Attention机制、HAN
一、Attention机制
1.为什么要用Attention
在encoder-decoder架构中,当输入序列比较长时,模型的性能会变差,因为即便是LSTM或GRU也是对文本的信息进行了压缩,尤其是对于机器翻译、摘要生成等任务而言,decoder每个时间步的输出其实是对encoder各时间步的输入有不同的侧重的。因此,引入attention机制,来对encoder各时间步赋以不同的权重,也即给予不同的关注度,这与人在感知图片或文本时的反映是一致的,只会关注到重要的信息。
2.Attention的类别
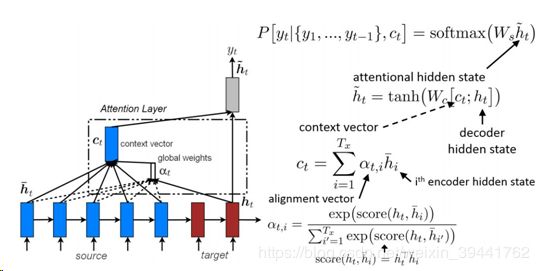
1)全局Attention
所有时间步的隐含状态均参与权重参数的计算
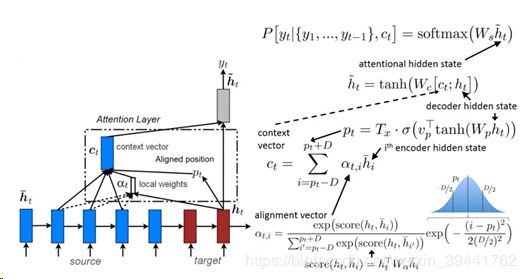
2)局部Attention
不是所有时间步的隐含状态均参与权重参数的计算,先选出最可能的时间步pt,然后加个窗,只有在窗范围内的时间步的隐含状态参与权重参数的计算。由于最可能的时间步pt的计算通常准确性不高,所以性能通常不如全局attention。
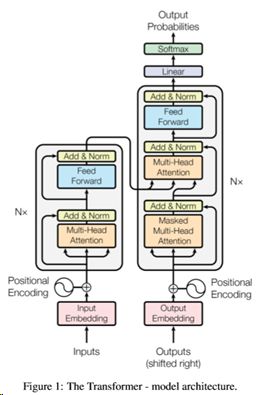
3)自Attention
由Goggle在《Attention Is All You Need》中提出,既捕捉encoder自身word之间的关系,又捕捉decoder自身word之间的关系,还捕捉encoder和decoder之间的关系。
4)层级Attention
类似于接下来要介绍的HAN,先对按照word->sentence->document的层级顺序进行关注。
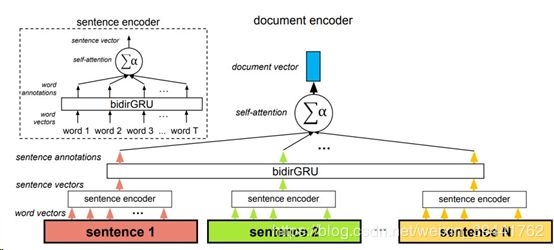
二、HAN
HAN是Hierarchical Attention Networks for Document Classification,采用层级Attention的架构:
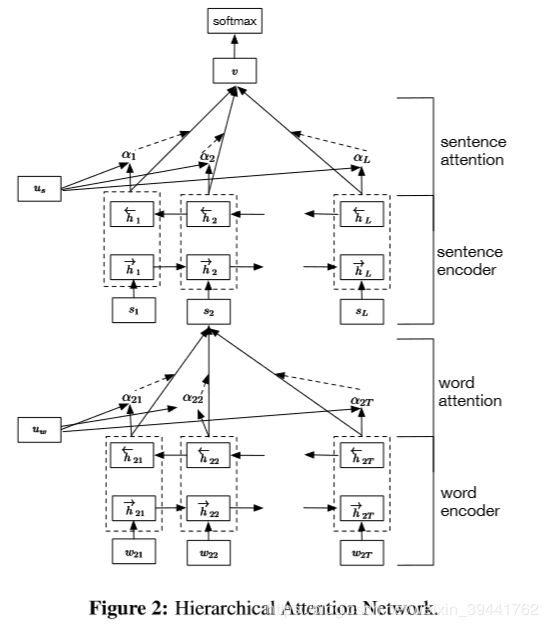
其中Attention层的主要公式就是:
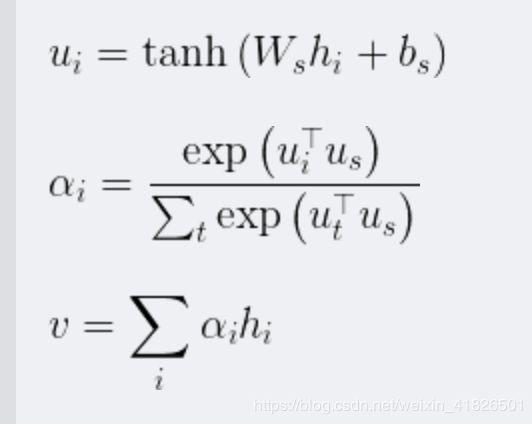
u的计算对应下面代码中的注释【0】
a的计算对应下面代码中的注释【1】【2】【3】(前两步是计算出uu,第三步是计算exp(uu)/sum(exp(uu)) )
v的计算对应下面代码中的注释【4】
最难理解几个点的是:
- 因为这里没有decoder,所以设置了u作为上下文向量,u是随机产生的,可以随网络一同学习,它与输入向量作点积即可刻画各时间步的输入与上下文u的相关性。
- 计算相关性、计算权重时的相加、计算加权后的结果时的相加等各种操作是在哪个维度上进行的,在代码注释中有标明。
- 要注意因为是层级attention,最终是输出文章的类别结果的,所以在输入时就需要给进去多篇文章的数据,也就是需要batch_size(一个batch的文章样本数)* max_sentences_in_document * max_words_in_sentence的词数,label就是batch里每篇文章的类别。
代码来源于https://github.com/KaiyuanGao/text_claasification/blob/master/han_classification/han.py,将自己的理解放在了注释中:
# coding=utf-8
# @author: kaiyuan
# blog: https://blog.csdn.net/Kaiyuan_sjtu
import tensorflow as tf
from tensorflow.contrib import rnn
from tensorflow.contrib import layers
def getSequenceLength(sequences):
"""
:param sequences: 所有的句子长度,[a_size,b_size,c_size,,,]
:return:每个句子进行padding前的实际大小
"""
abs_sequences = tf.abs(sequences)
# after padding data, max is 0
abs_max_seq = tf.reduce_max(abs_sequences, reduction_indices=2)
max_seq_sign = tf.sign(abs_max_seq)
# sum is the real length
real_len = tf.reduce_sum(max_seq_sign, reduction_indices=1)
return tf.cast(real_len, tf.int32)
class HAN(object):
def __init__(self, max_sentence_num, max_sentence_length, num_classes, vocab_size,
embedding_size, learning_rate, decay_steps, decay_rate,
hidden_size, l2_lambda, grad_clip, is_training=False,
initializer=tf.random_normal_initializer(stddev=0.1)):
self.vocab_size = vocab_size
self.max_sentence_num = max_sentence_num
self.max_sentence_length = max_sentence_length
self.num_classes = num_classes
self.embedding_size = embedding_size
self.hidden_size = hidden_size
self.learning_rate = learning_rate
self.decay_rate = decay_rate
self.decay_steps = decay_steps
self.l2_lambda = l2_lambda
self.grad_clip = grad_clip
self.initializer = initializer
self.global_step = tf.Variable(0, trainable=False, name='global_step')
# placeholder
self.input_x = tf.placeholder(tf.int32, [None, max_sentence_num, max_sentence_length], name='input_x') #因为最后要从词到句到文章层级压缩,所以在输入时给进去足够多的词,None篇文章,每篇文章有max_sentence_num个句子,每个句子有max_sentence_length个单词
self.input_y = tf.placeholder(tf.int32, [None, num_classes], name='input_y')
self.dropout_keep_prob = tf.placeholder(tf.float32, name='dropout_keep_prob')
if not is_training:
return
word_embedding = self.word2vec()
sen_vec = self.sen2vec(word_embedding)
doc_vec = self.doc2vec(sen_vec)
self.logits = self.inference(doc_vec)
self.loss_val = self.loss(self.input_y, self.logits)
self.train_op = self.train()
self.prediction = tf.argmax(self.logits, axis=1, name='prediction')
self.pred_min = tf.reduce_min(self.prediction)
self.pred_max = tf.reduce_max(self.prediction)
self.pred_cnt = tf.bincount(tf.cast(self.prediction, dtype=tf.int32))
self.label_cnt = tf.bincount(tf.cast(tf.argmax(self.input_y, axis=1), dtype=tf.int32))
self.accuracy = self.accuracy(self.logits, self.input_y)
def word2vec(self):
with tf.name_scope('embedding'):
self.embedding_mat = tf.Variable(tf.truncated_normal(self.vocab_size, self.embedding_size), name='embedding')
word_embedding = tf.nn.embedding_lookup(self.embedding_mat, self.input_x) # shape: [batch, sen_in_doc, word_in_sent, embedding_size]
return word_embedding
def BidirectionalGRUEncoder(self, inputs, name):
"""
双向GRU编码层,将一句话中的所有单词或者一个文档中的所有句子进行编码得到一个2xhidden_size的输出向量
然后在输入inputs的shape是:
input:[batch, max_time, embedding_size]
output:[batch, max_time, 2*hidden_size]
:return:
"""
with tf.name_scope(name):
fw_gru_cell = rnn.GRUCell(self.hidden_size)
bw_gru_cell = rnn.GRUCell(self.hidden_size)
fw_gru_cell = rnn.DropoutWrapper(fw_gru_cell, output_keep_prob=self.dropout_keep_prob)
bw_gru_cell = rnn.DropoutWrapper(bw_gru_cell, output_keep_prob=self.dropout_keep_prob)
# fw_outputs和bw_outputs的size都是[batch_size, max_time, hidden_size]
(fw_outputs, bw_outputs), (fw_outputs_state, bw_outputs_state) = tf.nn.bidirectional_dynamic_rnn(
cell_fw=fw_gru_cell, cell_bw=bw_gru_cell, inputs=inputs,
sequence_length=getSequenceLength(inputs), dtype=tf.float32
)
# outputs的shape是[batch_size, max_time, hidden_size*2]
outputs = tf.concat((fw_outputs, bw_outputs), 2)
return outputs
def AttentionLayer(self, inputs, name):
"""
inputs是GRU层的输出
inputs: [batch, max_time, 2*hidden_size]
:return:
"""
with tf.name_scope(name):
# context_weight是上下文的重要性向量,用于区分不同单词/句子对于句子/文档的重要程度
context_weight = tf.Variable(tf.truncated_normal([self.hidden_size*2]), name='context_weight')
# 使用单层MLP对GRU的输出进行编码,得到隐藏层表示
# uit =tanh(Wwhit + bw)
fc = layers.fully_connected(inputs, self.hidden_size*2, activation_fn=tf.nn.tanh)#【0】
multiply = tf.multiply(fc, context_weight) #【1】 shape: [batch_size, max_time, 2*hidden_size]
reduce_sum = tf.reduce_sum(multiply, axis=2, keep_dims=True) #【2】 shape: [batch_size, max_time, 1]
alpha = tf.nn.softmax(reduce_sum, dim=1) #【3】shape: [batch_size, max_time, 1],因为softmax是每个概率都还会输出相应的归一化之后的概率,对应第i个句子样本的max_time个单词的权重
atten_output = tf.reduce_sum(tf.multiply(inputs, alpha), axis=1)#【4】shape不是[batch_size, 1, 2*hidden_size],而是[batch_size, hidden_size*2],因为没有keep_dims
return atten_output
def sen2vec(self, word_embeded):
with tf.name_scope('sen2vec'):
"""
GRU的输入tensor是[batch_size, max_time,...],在构造句子向量时max_time应该是每个句子的长度,
所以这里将batch_size*sen_in_doc当做是batch_size,这样一来,每个GRU的cell处理的都是一个单词的词向量
并最终将一句话中的所有单词的词向量融合(Attention)在一起形成句子向量
"""
word_embeded = tf.reshape(word_embeded, [-1, self.max_sentence_length, self.embedding_size])# shape:[batch_size * sen_in_doc, word_in_sent, embedding_size]
word_encoder = self.BidirectionalGRUEncoder(word_embeded, name='word_encoder')# shape: [batch_size * sen_in_doc, word_in_sent, hiddeng_size * 2]
sen_vec = self.AttentionLayer(word_encoder, name='word_attention')# shape: [batch_size * sen_in_doc, hidden_size * 2]
return sen_vec
def doc2vec(self, sen_vec):
with tf.name_scope('doc2vec'):
"""
跟sen2vec类似,不过这里每个cell处理的是一个句子的向量,最后融合成为doc的向量
"""
sen_vec = tf.reshape(sen_vec, [-1, self.max_sentence_num, self.hidden_size*2])# shape:[batch_size, sent_in_doc, hidden_size * 2]
doc_encoder = self.BidirectionalGRUEncoder(sen_vec, name='doc_encoder')# shape: [batch_size,sen_in_doc, hidden_size * 2]
doc_vec = self.AttentionLayer(doc_encoder, name='doc_vec')# shape: [batch_size,hidden_size * 2]
return doc_vec
def inference(self, doc_vec):
with tf.name_scope('logits'):
fc_out = layers.fully_connected(doc_vec, self.num_classes)
return fc_out
def accuracy(self, logits, input_y):
with tf.name_scope('accuracy'):
predict = tf.argmax(logits, axis=1, name='predict')
label = tf.argmax(input_y, axis=1, name='label')
acc = tf.reduce_mean(tf.cast(tf.equal(predict, label), tf.float32))
return acc
def loss(self, input_y, logits):
with tf.name_scope('loss'):
losses = tf.nn.softmax_cross_entropy_with_logits(labels=input_y, logits=logits)
loss = tf.reduce_mean(losses)
if self.l2_lambda >0:
l2_loss = tf.add_n([tf.nn.l2_loss(cand_var) for cand_var in tf.trainable_variables() if 'bia' not in cand_var.name])
loss += self.l2_lambda * l2_loss
return loss
def train(self):
learning_rate = tf.train.exponential_decay(self.learning_rate, self.global_step,
self.decay_steps, self.decay_rate, staircase=True)
# use grad_clip to hand exploding or vanishing gradients
optimizer = tf.train.AdamOptimizer(learning_rate)
grads_and_vars = optimizer.compute_gradients(self.loss_val)
for idx, (grad, var) in enumerate(grads_and_vars):
if grad is not None:
grads_and_vars[idx] = (tf.clip_by_norm(grad, self.grad_clip), var)
train_op = optimizer.apply_gradients(grads_and_vars, global_step=self.global_step)
return train_op