图像均值滤波的CUDA并行化优化
1、算法原理
均值滤波也是线性滤波,目标点的像素为周围(模板覆盖)像素的平均值。对图像进行均值滤波处理时,每一个像素点的处理与其它像素点无关,所以,可以把对于每一个像素的处理映射到每个线程中,从而实现并行化。
2、并行思路
将像素映射到二维坐标空间,然后使用i*WIDTH+j的方式索引像素,本实例是寻找周围9个像素点的值。对于每一个线程都将去寻找它的领域像素,然后对其求平均值。为了简化计算,边界采用复制像素的方式处理。代码中采用的block Size为256*1。
3、CPU实现代码
对于C++读取图片的方式代码如下,这里不再细讲,需要深究的可以取网上查阅相关博客。
readImage.h
#pragma once
typedef unsigned char BYTE;
typedef unsigned short WORD;
typedef unsigned int DWORD;
typedef long LONG;
//位图文件头定义;
//其中不包含文件类型信息(由于结构体的内存结构决定,
//要是加了的话将不能正确读取文件信息)
typedef struct tagBITMAPFILEHEADER {
//WORD bfType;//文件类型,必须是0x424D,即字符“BM”
DWORD bfSize;//文件大小
WORD bfReserved1;//保留字
WORD bfReserved2;//保留字
DWORD bfOffBits;//从文件头到实际位图数据的偏移字节数
}BITMAPFILEHEADER;
typedef struct tagBITMAPINFOHEADER {
DWORD biSize;//信息头大小
LONG biWidth;//图像宽度
LONG biHeight;//图像高度
WORD biPlanes;//位平面数,必须为1
WORD biBitCount;//每像素位数
DWORD biCompression; //压缩类型
DWORD biSizeImage; //压缩图像大小字节数
LONG biXPelsPerMeter; //水平分辨率
LONG biYPelsPerMeter; //垂直分辨率
DWORD biClrUsed; //位图实际用到的色彩数
DWORD biClrImportant; //本位图中重要的色彩数
}BITMAPINFOHEADER; //位图信息头定义
typedef struct tagRGBQUAD {
BYTE rgbBlue; //该颜色的蓝色分量
BYTE rgbGreen; //该颜色的绿色分量
BYTE rgbRed; //该颜色的红色分量
BYTE rgbReserved; //保留值
}RGBQUAD;//调色板定义
//像素信息
typedef struct tagIMAGEDATA
{
BYTE blue;
}IMAGEDATA;
unsigned char* readImageData(const char* path, int& width00, int& height11);
void saveImageData(const char* path, int width, int height, unsigned char* imagedata);
void showBmpHead();
void showBmpInforHead();#include
#include "readImage.h"
#include "stdlib.h"
#include "math.h"
#include
#define PI 3.14159//圆周率宏定义
#define LENGTH_NAME_BMP 30//bmp图片文件名的最大长度
using namespace std;
//变量定义
BITMAPFILEHEADER strHead;
RGBQUAD strPla[256];//256色调色板
BITMAPINFOHEADER strInfo;
//显示位图文件头信息
void showBmpHead() {
cout << "位图文件头:" << endl;
cout << "文件大小:" << strHead.bfSize << endl;
cout << "保留字_1:" << strHead.bfReserved1 << endl;
cout << "保留字_2:" << strHead.bfReserved2 << endl;
cout << "实际位图数据的偏移字节数:" << strHead.bfOffBits << endl << endl;
}
void showBmpInforHead() {
cout << "位图信息头:" << endl;
cout << "结构体的长度:" << strInfo.biSize << endl;
cout << "位图宽:" << strInfo.biWidth << endl;
cout << "位图高:" << strInfo.biHeight << endl;
cout << "biPlanes平面数:" << strInfo.biPlanes << endl;
cout << "biBitCount采用颜色位数:" << strInfo.biBitCount << endl;
cout << "压缩方式:" << strInfo.biCompression << endl;
cout << "biSizeImage实际位图数据占用的字节数:" << strInfo.biSizeImage << endl;
cout << "X方向分辨率:" << strInfo.biXPelsPerMeter << endl;
cout << "Y方向分辨率:" << strInfo.biYPelsPerMeter << endl;
cout << "使用的颜色数:" << strInfo.biClrUsed << endl;
cout << "重要颜色数:" << strInfo.biClrImportant << endl;
}
unsigned char* readImageData(const char* path, int& width, int& height) {
unsigned char* imagedata = NULL;//动态分配存储原图片的像素信息的二维数组
FILE *fpi;
fpi = fopen(path, "rb");
if (!fpi) {
cout << "file open error!" << endl;
return NULL;
}
else
{
//先读取文件类型
WORD bfType;
fread(&bfType, 1, sizeof(WORD), fpi);
if (0x4d42 != bfType)
{
cout << "the file is not a bmp file!" << endl;
return NULL;
}
//读取bmp文件的文件头和信息头
fread(&strHead, sizeof(tagBITMAPFILEHEADER), 1, fpi);
fread(&strInfo, sizeof(tagBITMAPINFOHEADER), 1, fpi);
//showBmpInforHead(strInfo);//显示文件信息头
//读取调色板
for (unsigned int nCounti = 0; nCounti CPU 实现均值滤波代码:
kernel.cu
extern "C" void cpuSmoothImage(unsigned char* srcData, unsigned char* dstData, int width, int height) {
//复制源图像数据
memcpy(dstData, srcData, width*height * sizeof(unsigned char));
cudaEvent_t d_begin, d_end;
cudaEventCreate(&d_begin);
cudaEventCreate(&d_end);
cudaEventRecord(d_begin, 0);
for (int i = 1; i < height - 1; i++) {
for (int j = 1; j < width - 1; j++) {
float temp = 0;
temp += srcData[i*width + j - 1];
temp += srcData[i*width + j];
temp += srcData[i*width + j + 1];
temp += srcData[(i + 1)*width + j - 1];
temp += srcData[(i + 1)*width + j];
temp += srcData[(i + 1)*width + j + 1];
temp += srcData[(i - 1)*width + j - 1];
temp += srcData[(i - 1)*width + j];
temp += srcData[(i - 1)*width + j + 1];
temp = temp / 9;
dstData[i*width + j] = temp;
}
}
cudaEventRecord(d_end);
cudaEventSynchronize(d_end);
float cpuTime = 0.0;
cudaEventElapsedTime(&cpuTime, d_begin, d_end);
printf(">>>CPU Time is : %f ms\n", cpuTime);
}4、GPU全局内存实现
kernel.cu
__global__ void kernelGPU(int width, int height, unsigned char* srcData, unsigned char* dstData)
{
int i = threadIdx.x + blockDim.x * blockIdx.x;
int j = blockIdx.y;
int pos = j*width + i;
//边缘保留
if (i > 0 && (i < width - 1) && j > 0 && (j < height - 1)) {
float temp = 0;
temp += srcData[pos];
temp += srcData[pos+1];
temp += srcData[pos-1];
temp += srcData[pos - width - 1];
temp += srcData[pos - width];
temp += srcData[pos - width + 1];
temp += srcData[pos + width - 1];
temp += srcData[pos + width];
temp += srcData[pos + width + 1];
temp = temp / 9;
dstData[pos] = temp;
}
else {
dstData[pos] = srcData[pos];
}
}
extern "C" void gpuSmoothImage(int width, int height, unsigned char* srcData, unsigned char* dstData) {
size_t size = width * height * sizeof(unsigned char);
cudaEvent_t d_begin, d_end;
cudaEventCreate(&d_begin);
cudaEventCreate(&d_end);
cudaEventRecord(d_begin, 0);
unsigned char* d_srcData=NULL;
cudaMalloc((void**)&d_srcData, size);
cudaMemcpy(d_srcData, srcData, size, cudaMemcpyHostToDevice);
unsigned char* d_dstData = NULL;
cudaMalloc((void**)&d_dstData, size);
//dim3 blockSize(16,16);
//dim3 gridSize((width + blockSize.x - 1) / blockSize.x, (height + blockSize.y - 1) / blockSize.y);
dim3 blockSize(256,1);
dim3 gridSize((width + blockSize.x - 1) / blockSize.x,height);
kernelGPU << > > (width, height, d_srcData, d_dstData);
cudaMemcpy(dstData, d_dstData, size, cudaMemcpyDeviceToHost);
cudaEventRecord(d_end);
cudaEventSynchronize(d_end);
float gpuTime = 0.0;
cudaEventElapsedTime(&gpuTime, d_begin, d_end);
printf(">>>GPU Time is : %f ms\n", gpuTime);
cudaFree(d_srcData);
cudaFree(d_dstData);
}
调用方式 main.cpp
#include
#include
#include
#include
#include "readImage.h"
extern "C" void gpuSmoothImage(int width, int height, unsigned char* srcData, unsigned char* dstData);
extern "C" void cpuSmoothImage(unsigned char* srcData, unsigned char* dstData, int width, int height);
extern "C" void gpuSmoothImageTexture(int width, int height, unsigned char* srcData, unsigned char* dstData);
int main() {
const char* path = "lena.bmp";
int Width, Height;
unsigned char* readData = readImageData(path, Width, Height);
printf("w:%d h:%d\n", Width, Height);
//showBmpHead();
//showBmpInforHead();
//CPU smooth Image
clock_t t1, t2;
unsigned char* moothData = NULL;
moothData = (unsigned char*)malloc(Width*Height * sizeof(unsigned char));
cpuSmoothImage(readData, moothData, Width, Height);
const char * savePath = "saveCPU.bmp";
saveImageData(savePath, Width, Height, moothData);
/*
for (int i = 0; i < 100; i++) {
for (int j = 0; j < 10; j++) {
printf("%5d", moothData[i*Width + j]);
}
printf("\n");
}*/
//GPU smooth Image
unsigned char* result = NULL;
result = (unsigned char*)malloc(Width*Height * sizeof(unsigned char));
const char * savePath1 = "saveGPU.bmp";
gpuSmoothImage(Width, Height, readData, result);
//gpuSmoothImageTexture(Width, Height, readData, result);
saveImageData(savePath1, Width, Height, result);
/*printf("GPUdata:\n");
for (int i = 0; i < 100; i++) {
for (int j = 0; j < 10; j++) {
printf("%5d", result[i*Width + j]);
}
printf("\n");
}
*/
return 0;
} 
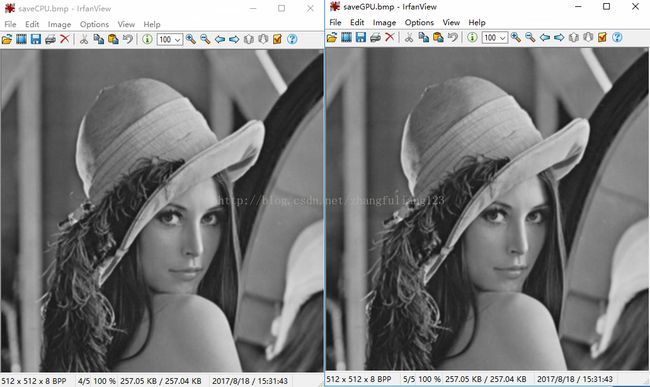
可以看到GPU和CPU的平滑结果完全一样,我们再看下并行加速的效果,图片在1024的时候加速了14.67倍,效果还是很好的。

5、纹理内存
因为我们是按照行存储的方式读取数据,所以使用一维纹理内存。对于纹理内存主要是三个步骤:纹理参考声明,纹理数据绑定,纹理拾取。
可以参考本人以前博客:http://blog.csdn.net/zhangfuliang123/article/details/76571498
代码如下:
texture texRef;
__global__ void kernelGPUTexture(int width, int height, unsigned char* dstData)
{
int i = threadIdx.x + blockDim.x * blockIdx.x;
int j = blockIdx.y;
int pos = j*width + i;
//边缘保留
if (i > 0 && (i < width - 1) && j > 0 && (j < height - 1)) {
float temp = 0;
temp += tex1Dfetch(texRef, pos);
temp += tex1Dfetch(texRef, pos + 1);
temp += tex1Dfetch(texRef, pos - 1);
temp += tex1Dfetch(texRef, pos - width - 1);
temp += tex1Dfetch(texRef, pos - width);
temp += tex1Dfetch(texRef, pos - width + 1);
temp += tex1Dfetch(texRef, pos + width - 1);
temp += tex1Dfetch(texRef, pos + width);
temp += tex1Dfetch(texRef, pos + width + 1);
temp = temp / 9;
dstData[pos] = temp;
}
else {
dstData[pos] = tex1Dfetch(texRef, pos);
}
}
extern "C" void gpuSmoothImageTexture(int width, int height, unsigned char* srcData, unsigned char* dstData) {
size_t size = width * height * sizeof(unsigned char);
cudaEvent_t d_begin, d_end;
cudaEventCreate(&d_begin);
cudaEventCreate(&d_end);
cudaEventRecord(d_begin, 0);
unsigned char* d_srcData = NULL;
cudaMalloc((void**)&d_srcData, size);
cudaMemcpy(d_srcData, srcData, size, cudaMemcpyHostToDevice);
unsigned char* d_dstData = NULL;
cudaMalloc((void**)&d_dstData, size);
//bind texture
cudaBindTexture(0, texRef, d_srcData);
//dim3 blockSize(16, 16);
//dim3 gridSize((width + blockSize.x - 1) / blockSize.x, (height + blockSize.y - 1) / blockSize.y);
dim3 blockSize(256,1);
dim3 gridSize((width + blockSize.x - 1) / blockSize.x,height);
kernelGPUTexture << > > (width, height, d_dstData);
cudaMemcpy(dstData, d_dstData, size, cudaMemcpyDeviceToHost);
cudaEventRecord(d_end);
cudaEventSynchronize(d_end);
float gpuTime = 0.0;
cudaEventElapsedTime(&gpuTime, d_begin, d_end);
printf(">>>GPU Time is : %f ms\n", gpuTime);
cudaFree(d_srcData);
cudaFree(d_dstData);
cudaUnbindTexture(&texRef);
}

可以看出,使用纹理内存,加速效果并不是很理想,应该是使用一维纹理内存拾取不能达到很好的效果(不是非常确定)。