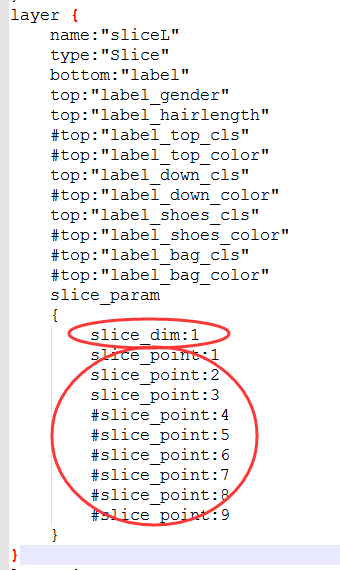
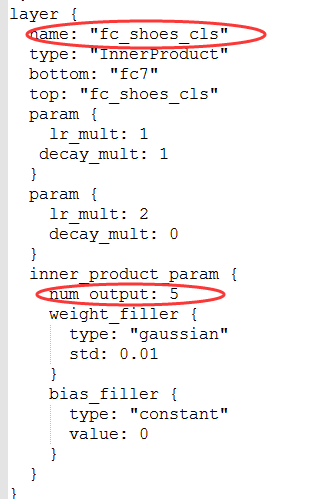
- caffemodel特征可视化_Caffe学习笔记4图像特征进行可视化
weixin_39824801
caffemodel特征可视化
Caffe学习笔记4图像特征进行可视化本文为原创作品,未经本人同意,禁止转载,禁止用于商业用途!本人对博客使用拥有最终解释权欢迎关注我的博客:http://blog.csdn.net/hit2015spring和http://www.cnblogs.com/xujianqing/可以算是对它的翻译的总结吧,它可以算是学习笔记2的一个发展,2是介绍怎么提取特征,这是介绍怎么可视化特征1、准备工作首先
- Caffe学习笔记1-安装以及代码结构
baobei0112
CNN卷积神经网络
Caffe学习笔记1-安装以及代码结构ByYuFeiGan2014-12-09更新日期:2014-12-09安装按照官网教程安装,我在OSX10.9和Ubuntu14.04上面都安装成功了。主要麻烦在于gloggflagsgtest这几个依赖项是google上面的需要。由于我用Mac没有CUDA,所以安装时需要设置CPU_ONLY:=1。如果不是干净的系统,安装还是有点麻烦的比如我在OSX10.9
- caffe学习笔记--写一个运行caffe.cpp的makefile
thystar
caffe学习
之前因为有caffe的项目要放到服务器上面,但是其实不需要在服务器上面重新安装caffe,所以写了个makefile.这里改写了个简单的,比较容易读的,只运行caffe.cpp,如果由其他的,可以按照makefile的规则添加就好。首先,还是要说一下关于caffe的依赖,参考之前的两篇博客:http://blog.csdn.net/thystar/article/details/51179064和
- caffe学习笔记10.1--Fine-tuning a Pretrained Network for Style Recognition(new)
thystar
caffe学习
在之前的文章里,写过一个关于微调的博客,但是今天上去发现这部分已经更新了http://nbviewer.jupyter.org/github/BVLC/caffe/blob/master/examples/02-fine-tuning.ipynb,因此补一篇最新的,关于微调,前面的文章由讲,参考http://blog.csdn.net/thystar/article/details/5067553
- caffe学习笔记(11):多任务学习之HDF5Data类型数据集生成
guyunee
deeplearningmatlabobjectdetection数据标签caffe深度学习
最近开始研究多任务学习(multi-tasklearning,MTL),先分享给大家:本文主要讲述数据集的建立,HDF5Data类型用于处理多标签数据,在网络中定义为:layer{name:"data"type:"HDF5Data"top:"data"top:"label"include{phase:TRAIN}hdf5_data_param{source:"list_train.txt"batc
- Ubuntu14.04下配置Caffe+OpenCV2.4.10+CUDA7.5+cuDNN5.1.10
cuihaolong
3DPrint系统配置
1.CUDA配置与Tensorflow,Keras等深度学习框架一样的配置方法,一次配置可以重用,其他基础软件和依赖项亦可参考:Caffe学习笔记2--Ubuntu14.0464bit安装Caffe(GPU版本)Ubuntu14.04+Caffe+Cuda7.5+Opencv3.0安装教程Caffe+Ubuntu14.0464bit+CUDA6.5配置说明Caffe搭建:Ubuntu14.04+C
- Caffe学习笔记(一): 训练和测试自己的数据集
__Sunshine__
笔记Pythoncaffe训练数据集计算机视觉
1数据准备首先在caffe根目录下建立一个文件夹myfile,用于存放数据文件和后面的caffe模型相关文件。然后在myfile文件夹下建立build_lmdb和datatest两个文件夹,其中build_lmdb文件夹用于存放生成的lmdb文件,datatest文件夹存放图片数据。在datatest下主要有2个文件夹和2个.sh文件和2个.txt文件,其中train文件夹中存放待训练的图片,va
- Caffe学习笔记6:过程小结
Zz鱼丸
之前写的学习笔记1用两种方法进行预测,今天发现有点不对。下面进行分析总结:先来看看Classifier的源代码#!/usr/bin/envpython"""ClassifierisanimageclassifierspecializationofNet."""importnumpyasnpimportcaffeclassClassifier(caffe.Net):"""Classifierexte
- Caffe学习笔记11:Ubuntu 16.04 中 caffe 编译出现的错误——fatal error: hdf5.h: 没有那个文件或目录
weixin_41774576
Caffe
step1:cd/usr/lib/x86_64-linux-gnusudoln-slibhdf5_serial.so.8.0.2libhdf5.sosudoln-slibhdf5_serial_hl.so.8.0.2libhdf5_hl.sostep2:changeMakefile.config//打开Makefile.config将下面的INCLUDE_DIRS:=$(PYTHON_INCLUD
- Caffe学习笔记(1)--在spyder中 import caffe
spcq4
caffe学习笔记
在配置好caffe环境之后无法在anaconda的spyder中直接导入caffe的库,需现先将caffe的路径导入进去。操作如下:importsyscaffe_home='/home/kelly/DL/caffe-master/'sys.path.insert(0,caffe_home+'python')importcaffe
- Caffe学习笔记(2)--spyder 下绘制网络结构
spcq4
caffe学习笔记pythoncaffespyder网络结构
直接使用Caffe中的python脚本绘制网络结构的方法请参照链接:http://www.cnblogs.com/denny402/p/5106764.html。因为本人在学习caffe的时候希望在anaconda的环境下区编辑,所以这里介绍如何在spyder中编写python程序来绘制网络结构图。程序如下:#将caffe包含到路径中importsyscaffe_home='/home/kelly
- Caffe学习笔记(2)优化算法的选择
AshBringer555
Caffe
优化算法的选择参考:1、http://blog.csdn.net/u014595019/article/details/52989301caffe中的优化算法有以下六中可选项,他们分别是SGDAdaDeltaAdaGradAdamNesterovRMSProp1、SGDSGD全名stochasticgradientdescent,即随机梯度下降。不过这里的SGD其实跟MBGD(minibatchg
- Caffe学习笔记
jiarenyf
caffe
目录:安装与配置Tutorial学习PyCaffe学习buildtools学习其他安装与配置Ubuntu14.04安装Caffe(仅CPU)Ubuntu14.04安装CudaUbuntu14.04安装Caffe(GPU)Ubuntu14.04CuDNN安装(Caffe+Cuda7.0下)Tutorial学习Caffe学习:Blobs,Layers,andNetsCaffe学习:Forwardand
- Caffe学习笔记(一)
LaLa_2539
导言今天重新编译了OpenPose的Caffe修改版,准备用于网络的训练,在正式训练网络之前,想先通过实例的学习来对网络训练有大致的认识转化数据为LMDB格式CaffeforPython输入的预处理一、为何需要对输入减去均值?https://blog.csdn.net/GoodShot/article/details/80373372https://blog.csdn.net/dcxhun3/ar
- Caffe学习笔记1:linux下建立自己的数据库训练和测试caffe中已有网络
葭宝
caffe
本文是基于薛开宇《学习笔记3:基于自己的数据训练和测试“caffeNet”》基础上,从头到尾把实验跑了一遍~对该文中不清楚的地方做了更正和说明。主要工作如下:1、下载图片建立数据库2、将图片转化为256*256的lmdb格式3、计算图像均值4、定义网络修改部分参数1、下载图片建立数据库在caffe-master/data下新建一个属于自己的数据库命名为babyjia,并在该文件夹下创建train和
- Caffe学习笔记(四)——Windows 下caffe配置相关问题说明
缄默hong
深度学习
本文主要介绍:Win1064位系统下,再次配置caffe,遇到了一些新的问题,现对这些问题及其解决方法进行总结。详细的安装配置过程见以前博客:Caffe学习笔记(一)——Windows下caffe安装与配置1.CUDA的安装问题CUDA的安装过程可以参考CUDA7.5安装及配置(WIN764英伟达G卡VS2012),但参考到第九步即可,第十步及其以后的过程可以不进行配置;2.编译过程中:无法打开输
- Caffe学习笔记(1):简单的数据可视化
Zongxian_Lee
深度学习python学习笔记数据可视化
caffe的底层是c++写的,如果要进行数据可视化,需要借助其它的库或者是接口,如opencv,python或者是matlab,python的环境需要自行配置,因为我使用的都是网管同志已经配置好的深度学习服务器,所以不用管底层的一些配置问题,如果需要自行配置自己的机器,请参照:http://www.cnblogs.com/denny402/p/5088399.html当前目录为caffe的根目录,
- caffe学习笔记12 -- R-CNN detection
thystar
caffe学习
这是caffe文档中NotebookExamples的倒数第二个例子,链接地址http://nbviewer.jupyter.org/github/BVLC/caffe/blob/master/examples/detection.ipynb这个例子用R-CNN做目标检测。R-CNN是一个先进的目标检测模型,它通过微调caffe模型提供分类区域。对于R-CNN系统和模型的详细介绍,参考Richfe
- caffe学习笔记25-过拟合原因及分析
YiLiang_
deeplearningcaffe
1.过拟合原因:1)样本数量太少,抽样方法错误,抽样时没有足够正确考虑业务场景或业务特点,等等导致抽出的样本数据不能有效足够代表业务逻辑或业务场景2)样本里的噪音数据干扰过大,大到模型过分记住了噪音特征,反而忽略了真实的输入输出间的关系3)就是建模时的“逻辑假设”到了模型应用时已经不能成立了,模型没有通用性,选择参数更少的网络4)没有用dropout5)weight_decay:默认0.005,可
- Caffe 学习笔记之CIFFA-10
静风儿
Caffe学习笔记之CIFFA-10背景知识今天小编就亲身实践利用前几天在Ubuntu14.04刚装好的caffe进行CIFFA-10的训练。CIFAR-10数据集包含60000张32x32的彩色图片,一共有十种类别,每种类别有6000张。数据集中有50000张训练集和10000张测试集。这个数据集一共分为了五组训练集和一组测试集,这样子,每组就有10000张随机组成的图片。虽然是随机的,但是在训
- Caffe学习笔记(二)分类任务
yaoyz105
#Caffe深度学习
笔记(二):用Caffe训练好的模型进行分类任务的测试参考:Caffe学习系列(20):用训练好的caffemodel来进行分类用Caffe搭建自己的网络,并用图片进行测试开发caffe的贾大牛团队,利用imagenet图片和caffenet模型训练好了一个caffemodel,该模型可以用来做分类任务。1.准备模型和数据1)caffemodel下载:bvlc_reference_caffenet
- 【caffe学习笔记——cifar10】win10+caffe环境下cifar10运行
文章被改为VIP本文并不知情,且无法修改
caffe入门笔记
本人初学深度学习——caffe框架,想用几个实例来入门,cifar10为其中之一,在参考了博主汽车数据技术前瞻的帖子:http://blog.csdn.net/lance313/article/details/53964874之后,将学习内容进行了总结,总结的内容基本和我参考的帖子差不多,主要目的是加深印象并方便以后查阅。##cifar数据集的介绍##Cifar-10是由Hinton的两个大弟子A
- caffe学习笔记
Gzzgz
caffe
转自http://blog.csdn.net/u011762313/article/details/4730600目录:安装与配置Tutorial学习PyCaffe学习buildtools学习其他安装与配置Ubuntu14.04安装Caffe(仅CPU)Ubuntu14.04安装CudaUbuntu14.04安装Caffe(GPU)Ubuntu14.04CuDNN安装(Caffe+Cuda7.0下
- 【caffe学习笔记之5】Win10系统下Caffe的Python接口设置方法并绘制网络结构图
Shuai__
pythoncaffe
【准备工作】前面几节介绍了win10系统下caffe-master的配置方法以及cifar10数据集的训练方法,并简要介绍了Matlab接口如何配置。想要更为形象的了解caffe框架下诸多网络模型的具体内涵,需要借助python接口的caffe.draw绘制网络图,因此,本节介绍caffe的Python接口配置方法。安装python使用anaconda版本,anaconda里面集成了很多关于pyt
- 【caffe学习笔记之8】Caffe运行Faster-RCNN算法实现目标检测(1)
Shuai__
Matlabcaffe深度学习
【Faster-RCNN算法】FasterR-CNN(其中R对应于“Region(区域)”)是基于深度学习R-CNN系列目标检测最好的方法。使用VOC2007+2012训练集训练,VOC2007测试集测试mAP达到73.2%,目标检测的速度可以达到每秒5帧。技术上将RPN网络和FastR-CNN网络结合到了一起,将RPN获取到的proposal直接连到ROIpooling层,是一个CNN网络实现端
- 【caffe学习笔记之6】caffe-matlab/python训练LeNet模型并应用于mnist数据集(1)
Shuai__
深度学习caffepythonMatlab
【案例介绍】LeNet网络模型是一个用来识别手写数字的最经典的卷积神经网络,是YannLeCun在1998年设计并提出的,是早期卷积神经网络中最有代表性的实验系统之一,其论文是CNN领域第一篇经典之作。本篇博客详细介绍基于Matlab、Python训练lenet手写模型的案例,作为前几次caffe深度学习框架的阶段性总结。【数据准备】数据下载地址:http://yann.lecun.com/exd
- caffe学习笔记6-matlab接口总结
YiLiang_
caffe
第一部分:用matlab接口操作网络,包括网络生成,数据读取及修改,存储caffeemodel,返回layer的类型1.设置网络:model='./models/bvlc_reference_caffenet/deploy.prototxt';weights='./models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel';
- caffe学习笔记(一)
SHERO_M
caffe
ubuntu14.04.1下caffe的安装(cpumode)准备工作,安装各种依赖和OpenCV,代码如下:sudoapt-getinstalllibprotobuf-devlibleveldb-devlibsnappy-devlibopencv-devlibhdf5-serial-devprotobuf-compilersudoapt-getinstall--no-install-recomm
- 【caffe学习笔记之4】利用MATLAB接口运行cifar数据集
Shuai__
MatlabcaffeComputerVision深度学习
【前期准备工作】参考上篇帖子:http://write.blog.csdn.net/postedit/539648741.确保模型训练成功,生成模型文件:cifar10_quick_iter_4000.caffemodel及均值文件:mean.binaryproto。注意,此处一定是生成caffemodel格式的模型文件,而非.h5模型文件,否则会导致Matlab运行崩溃。如何生成caffemod
- caffe学习笔记21-VggNet论文笔记
YiLiang_
caffedeeplearning
AlexNet输入要求256(图像大小),均值是256的,减均值后再crop到227(输入图像大小)VGGNet输入要求256(图像大小),均值是256的,减均值后再crop到224(输入图像大小)Vgg-Net:笔记CNNimprovement:有很多对其提出的CNN结构进行改进的方法。例如:1.Usesmallerreceptivewindowsizeandsmallerstrideofthe
- 关于旗正规则引擎下载页面需要弹窗保存到本地目录的问题
何必如此
jsp超链接文件下载窗口
生成下载页面是需要选择“录入提交页面”,生成之后默认的下载页面<a>标签超链接为:<a href="<%=root_stimage%>stimage/image.jsp?filename=<%=strfile234%>&attachname=<%=java.net.URLEncoder.encode(file234filesourc
- 【Spark九十八】Standalone Cluster Mode下的资源调度源代码分析
bit1129
cluster
在分析源代码之前,首先对Standalone Cluster Mode的资源调度有一个基本的认识:
首先,运行一个Application需要Driver进程和一组Executor进程。在Standalone Cluster Mode下,Driver和Executor都是在Master的监护下给Worker发消息创建(Driver进程和Executor进程都需要分配内存和CPU,这就需要Maste
- linux上独立安装部署spark
daizj
linux安装spark1.4部署
下面讲一下linux上安装spark,以 Standalone Mode 安装
1)首先安装JDK
下载JDK:jdk-7u79-linux-x64.tar.gz ,版本是1.7以上都行,解压 tar -zxvf jdk-7u79-linux-x64.tar.gz
然后配置 ~/.bashrc&nb
- Java 字节码之解析一
周凡杨
java字节码javap
一: Java 字节代码的组织形式
类文件 {
OxCAFEBABE ,小版本号,大版本号,常量池大小,常量池数组,访问控制标记,当前类信息,父类信息,实现的接口个数,实现的接口信息数组,域个数,域信息数组,方法个数,方法信息数组,属性个数,属性信息数组
}
&nbs
- java各种小工具代码
g21121
java
1.数组转换成List
import java.util.Arrays;
Arrays.asList(Object[] obj); 2.判断一个String型是否有值
import org.springframework.util.StringUtils;
if (StringUtils.hasText(str)) 3.判断一个List是否有值
import org.spring
- 加快FineReport报表设计的几个心得体会
老A不折腾
finereport
一、从远程服务器大批量取数进行表样设计时,最好按“列顺序”取一个“空的SQL语句”,这样可提高设计速度。否则每次设计时模板均要从远程读取数据,速度相当慢!!
二、找一个富文本编辑软件(如NOTEPAD+)编辑SQL语句,这样会很好地检查语法。有时候带参数较多检查语法复杂时,结合FineReport中生成的日志,再找一个第三方数据库访问软件(如PL/SQL)进行数据检索,可以很快定位语法错误。
- mysql linux启动与停止
墙头上一根草
如何启动/停止/重启MySQL一、启动方式1、使用 service 启动:service mysqld start2、使用 mysqld 脚本启动:/etc/inint.d/mysqld start3、使用 safe_mysqld 启动:safe_mysqld&二、停止1、使用 service 启动:service mysqld stop2、使用 mysqld 脚本启动:/etc/inin
- Spring中事务管理浅谈
aijuans
spring事务管理
Spring中事务管理浅谈
By Tony Jiang@2012-1-20 Spring中对事务的声明式管理
拿一个XML举例
[html]
view plain
copy
print
?
<?xml version="1.0" encoding="UTF-8"?>&nb
- php中隐形字符65279(utf-8的BOM头)问题
alxw4616
php中隐形字符65279(utf-8的BOM头)问题
今天遇到一个问题. php输出JSON 前端在解析时发生问题:parsererror.
调试:
1.仔细对比字符串发现字符串拼写正确.怀疑是 非打印字符的问题.
2.逐一将字符串还原为unicode编码. 发现在字符串头的位置出现了一个 65279的非打印字符.
- 调用对象是否需要传递对象(初学者一定要注意这个问题)
百合不是茶
对象的传递与调用技巧
类和对象的简单的复习,在做项目的过程中有时候不知道怎样来调用类创建的对象,简单的几个类可以看清楚,一般在项目中创建十几个类往往就不知道怎么来看
为了以后能够看清楚,现在来回顾一下类和对象的创建,对象的调用和传递(前面写过一篇)
类和对象的基础概念:
JAVA中万事万物都是类 类有字段(属性),方法,嵌套类和嵌套接
- JDK1.5 AtomicLong实例
bijian1013
javathreadjava多线程AtomicLong
JDK1.5 AtomicLong实例
类 AtomicLong
可以用原子方式更新的 long 值。有关原子变量属性的描述,请参阅 java.util.concurrent.atomic 包规范。AtomicLong 可用在应用程序中(如以原子方式增加的序列号),并且不能用于替换 Long。但是,此类确实扩展了 Number,允许那些处理基于数字类的工具和实用工具进行统一访问。
- 自定义的RPC的Java实现
bijian1013
javarpc
网上看到纯java实现的RPC,很不错。
RPC的全名Remote Process Call,即远程过程调用。使用RPC,可以像使用本地的程序一样使用远程服务器上的程序。下面是一个简单的RPC 调用实例,从中可以看到RPC如何
- 【RPC框架Hessian一】Hessian RPC Hello World
bit1129
Hello world
什么是Hessian
The Hessian binary web service protocol makes web services usable without requiring a large framework, and without learning yet another alphabet soup of protocols. Because it is a binary p
- 【Spark九十五】Spark Shell操作Spark SQL
bit1129
shell
在Spark Shell上,通过创建HiveContext可以直接进行Hive操作
1. 操作Hive中已存在的表
[hadoop@hadoop bin]$ ./spark-shell
Spark assembly has been built with Hive, including Datanucleus jars on classpath
Welcom
- F5 往header加入客户端的ip
ronin47
when HTTP_RESPONSE {if {[HTTP::is_redirect]}{ HTTP::header replace Location [string map {:port/ /} [HTTP::header value Location]]HTTP::header replace Lo
- java-61-在数组中,数字减去它右边(注意是右边)的数字得到一个数对之差. 求所有数对之差的最大值。例如在数组{2, 4, 1, 16, 7, 5,
bylijinnan
java
思路来自:
http://zhedahht.blog.163.com/blog/static/2541117420116135376632/
写了个java版的
public class GreatestLeftRightDiff {
/**
* Q61.在数组中,数字减去它右边(注意是右边)的数字得到一个数对之差。
* 求所有数对之差的最大值。例如在数组
- mongoDB 索引
开窍的石头
mongoDB索引
在这一节中我们讲讲在mongo中如何创建索引
得到当前查询的索引信息
db.user.find(_id:12).explain();
cursor: basicCoursor 指的是没有索引
&
- [硬件和系统]迎峰度夏
comsci
系统
从这几天的气温来看,今年夏天的高温天气可能会维持在一个比较长的时间内
所以,从现在开始准备渡过炎热的夏天。。。。
每间房屋要有一个落地电风扇,一个空调(空调的功率和房间的面积有密切的关系)
坐的,躺的地方要有凉垫,床上要有凉席
电脑的机箱
- 基于ThinkPHP开发的公司官网
cuiyadll
行业系统
后端基于ThinkPHP,前端基于jQuery和BootstrapCo.MZ 企业系统
轻量级企业网站管理系统
运行环境:PHP5.3+, MySQL5.0
系统预览
系统下载:http://www.tecmz.com
预览地址:http://co.tecmz.com
各种设备自适应
响应式的网站设计能够对用户产生友好度,并且对于
- Transaction and redelivery in JMS (JMS的事务和失败消息重发机制)
darrenzhu
jms事务承认MQacknowledge
JMS Message Delivery Reliability and Acknowledgement Patterns
http://wso2.com/library/articles/2013/01/jms-message-delivery-reliability-acknowledgement-patterns/
Transaction and redelivery in
- Centos添加硬盘完全教程
dcj3sjt126com
linuxcentoshardware
Linux的硬盘识别:
sda 表示第1块SCSI硬盘
hda 表示第1块IDE硬盘
scd0 表示第1个USB光驱
一般使用“fdisk -l”命
- yii2 restful web服务路由
dcj3sjt126com
PHPyii2
路由
随着资源和控制器类准备,您可以使用URL如 http://localhost/index.php?r=user/create访问资源,类似于你可以用正常的Web应用程序做法。
在实践中,你通常要用美观的URL并采取有优势的HTTP动词。 例如,请求POST /users意味着访问user/create动作。 这可以很容易地通过配置urlManager应用程序组件来完成 如下所示
- MongoDB查询(4)——游标和分页[八]
eksliang
mongodbMongoDB游标MongoDB深分页
转载请出自出处:http://eksliang.iteye.com/blog/2177567 一、游标
数据库使用游标返回find的执行结果。客户端对游标的实现通常能够对最终结果进行有效控制,从shell中定义一个游标非常简单,就是将查询结果分配给一个变量(用var声明的变量就是局部变量),便创建了一个游标,如下所示:
> var
- Activity的四种启动模式和onNewIntent()
gundumw100
android
Android中Activity启动模式详解
在Android中每个界面都是一个Activity,切换界面操作其实是多个不同Activity之间的实例化操作。在Android中Activity的启动模式决定了Activity的启动运行方式。
Android总Activity的启动模式分为四种:
Activity启动模式设置:
<acti
- 攻城狮送女友的CSS3生日蛋糕
ini
htmlWebhtml5csscss3
在线预览:http://keleyi.com/keleyi/phtml/html5/29.htm
代码如下:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>攻城狮送女友的CSS3生日蛋糕-柯乐义<
- 读源码学Servlet(1)GenericServlet 源码分析
jzinfo
tomcatWebservlet网络应用网络协议
Servlet API的核心就是javax.servlet.Servlet接口,所有的Servlet 类(抽象的或者自己写的)都必须实现这个接口。在Servlet接口中定义了5个方法,其中有3个方法是由Servlet 容器在Servlet的生命周期的不同阶段来调用的特定方法。
先看javax.servlet.servlet接口源码:
package
- JAVA进阶:VO(DTO)与PO(DAO)之间的转换
snoopy7713
javaVOHibernatepo
PO即 Persistence Object VO即 Value Object
VO和PO的主要区别在于: VO是独立的Java Object。 PO是由Hibernate纳入其实体容器(Entity Map)的对象,它代表了与数据库中某条记录对应的Hibernate实体,PO的变化在事务提交时将反应到实际数据库中。
实际上,这个VO被用作Data Transfer
- mongodb group by date 聚合查询日期 统计每天数据(信息量)
qiaolevip
每天进步一点点学习永无止境mongodb纵观千象
/* 1 */
{
"_id" : ObjectId("557ac1e2153c43c320393d9d"),
"msgType" : "text",
"sendTime" : ISODate("2015-06-12T11:26:26.000Z")
- java之18天 常用的类(一)
Luob.
MathDateSystemRuntimeRundom
System类
import java.util.Properties;
/**
* System:
* out:标准输出,默认是控制台
* in:标准输入,默认是键盘
*
* 描述系统的一些信息
* 获取系统的属性信息:Properties getProperties();
*
*
*
*/
public class Sy
- maven
wuai
maven
1、安装maven:解压缩、添加M2_HOME、添加环境变量path
2、创建maven_home文件夹,创建项目mvn_ch01,在其下面建立src、pom.xml,在src下面简历main、test、main下面建立java文件夹
3、编写类,在java文件夹下面依照类的包逐层创建文件夹,将此类放入最后一级文件夹
4、进入mvn_ch01
4.1、mvn compile ,执行后会在