R语言:RSelenium包爬取动态网页
目前很多网站的数据采用异步加载的方式呈现,以进口商品统计月报为例,当我们点击下一页时,表格中的数据会更新,但是网站的URL不会发生变化。对于这种网站,如果使用rvest包或RCurl包进行爬取,只能抓到第一页的数据。不过不用担心,对付这种情况,可以使用R语言中RSelenium包。
RSelenium包可以通过调用Selenium Server来模拟浏览器环境,它可以模拟浏览器的点击、滚动、滑动以及文字输入等操作,抓取经过浏览器渲染过的页面。但是Selenium是Java程序,因此在使用RSelenium包之前必须为计算机设置Java环境,具体前期准备工作可以参考R语言爬取动态网页:使用RSelenium包和Rwebdriver包的前期准备。
使用RSelenium包控制浏览器主要依靠remoteDriver系列函数:
remoteDriver( remoteServerAddr,
port,
browserName,
path,
version,
platform,
javascript,
nativeEvents,
serverURL,
sessionInfo)
其中,参数remoteServerAddr,表示远程服务器的IP地址,默认值是本机地址,是character型;
参数port,表示远程服务器连接端口,是numeric型;
参数browserName,表示浏览器名称,可以取chrome、firefox、htmlunit、internetexplorer或iphone,是character型;
参数path,表示远程服务器上命令的基本URL路径前缀,默认值是“/ wd / hub”;
参数version,表示浏览器版本,是character型;
参数platform,表示浏览器运行的系统,可以是WINDOWS、XP、VISTA、MAC、LINUX或UNIX,是character型;
参数javascript,表示会话是否支持在当前页面的上下文中执行用户提供的JavaScript,是logical型;
参数nativeEvents,表示会话是否支持本地事件,是logical型;
参数serverURL,表示JSON请求发送到的远程服务器的URL,是character型;
参数sessionInfo,表示会话相关信息,是list型。
通常情况下,只要设置browserName就可以对浏览器进行操作。remoteDriver函数的返回值是一系列函数,其中open用于打开浏览器,navigate用于打开网页:
## 打开浏览器
remDr <- remoteDriver(browserName ="chrome")
remDr$open()
## 打开网页
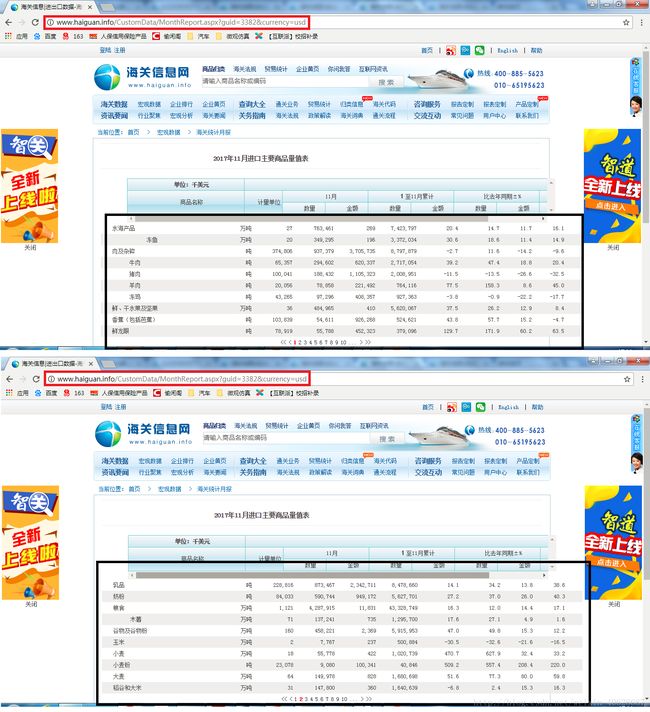
url <-'http://www.haiguan.info/CustomData/MonthReport.aspx?guid=947¤cy=rmb'
remDr$navigate(url)
getPageSource用于抓取经浏览器渲染后的页面,接下来我们可以使用rvest包的相关函数分离出我们需要的数据,其中使用html_table抓到的第4个表格就是我们需要的数据:
# 提取页面
webpage <- read_html(remDr$getPageSource()[[1]][1])
# 提取表格
data_temp <- html_table(webpage, fill = T)[[4]][, 1:10]
data_temp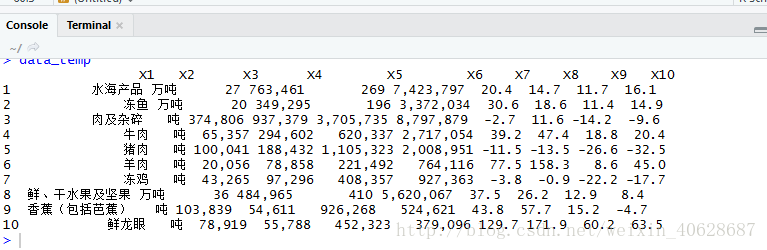
接下来需要抓取下一页的内容,那么怎么使用RSelenium实现翻页操作呢?首先我们要找到“下一页”按钮的位置,然后模拟单击操作。定位“下一页”的位置要用到findElement函数,定位方法有多种,常用的有css和xpath,这里使用xpath方法(xpath的介绍见R语言:使用rvest包抓取新浪财经A股交易数据);模拟单击则用到clickElement函数。
xpath <- '//*[@id="ctl00_MainContent_AspNetPager1"]/a[12]'
nextBtn <- remDr$findElement(using ='xpath',
value = xpath)
nextBtn$clickElement()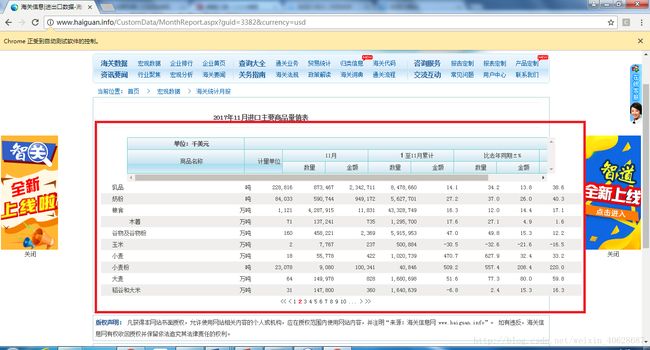
于是,我们可以写一个循环,爬完一页翻一页,翻完一页爬一页,很快就可以把完整的表格爬下来了。代码如下:
library(RSelenium)
library(rvest)
################################
## 打开浏览器
remDr <- remoteDriver(browserName = "chrome")
remDr$open() # 打开
################################
## 打开网页
url <- 'http://www.haiguan.info/CustomData/MonthReport.aspx?guid=3382¤cy=usd'
remDr$navigate(url)
###############################
## 函数
sin_click <- function (xpath) {
t_sleep <- 2
nextBtn <- remDr$findElement(using = 'xpath',
value = xpath)
nextBtn$clickElement()
Sys.sleep(t_sleep)
}
next_xpath <- function (page) {
xpath_m <- '//*[@id="ctl00_MainContent_AspNetPager1"]/a'
value <- '>'
v_1 <- webpage %>% html_nodes(xpath = xpath_m) %>% html_text(trim = T)
n_1 <- which(v_1 == value)
xpath <- paste(xpath_m, '[', n_1, ']')
# 是否继续
n_2 <- max(as.numeric(v_1), na.rm = T)
if (v_1[n_1 - 1] == '...') {
ctn <- T
} else if (page > n_2) {
ctn <- F
} else {
ctn <- T
}
out <- c(xpath, ctn)
return(out)
}
## 新建数据集存放数据
data_all <- t(rep(NA, 10))
data_all <- as.data.frame(data_all, stringsAsFactors = F)
title <- c('商品名称', '计量单位', '当期数量', '当期金额', '累计数量',
'累计金额', '当期数量同比变化', '当期金额同比变化',
'累计数量同比变化', '累计金额同比变化')
colnames(data_all) <- title
data_all <- data_all[!is.na(data_all[, 1]), ]
## 开始抓取
aaa <- 0
page <- 1
while (aaa == 0) {
p_temp <- paste('第', page, '页')
print(p_temp)
# 提取页面
webpage <- read_html(remDr$getPageSource()[[1]][1])
# 提取表格
data_temp <- html_table(webpage, fill = T)[[4]][, 1:10]
colnames(data_temp) <- title
# 合并数据
data_all <- rbind(data_all, data_temp)
# 是否点击下一页
temp <- next_xpath(page)
xpath <- temp[1]
ctn <- temp[2]
if (ctn) {
# 提取下一页按钮的xpath值
# 点击下一页
sin_click(xpath)
page <- page + 1
} else {
aaa <- 1
}
}
view(data_all)
最后得到的数据:
更多RSelenium包的操作请参考R语言爬虫:RSelenium包常用函数。