An Attentive Survey of Attention Models 论文阅读
摘要:注意力模型应用于各个领域,这个研究提供了系统与完整的注意力模型的发展概述,我们提出来现有注意力模型的分类方法,展示了注意力模型在各个领域相结合的方法,提高了注意力模型的可解释性,最终讨论了一些注意力模型的实际应用;
- 介绍
AM模型最早被用于机器翻译领域,并占有一定的影响力,在AI 方面对于神经网络框架存在大量的应用,自然语言处理、统计学习、语音与计算机视觉方面;AM的背后的原理是可以被解释的,来源于人类观察的局部关注性,AM模型能够动态的输入,并注意到相关的部分,比如说文字的情感识别,输入五个句子,相关的居住是第一个与第三个;

AM模型的快速发展与进步来源于三个原因:第一这些模型可以用于多任务,比如机器翻译、问答系统、情感分类、语义标签、解析与对话系统等;第二其不仅提供了性能,并且具有可解释性;第三、其克服了循环神经网络的在输入长度的增加性能退化问题与数据处理的低效率问题,因此我们在此提供了一个简短、高效的注意力模型的研究
文章布局:
| Section2 |
AM模型的提出 |
| Section3 |
讨论注意力模型的分类 |
| Section4、5 |
关键的神经网络的框架与可解释性 |
| Section6 |
模型的应用与总结 |
相关研究概述:
Computer Vision Feng Wang and David MJ Tax. Survey on the attention based rnn
model and its applications in computer vision. arXiv preprint arXiv:1601.06823, 2016.
Graphs: John Boaz Lee, Ryan A Rossi, Sungchul Kim, Nesreen K Ahmed,and Eunyee Koh. Attention models in graphs: A survey. arXiv preprint arXiv:1807.07984, 2018
Galassi : Andrea Galassi, Marco Lippi, and Paolo Torroni. Attention, please!
a critical review of neural attention models in natural language
processing. arXiv preprint arXiv:1902.02181, 2019
- 注意力模型

如图2所示,传统的编解码器a,存在两个问题,编码器不得不压缩所有的输入信息,使用单个向量,使用单个向量可能会导致信息的损失,第二输入输出序列不能够校准,其是翻译与概述方面重要的任务;使用注意力机制引入了,变量a,这个关键性的步骤,引入了权重系数,代表对输出下一个节点的相关系数;权重系数的确定依赖于之前hi and s j-1,更近一步,这个前馈神经网络通过编码-解码形成;
- 分类方法

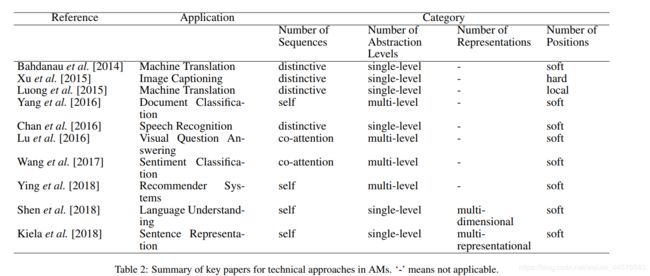
3.1 序列数
此列表,我们只考虑涉及到单个输入与其相对应的输出序列,输入输出是不同的序列,多数用于机器翻译、概述、图像获取、语音识别等的方面,差异性的注意类型;
共同的注意力模型:同时有多个输入,在输入中获取信息产品权重系数,Lu2016 使用共同的注意力模型用于视觉问答注意力方面,因为所有的文字询问并非同等重要,对于问题的回答来说,AM模型旨在帮助对问题的侧重点,反之亦然,在视觉方面也同样使用;
在文本分类与推荐方面、输入都是一个序列,输出不是,在这些情况下,AM模型被用于学习相关系数,换句话说,询问与候选状态是相同的序列,自注意机制,被认为内在注意力;
3.2 抽象水平数
对于单独的输入做权重系统的提取与使用被称为单水平的抽象,然而有些任务是多重抽象的,需要多层权重的学习,比如说文档的分类任务,需要对文字、句子两方面进行,权重学习。
这个文章是在三个层次上的抽象,是共同注意力与多层次注意力的结合使用,存在自上而下,自下而上的两种形式;
3.3 位置 数
根据输入序列的位置来计算权重函数的,在14年被引入,被称为soft attention,正如这个名字一样,其是通过使用所有输入序列的隐藏层的均值来建立相应的向量。其作用使的神经网络有效进行后反馈,但是也承担了二次计算的成本;xu15年,提出了 hard attention 模型,其向量的计算是源于输入序列的随机的隐藏层,使用注意力系数完成了多重分布参数的确定,这种注意力模型有益于减少计算损耗,但是标记输入的每个位置,这种框架是不可微的并且很难优化,多种学习方法已经优化方法在强化学习中被提出、
Luong15 提出了局部与全局的两种优化方法,在机器翻译的任务中,全局注意力模型类似于soft attention,另一方面说,这种定位注意力模型介于soft and hard attention 模型之间,关键点在于 对于输入序列先探测注意点位置,在位置的地方 使用窗口创建局部soft attention,位置可以是人为设置也可以被预测函数对齐,相应的,局部注意力提供一个在软硬注意力模型 的一个计算量与可微性平衡选择。
3.4 表征数
单个语义表征被用于多个方面,然后在一些领域,使用单个表征不能满足对下游任务,在此讨论获取多个方面的表征数据,提高相关性的研究,被称为多表征的注意力模型,多维表征最后结合在一起的特点,广泛用于机器翻译中,因为其出现一词多义的情况
- 注意力模型框架的分析
4.1 编解码框架
早期的编解码网络基于RNN,并被广泛使用,其原因是任何形式的特征被输入,简化形成一个语义向量被用下下一步的解码工作,有研究人员使用混合编解码网络,其编码使用CNN,解码使用RNN或者 LSTM网络,这种类型被广泛用于多模型任务,图像视频获取,视觉问答系统、语音识别方面
然后并非所有的问题,都可以用一个公示来解决,Pointer networks 是另外一种神经网络有以下两点不同:(1)输出是离散的,(2)输出类别取决于输入长度, 这些特征 传统编解码网络不能完成。其作者使用注意力系数来选择可能性选择每个位置。其方法被广泛应用于离散优化问题。
4.2 存储网络
其需要学习数据库中信息,来接近询问的问题。端到端的网络使用存储块来存储信息,使用注意力模型来提供答案,有计算力方面的优势 使得物体连续,可以后向传播。其被认为AM的范式,并非单考虑序列 而且数据集合;
4.3 无RNN的框架
RNN所带来的计算效率低下问题,未来解决这个问题,提出了变压器结构,把编解码网络由两个子网络组成:
- position wise FFN:输入序列需要模型充分利用多方面信息,然而组件获取的位置信息不能使用,为了解决这个问题,转换器中的编码器阶段使用位置方向的FFN为输入序列的每个标记生成内容嵌入和位置编码。
- multi-head self-attention:为了获取多层信息,使用平行的处理;
其架构能够平行的处理,短的训练时间与高准确定位,然而,位置编码只能较弱地合并位置信息,而且可能不适用于对位置变化更敏感的问题,
此外,还有更直接的方法,15RAFFEL AND ELLIS 使用AM 代替时间维度数据,使用FFN 代替RNN 解决时间序列问题;
- 注意力的可解释性

- 应用
在推荐系统、情感分析、文档分类、自然语言处理、问答系统、概述系统方面的应用;
Conclusion
提供注意力模型的分类方法;分析了注意力模型的原理与在各个神经网络领域中的应用;