Coursera-Introduction to Data Science in Python-week 3-Assignment 3
自己在边做这个作业的同时偶然发现自己百度了一波居然找不到大家有分享答案和讨论的地方,于是决定自己做好后发出来共享一下,同时大家可以讨论一下。
小弟接触Python一年不到,可能代码看起来很繁琐,不够简洁,即使是最后得到了答案。大家有简洁写法可以评论出来,小弟在这里学习学习。
Question 1 (20%)
Load the energy data from the file Energy Indicators.xls, which is a list of indicators of energy supply and renewable electricity production from the United Nations for the year 2013, and should be put into a DataFrame with the variable name of energy.
Keep in mind that this is an Excel file, and not a comma separated values file. Also, make sure to exclude the footer and header information from the datafile. The first two columns are unneccessary, so you should get rid of them, and you should change the column labels so that the columns are:
['Country', 'Energy Supply', 'Energy Supply per Capita', '% Renewable']
Convert Energy Supply to gigajoules (there are 1,000,000 gigajoules in a petajoule). For all countries which have missing data (e.g. data with "...") make sure this is reflected as np.NaN values.
Rename the following list of countries (for use in later questions):
"Republic of Korea": "South Korea", "United States of America": "United States", "United Kingdom of Great Britain and Northern Ireland": "United Kingdom", "China, Hong Kong Special Administrative Region": "Hong Kong"
There are also several countries with numbers and/or parenthesis in their name. Be sure to remove these,
e.g.
'Bolivia (Plurinational State of)' should be 'Bolivia',
'Switzerland17' should be 'Switzerland'.
Next, load the GDP data from the file world_bank.csv, which is a csv containing countries' GDP from 1960 to 2015 from World Bank. Call this DataFrame GDP.
Make sure to skip the header, and rename the following list of countries:
"Korea, Rep.": "South Korea", "Iran, Islamic Rep.": "Iran", "Hong Kong SAR, China": "Hong Kong"
Finally, load the Sciamgo Journal and Country Rank data for Energy Engineering and Power Technology from the file scimagojr-3.xlsx, which ranks countries based on their journal contributions in the aforementioned area. Call this DataFrame ScimEn.
Join the three datasets: GDP, Energy, and ScimEn into a new dataset (using the intersection of country names). Use only the last 10 years (2006-2015) of GDP data and only the top 15 countries by Scimagojr 'Rank' (Rank 1 through 15).
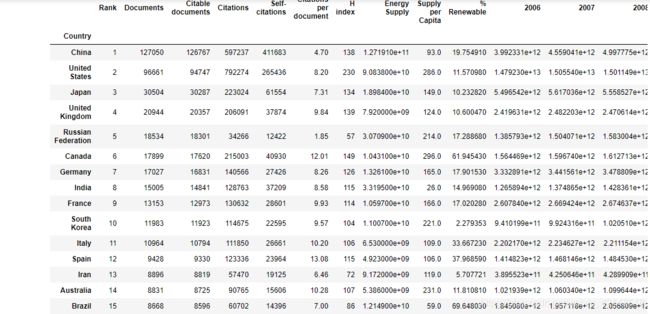
The index of this DataFrame should be the name of the country, and the columns should be ['Rank', 'Documents', 'Citable documents', 'Citations', 'Self-citations', 'Citations per document', 'H index', 'Energy Supply', 'Energy Supply per Capita', '% Renewable', '2006', '2007', '2008', '2009', '2010', '2011', '2012', '2013', '2014', '2015'].
This function should return a DataFrame with 20 columns and 15 entries.
import pandas as pd
import numpy as np
def answer_one():
energy = pd.read_excel('Energy Indicators.xls', skiprows=17,skip_footer= 38) # 读数据,下载下来的表中前面17行和后面38行都没用,读取时跳过
energy = energy[['Unnamed: 1','Petajoules','Gigajoules','%']]
energy.columns = ['Country', 'Energy Supply', 'Energy Supply per Capita', '% Renewable'] # 根据题目要求重命名
energy[['Energy Supply', 'Energy Supply per Capita', '% Renewable']] = energy[['Energy Supply', 'Energy Supply per Capita', '% Renewable']].replace('...',np.NaN).apply(pd.to_numeric) # 根据题目要求将没有数据的值转化为NaN
energy['Energy Supply'] = energy['Energy Supply']*1000000 # 根据题目要求转换单位
energy['Country'] = energy['Country'].replace({'China, Hong Kong Special Administrative Region':'Hong Kong','United Kingdom of Great Britain and Northern Ireland':'United Kingdom','Republic of Korea':'South Korea','United States of America':'United States','Iran (Islamic Republic of)':'Iran'}) # 根据题目要求替换相应国家名字,替换写在字典中,replace函数替换
energy['Country'] = energy['Country'].str.replace(" \(.*\)","") # 根据题目要求替换相应国家名字,去除一些特殊符号
GDP = pd.read_csv('world_bank.csv', skiprows=4)
GDP['Country Name'] = GDP['Country Name'].replace({"Korea, Rep.": "South Korea", "Iran, Islamic Rep.": "Iran", "Hong Kong SAR, China": "Hong Kong"}) # 同样,替换相应国家名字
GDP = GDP[['Country Name','2006','2007','2008','2009','2010','2011','2012','2013','2014','2015']] # 题目说只要10年的,就取出这些年的
ScimEn = pd.read_excel('scimagojr-3.xlsx')
ScimEn = ScimEn[0:15] # 读数据,取出前15个
df = pd.merge(ScimEn, energy, how = 'inner', left_on = 'Country', right_on='Country')
dff = pd.merge(df,GDP, how = 'inner', left_on = 'Country', right_on='Country Name').set_index('Country') # 合并数据,inner方法取交集,最后只有15个国家
dff = dff[['Rank', 'Documents', 'Citable documents', 'Citations', 'Self-citations', 'Citations per document', 'H index', 'Energy Supply', 'Energy Supply per Capita', '% Renewable', '2006', '2007', '2008', '2009', '2010', '2011', '2012', '2013', '2014', '2015']]
return dff
answer_one()答案应该长这样:
Question 2 (6.6%)
The previous question joined three datasets then reduced this to just the top 15 entries. When you joined the datasets, but before you reduced this to the top 15 items, how many entries did you lose?
This function should return a single number.
这个问题应该是说通过取交集之后问被剔除了多少个国家,论坛里也有教授的提示便是outter方法合并三个表格之后的长度减去inner合并的长度
def answer_two():
import pandas as pd
import numpy as np
# 这些都是和Q1一样的在导入数据
energy = pd.read_excel('Energy Indicators.xls', skiprows=17,skip_footer= 38)
energy = energy[['Unnamed: 1','Petajoules','Gigajoules','%']]
energy.columns = ['Country', 'Energy Supply', 'Energy Supply per Capita', '% Renewable']
energy[['Energy Supply', 'Energy Supply per Capita', '% Renewable']] = energy[['Energy Supply', 'Energy Supply per Capita', '% Renewable']].replace('...',np.NaN).apply(pd.to_numeric)
energy['Energy Supply'] = energy['Energy Supply']*1000000
energy['Country'] = energy['Country'].replace({'China, Hong Kong Special Administrative Region':'Hong Kong','United Kingdom of Great Britain and Northern Ireland':'United Kingdom','Republic of Korea':'South Korea','United States of America':'United States','Iran (Islamic Republic of)':'Iran'})
energy['Country'] = energy['Country'].str.replace(" \(.*\)","")
GDP = pd.read_csv('world_bank.csv',skiprows=4)
GDP['Country Name'] = GDP['Country Name'].replace('Korea, Rep.','South Korea')
GDP['Country Name'] = GDP['Country Name'].replace('Iran, Islamic Rep.','Iran')
GDP['Country Name'] = GDP['Country Name'].replace('Hong Kong SAR, China','Hong Kong')
columns = ['Country Name','2006','2007','2008','2009','2010','2011','2012','2013','2014','2015']
GDP = GDP[columns]
GDP.columns = ['Country','2006','2007','2008','2009','2010','2011','2012','2013','2014','2015']
ScimEn = pd.read_excel('scimagojr-3.xlsx')
ScimEn_m = ScimEn[:15]
df = pd.merge(ScimEn, energy, how = 'inner', left_on = 'Country', right_on='Country')
final_df = pd.merge(df,GDP, how = 'inner', left_on = 'Country', right_on='Country')
final_df = final_df.set_index('Country')
columns = ['Rank', 'Documents', 'Citable documents', 'Citations', 'Self-citations', 'Citations per document', 'H index', 'Energy Supply', 'Energy Supply per Capita', '% Renewable', '2006', '2007', '2008', '2009', '2010', '2011', '2012', '2013', '2014', '2015']
ans = final_df[columns]
# 这里是使用otter方法合并数据
df2 = pd.merge(ScimEn, energy, how = 'outer', left_on = 'Country', right_on='Country')
final_df2 = pd.merge(df2,GDP, how = 'outer', left_on = 'Country', right_on='Country')
# print(len(final_df2) - len(final_df))
# 用outter合并的长度减去inner合并的长度,答案是156
return len(final_df2) - len(final_df)
answer_two()Question 3 (6.6%)
What is the average GDP over the last 10 years for each country? (exclude missing values from this calculation.)
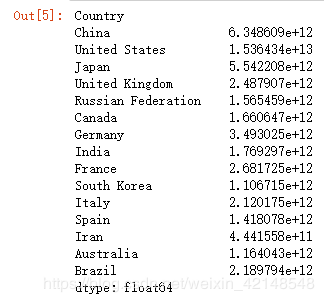
This function should return a Series named avgGDP with 15 countries and their average GDP sorted in descending order.
计算每个国家过去10年的平均GDP,很简单,取出过去十年的GDP数据,用mean函数直接计算得到,注意mean函数中axis默认0时计算的每列的平均值,axis=1则计算每一行。
def answer_three():
Top15 = answer_one()
gdp = Top15[['2006','2007','2008','2009','2010','2011','2012','2013','2014','2015']]
avgGDP = gdp.mean(axis=1)
return avgGDP
answer_three()这是答案:
Question 4 (6.6%)
By how much had the GDP changed over the 10 year span for the country with the 6th largest average GDP?
This function should return a single number.
排名第六的平均GDP国家10年GDP变化多少,将上一问答案排序,拿出第6个计算即可
def answer_four():
Top15 = answer_one()
avg = answer_three().sort_values(ascending=False) # False指降序排列
country = avg.index[5]
value = Top15.loc[country]['2015'] - Top15.loc[country]['2006']
return value
answer_four()答案:246702696075.3999
Question 5 (6.6%)
What is the mean Energy Supply per Capita?
This function should return a single number.
算平均值
def answer_five():
Top15 = answer_one()
supply = Top15['Energy Supply per Capita'].mean()
return supply
answer_five()答案:157.59999999999999
Question 6 (6.6%)
What country has the maximum % Renewable and what is the percentage?
This function should return a tuple with the name of the country and the percentage.
找最大
def answer_six():
Top15 = answer_one()
renew = Top15['% Renewable']
ans = renew.idxmax() # 找最大的id
return (ans, renew[ans])
answer_six()答案:('Brazil', 69.648030000000006)
Question 7 (6.6%)
Create a new column that is the ratio of Self-Citations to Total Citations. What is the maximum value for this new column, and what country has the highest ratio?
This function should return a tuple with the name of the country and the ratio.
找比例最大,用Self-citations除以Citations就行
def answer_seven():
Top15 = answer_one()
se = Top15['Self-citations'] / Top15['Citations']
ans = se.idxmax()
return (ans, se.loc[ans])
answer_seven()答案:('China', 0.68931261793894216)
Question 8 (6.6%)
Create a column that estimates the population using Energy Supply and Energy Supply per capita. What is the third most populous country according to this estimate?
This function should return a single string value.
预测人口,用能耗除人均能耗即可预测出
def answer_eight():
Top15 = answer_one()
se = Top15['Energy Supply'] / Top15['Energy Supply per Capita']
ans = se.sort_values(ascending = False).index[2]
return ans
answer_eight()答案:'United States'
Question 9 (6.6%)
Create a column that estimates the number of citable documents per person. What is the correlation between the number of citable documents per capita and the energy supply per capita? Use the .corr() method, (Pearson's correlation).
This function should return a single number.
这应该是找两个数据之间的相关性,照着公式敲即可:
def answer_nine():
Top15 = answer_one()
se = Top15['Citable documents'] / (Top15['Energy Supply'] / Top15['Energy Supply per Capita'])
ans = se.corr(Top15['Energy Supply per Capita'])
return ans
answer_nine()答案:0.79400104354429446
Question 10 (6.6%)
Create a new column with a 1 if the country's % Renewable value is at or above the median for all countries in the top 15, and a 0 if the country's % Renewable value is below the median.
This function should return a series named HighRenew whose index is the country name sorted in ascending order of rank.
中位数以上或者相等赋值1,以下的赋值0
def answer_ten():
import numpy as np
Top15 = answer_one()
renew = Top15['% Renewable']
mid = renew.median() # 计算中位数
HighRenew = renew
for i in range(len(HighRenew)):
if HighRenew[i] >= mid:
HighRenew[i] = 1
else:
HighRenew[i] = 0
return HighRenew.astype(np.int64) # 不知道为什么输出出来是float而且是错的,我就又转了一下格式
answer_ten()Question 11 (6.6%)
Use the following dictionary to group the Countries by Continent, then create a dateframe that displays the sample size (the number of countries in each continent bin), and the sum, mean, and std deviation for the estimated population of each country.
ContinentDict = {'China':'Asia',
'United States':'North America',
'Japan':'Asia',
'United Kingdom':'Europe',
'Russian Federation':'Europe',
'Canada':'North America',
'Germany':'Europe',
'India':'Asia',
'France':'Europe',
'South Korea':'Asia',
'Italy':'Europe',
'Spain':'Europe',
'Iran':'Asia',
'Australia':'Australia',
'Brazil':'South America'}
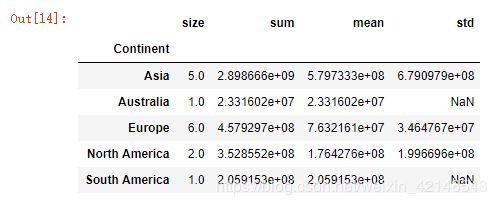
This function should return a DataFrame with index named Continent ['Asia', 'Australia', 'Europe', 'North America', 'South America'] and columns ['size', 'sum', 'mean', 'std']
def answer_eleven():
import pandas as pd
import numpy as np
ContinentDict = {'China':'Asia',
'United States':'North America',
'Japan':'Asia',
'United Kingdom':'Europe',
'Russian Federation':'Europe',
'Canada':'North America',
'Germany':'Europe',
'India':'Asia',
'France':'Europe',
'South Korea':'Asia',
'Italy':'Europe',
'Spain':'Europe',
'Iran':'Asia',
'Australia':'Australia',
'Brazil':'South America'}
Top15 = answer_one()
Top15['PopEst'] = (Top15['Energy Supply'] / Top15['Energy Supply per Capita'])
Top15 = Top15.reset_index()
Top15['Continent'] = Top15['Country']
for country in Top15['Country']:
Top15['Continent'] = Top15['Continent'].replace(ContinentDict)
target = Top15.set_index('Continent').groupby(level = 0)['PopEst'].agg({'size':np.size, 'sum':np.sum, 'mean':np.mean, 'std':np.std})
ans = target[['size', 'sum', 'mean', 'std' ]]
return target
answer_eleven()答案应该是这样:
Question 12 (6.6%)
Cut % Renewable into 5 bins. Group Top15 by the Continent, as well as these new % Renewable bins. How many countries are in each of these groups?
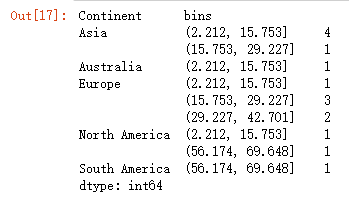
This function should return a Series with a MultiIndex of Continent, then the bins for % Renewable. Do not include groups with no countries.
def answer_twelve():
Top15 = answer_one()
ContinentDict = {'China':'Asia',
'United States':'North America',
'Japan':'Asia',
'United Kingdom':'Europe',
'Russian Federation':'Europe',
'Canada':'North America',
'Germany':'Europe',
'India':'Asia',
'France':'Europe',
'South Korea':'Asia',
'Italy':'Europe',
'Spain':'Europe',
'Iran':'Asia',
'Australia':'Australia',
'Brazil':'South America'}
Top15 = Top15.reset_index()
Top15['Continent'] = [ContinentDict[country] for country in Top15['Country']]
Top15['bins'] = pd.cut(Top15['% Renewable'],5)
ans = Top15.groupby(['Continent', 'bins']).size()
# print(Top15['bins'])
return pd.Series(ans)
answer_twelve()答案:
Question 13 (6.6%)
Convert the Population Estimate series to a string with thousands separator (using commas). Do not round the results.
e.g. 317615384.61538464 -> 317,615,384.61538464
This function should return a Series PopEst whose index is the country name and whose values are the population estimate string.
def answer_thirteen():
Top15 = answer_one()
tmp = []
Top15['PopEst'] = (Top15['Energy Supply'] / Top15['Energy Supply per Capita'])
tmp = Top15['PopEst'].tolist()
Top15['PopEst'] = (Top15['Energy Supply'] / Top15['Energy Supply per Capita']).apply(lambda x: "{:,}".format(x), tmp)
ans = pd.Series(Top15['PopEst'])
return ans
answer_thirteen()答案:
