
不会检查视图v4 WHERE子句下的条件,但会检查底层视图三的WHERE子句条件
03:MySQL存储过程
in 输入参数 传递值给存储过程,必须在调用存储过程时指定,在存储过程中不能修改该参数的值;默认类型是in。
out 输出参数该值可在存储过程内部被改变,并可返回
inout 输入/输出参数调用时指定,并且可被改变和返回
总结:数据库中定义函数,调用函数
*************************************
38.搭建mycat 分片服务器
1> 分库分表
据库中的数据量不一定是可控的,在未进行分库分表的情况下,随着时间和业务的发展,库中的表会越来越多,表中的数据量也会越来越大,相应地,数据操作,增删改查的开销也会越来越大;另外,由于无法进行分布式式部署,而一台服务器的资源(CPU、磁盘、内存、IO等)是有限的,最终数据库所能承载的数据量、数据处理能力都将遭遇瓶颈。
何谓垂直切分,即将表按照功能模块、关系密切程度划分出来,部署到不同的库上。
何谓水平切分,当一个表中的数据量过大时,我们可以把该表的数据按照某种规则,例如userID散列进行划分,然后存储到多个结构相同的表,和不同的库。
2> Mycat 数据库分片服务器
重要配置文件说明:
server.xml 设置连mycat的账号信息
schema.xml 配置mycat的真实库表
rule.xml 定义mycat分片规则
思路:数据库主机 192.168.4.55 使用db1库存储数据;
数据库主机 192.168.4.56 使用db2库存储数据;
主机192.168.4.54 运行mycat服务,逻辑库名称为test,连接用户名为admin,密码123456
在主机 192.168.4.254 访问测试配置
实现:54、55都授权访问数据库(db1、db2)用户;
56主机上面安装JDK;
56主机上面安装mycat;
server.xml配置连mycat的账号信息;
schema.xml定义表分片到数据节点dn1和dn2(55,56,主机、库、IP、端口、Password等)
client连接56数据库,登录mycat定义的账户密码,测试写入效果
分片规则:范围约定 基于id 来进行分片的,第一条数据存放db1,第二条数据存放db2
3.分片规则
01:分片枚举
partition-hash-int.txt 配置:
10000=0
10010=1
DEFAULT_NODE=1
配置说明:
columns:标识将要分片的表字段;
algorithm:分片函数。
其中分片函数配置中:
mapFile:标识配置文件名称;
type:默认值为 0,0 表示 Integer,非零表示 String。
所有的节点配置都是从 0 开始,0 代表节点 1。
*defaultNode 默认节点:小于 0 表示不设置默认节点,大于等于 0 表示设置默认节点
* 默认节点的作用:枚举分片时,如果碰到不识别的枚举值,就让它路由到默认节点
* 如果不配置默认节点(defaultNode 值小于 0 表示不配置默认节点),碰到不识别的枚举值就会报错
* like this:can’t find datanode for sharding column:column_name val:ffffffff
###############
02:固定分片 hash 算法
本条规则类似于十进制的求模运算,区别在于是二进制的操作,是取 id 的二进制低 10 位,即 id 二进制 &1111111111。
此算法的优点在于如果按照 10 进制取模运算,在连续插入 1-10 时候 1-10 会被分到 1-10 个分片,增大了插入的事务控制难度,而此算法根据二进制则可能会分到连续的分片,减少插入事务事务控制难度。
columns:标识将要分片的表字段;
algorithm:分片函数;
partitionCount:分片个数列表;
partitionLength:分片范围列表。
分区长度:
默认为最大 2^n=1024 ,即最大支持 1024 分区。
约束:
count,length 两个数组的长度必须是一致的;
1024 = sum((count[i]*length[i])). count 和 length 两个向量的点积恒等于 1024。
本例的分区策略:希望将数据水平分成 3 份,前两份各占 25%,第三份占 50%。(故本例非均匀分区)
// |<———————1024———————————>|
// |<—-256—>|<—-256—>|<———-512————->|
// | partition0 | partition1 | partition2 |
// | 共 2 份,故 count[0]=2 | 共 1 份,故 count[1]=1 |
int[] count = new int[] { 2, 1 };
int[] length = new int[] { 256, 512 };
PartitionUtil pu = new PartitionUtil(count, length);
如果需要平均分配设置:平均分为 4 分片,partitionCount*partitionLength=1024。
###############
03:范围约定
此分片适用于,提前规划好分片字段某个范围属于哪个分片。
配置说明:
columns:标识将要分片的表字段;
algorithm:分片函数;
rang-long 函数中:
mapFile 代表配置文件路径;
defaultNode:超过范围后的默认节点。
所有的节点配置都是从 0 开始,及 0 代表节点 1,此配置非常简单,即预先制定可能的 id 范围到某个分片:
# range start-end ,data node index
# K=1000,M=10000.
0-500M=0
500M-1000M=1
1000M-1500M=2
或
0-10000000=0
10000001-20000000=1
###############
04:取模
此规则为对分片字段求摸运算。
配置说明:
columns:标识将要分片的表字段;
algorithm:分片函数;
此种配置非常明确,即根据 id 进行十进制求模预算,相比固定分片 hash,此种在批量插入时可能存在批量插入单事务插入多数据分片,增大事务一致性难度。
###############
05:按日期(天)分片
此规则为按天分片。
配置说明:
columns :标识将要分片的表字段;
algorithm :分片函数;
dateFormat :日期格式;
sBeginDate :开始日期;
sEndDate:结束日期;
sPartionDay :分区天数,即默认从开始日期算起,分隔 10 天一个分区。
如果配置了 sEndDate 则代表数据达到了这个日期的分片后后循环从开始分片插入。
Assert.assertEquals(true, 0 == partition.calculate(“2014-01-01”));
Assert.assertEquals(true, 0 == partition.calculate(“2014-01-10”));
Assert.assertEquals(true, 1 == partition.calculate(“2014-01-11”));
Assert.assertEquals(true, 12 == partition.calculate(“2014-05-01”));
###############
06:取模范围约束
此种规则是取模运算与范围约束的结合,主要为了后续数据迁移做准备,即可以自主决定取模后数据的节点分布。
partition-pattern.txt
# id partition range start-end ,data node index
###### first host configuration
1-32=0
33-64=1
65-96=2
97-128=3
######## second host configuration
129-160=4
161-192=5
193-224=6
225-256=7
0-0=7
配置说明:
columns :标识将要分片的表字段;
algorithm :分片函数;
patternValue:即求模基数;
defaoultNode:默认节点,如果配置了默认,则不会按照求模运算;
mapFile:配置文件路径。
配置文件中,1-32 即代表 id%256 后分布的范围,如果在 1-32 则在分区 1,其他类推,如果 id 非数据,则会分配在 defaoultNode 默认节点。
String idVal = “0”;
Assert.assertEquals(true, 7 == autoPartition.calculate(idVal));
idVal = “45a”;
Assert.assertEquals(true, 2 == autoPartition.calculate(idVal));
###############
07:截取数字做 hash 求模范围约束
此种规则类似于取模范围约束,此规则支持数据符号字母取模。
partition-pattern.txt
# range start-end ,data node index
# ASCII
# 8-57=0-9 阿拉伯数字
# 64、65-90=@、A-Z
# 97-122=a-z
###### first host configuration
1-4=0
5-8=1
9-12=2
13-16=3
###### second host configuration
17-20=4
21-24=5
25-28=6
29-32=7
0-0=7
配置说明:
columns :标识将要分片的表字段;
algorithm :分片函数;
patternValue:求模基数;
prefixLength:ASCII 截取的位数;
mapFile:配置文件路径。
配置文件中,1-32 即代表 id%256 后分布的范围,如果在 1-32 则在分区 1,其他类推。
此种方式类似方式 6,只不过采取的是将列种获取前 prefixLength 位列所有 ASCII 码的和进行求模。
sum%patternValue ,获取的值,在范围内的分片数,
String idVal=“gf89f9a”;
Assert.assertEquals(true, 0==autoPartition.calculate(idVal));
idVal=“8df99a”;
Assert.assertEquals(true, 4==autoPartition.calculate(idVal));
idVal=“8dhdf99a”;
Assert.assertEquals(true, 3==autoPartition.calculate(idVal));
###############
08:截取数字 hash 解析
此规则是截取字符串中的 int 数值 hash 分片。
配置说明:
columns :标识将要分片的表字段;
algorithm :分片函数;
函数中:
partitionLength:代表字符串;
hash:求模基数;
partitionCount:分区数;
hashSlice :hash 预算位,即根据子字符串中 int 值 hash 运算。0 means str.length(), -1 means str.length()-1。
/**
* “2” -> (0,2)
* “1:2” -> (1,2)
* “1:” -> (1,0)
* “-1:” -> (-1,0)
* “:-1” -> (0,-1)
* “:” -> (0,0)
*/
例子:
String idVal=null;
rule.setPartitionLength("512");
rule.setPartitionCount("2");
rule.init();
rule.setHashSlice("0:2");
// idVal = "0";
// Assert.assertEquals(true, 0 == rule.calculate(idVal));
// idVal = "45a";
// Assert.assertEquals(true, 1 == rule.calculate(idVal));
// last 4
rule = new PartitionByString();
rule.setPartitionLength("512");
rule.setPartitionCount("2");
rule.init();
//last 4 characters
rule.setHashSlice("-4:0");
idVal = "aaaabbb0000";
Assert.assertEquals(true, 0 == rule.calculate(idVal));
idVal = "aaaabbb2359";
Assert.assertEquals(true, 0 == rule.calculate(idVal));
*************************************
39.NoSQL概述 部署Redis服务 、部署LNMP+Redis
1> NoSQL:(Not Only SQL),泛指非关系型的数据库。
Redis:Redis是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
2> 部署Redis服务
版本: redis-4.0.8
查看状态:
utils]# /etc/init.d/redis_6379 status
配置文件:/etc/redis/6379.conf
连接redis:
]# redis-cli
127.0.0.1:6379> ping
PONG //PONG说明服务正常
常用指令操作:
set keyname keyvalue 存储
get keyname 获取
del keyname 删除变量
keys * 打印所有变量
EXISTS keyname 测试是否存在
type keyname 查看类型
move keyname dbname
select 数据库编号0-15 切换库
expire keyname 10 设置有效时间
ttl keyname 查看生存时间
flushall 删除所有变量
save 保存所有变量
shutdown 关闭redis服务
在命令行输入密码连接
]# redis-cli -h 192.168.4.50 -p 6350 -a 123456
192.168.4.50:6350> ping
PONG
由于修改Redis服务运行参数,所以在停止服务的时候也不能用默认的方法停止
]# /etc/init.d/redis_6379 stop //停止失败
]# redis-cli -h 192.168.4.50 -p 6350 -a 123456 shutdown
3> 部署LNMP+Redis
Nginx-1.12.2
Php-fpm-5.4.16
Php-redis-2.2.4
脚本连接:
$redis = new redis();
$redis->connect('192.168.4.50',6350);
$redis->auth("123456");
$redis->set('tel,'13152098678);
echo $redis->get('tel');
?>
*************************************
40.创建Redis集群 管理集群
1> Redis集群:
主库宕机后,对应的从库会自动升级为主库,原主库起来后,成为新主库的从库。
2> 创建集群
]# redis-trib.rb create --replicas 1 \
> 192.168.4.51:6351 192.168.4.52:6352 \
> 192.168.4.53:6353 192.168.4.54:6354 \
> 192.168.4.55:6355 192.168.4.56:6356
主库对应的从库,会自动把数据同步到本机。
查看集群信息:
]# redis-trib.rb check 192.168.4.51:6351
查看数据存储情况:
]# redis-trib.rb info 192.168.4.51:6351
添加master角色主机 (添加 192.168.4.57,在51操作):
]# redis-trib.rb add-node 192.168.4.57:6357 192.168.4.51:6351
重新分片:
]# redis-trib.rb reshard 192.168.4.51:6351
添加slave角色主机 (添加slave 192.168.4.58 51上操作):
]# redis-trib.rb add-node --slave 192.168.4.58:6358 192.168.4.51:6351
自动分配给57
移除slave角色主机 (移除192.168.4.58,51操作)
redis-trib.rb del-node 任意主机 被移除主机ID(slave主机没有haxi槽,可直接移除)
]# redis-trib.rb del-node 192.168.4.51:6351 a28a8ad17defa60a4169262a909a17e46d5ce699
移除master角色主机 (移除 192.168.4.57 51操作)
释放占用的hash槽
]# redis-trib.rb reshard 192.168.4.51:6351
移除master主机
]# redis-trib.rb del-node 192.168.4.51:6351 7ac349e23d72f46967eeb0ef6b022c27396a4388
转载于:https://www.cnblogs.com/luwei0915/p/10596841.html