使用MINIST数据集
首先,必须向各位强调的是:该数据集名字叫MNIST,而非MINIST~ 我之前就一直弄错了! 哈哈~
网上有很多使用MNIST数据集的教程,要么太麻烦,要么需要下载,很慢。 在这里分享一下我找到的最方便的方法
1 下载数据集并解压。
法1 从这个百度云链接下载
没有网络限制会比较快: 链接: https://pan.baidu.com/s/1ydcCsPBlP6U9Hw52TMnhkw 提取码: 8zjp
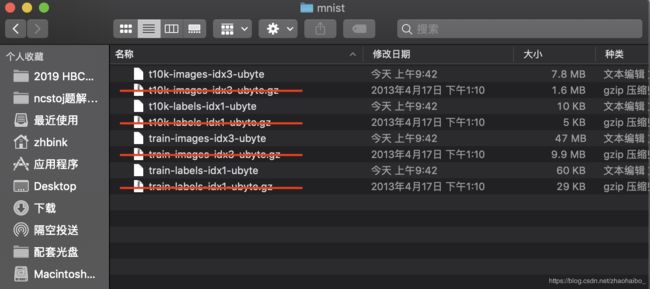
法2 (需要) 从MNIST官网中下载下图四个文件,下载速度很慢!
下载的是4个.gz格式的压缩包
解压后得到四个新文件
之前的4个.gz压缩包就可以删除了
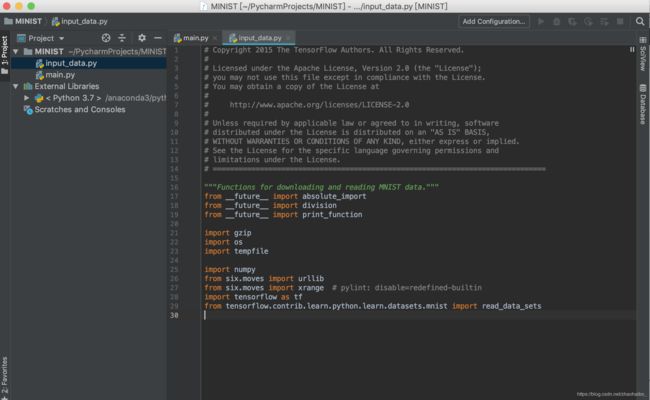
2 新建一个.py文件,起名为 input_data.py
将下面的代码复制粘贴进input_data.py中
# Copyright 2015 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""Functions for downloading and reading MNIST data."""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import gzip
import os
import tempfile
import numpy
from six.moves import urllib
from six.moves import xrange # pylint: disable=redefined-builtin
import tensorflow as tf
from tensorflow.contrib.learn.python.learn.datasets.mnist import read_data_sets
3 建立你的python项目,将input_data.py放在你的项目中
4 在你的python文件中(我的就是main.py,需要和input_data.py在头一个目录下)使用input_data
import tensorflow as tf
import input_data
# 下载并载入MNIST手写数据库
# 下面这句话的功能是使用input_data.py的内容自动下载数据集,如果数据集已经存在,则不用下载直接调用
mnist = input_data.read_data_sets("MNIST_data", one_hot=True)
现在就可以运行程序了。但是不出意外的话你运行很久也不会有结果,因为网络限制等问题,要下载很长时间,请终止程序,进行步骤5。
5 打开你的项目文件目录,新建一个文件夹 MINIST_data (如果你之前运行过一遍的话,这个文件夹会存在,但是里面没有东西)
把第一步下载并解压的文件复制粘贴到MINIST_data这个文件夹中
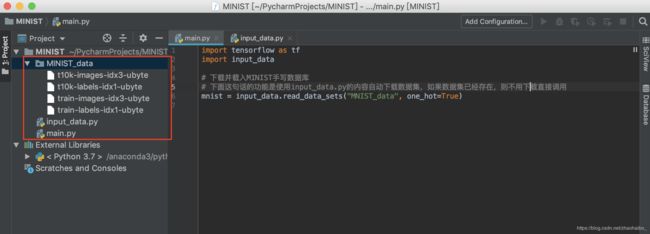
现在就可以正常地通过这两句代码得到minist数据集了,因为不用下载,每次直接调用即可,所以很方便。
import input_data
mnist = input_data.read_data_sets("MNIST_data", one_hot=True)
最后附一个CNN的例子可供大家测试
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
import input_data
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
# 下载并载入MNIST手写数据库
mnist = input_data.read_data_sets("MNIST_data", one_hot=True)
# None表示张量的第一个维度可以是任意长度
input_x = tf.placeholder(tf.float32, [None, 28*28])/255 # 灰度值:0~255
output_y = tf.placeholder(tf.int32, [None, 10]) # 输出:10个数字的标签
input_x_images = tf.reshape(input_x, [-1, 28, 28, 1]) # 改变形状之后的输入
# 从测试数据集中选取3000个手写数字的图片和对应标签
test_x = mnist.test.images[:3000] # 图片
test_y = mnist.test.labels[:3000] # 标签
# 构建卷积神经网络
# 第 1 层卷积
conv1 = tf.layers.conv2d(inputs=input_x_images, # 形状是[28, 28, 1]
filters=32, # 32个过滤器,输出的深度是32
kernel_size=[5, 5], # 过滤器在二维的大小是(5,5)
strides=1, # 步长是1
padding='same', # same表示输出的大小不变,因此需要在外围补0两圈
activation=tf.nn.relu # 激活函数是Relu
) # 形状[28, 28, 32]
# 第 1 层池化(亚采样)
pool1 = tf.layers.max_pooling2d(
inputs=conv1, # 形状[28, 28, 32]
pool_size=[2,2], # 过滤器在二维的大小是(2 * 2)
strides=2 # 步长是2
) # 形状[14, 14, 32]
# 第 2 层卷积
conv2 = tf.layers.conv2d(inputs=pool1, # 形状是[14, 14, 32]
filters=64, # 64个过滤器,输出的深度是64
kernel_size=[5, 5], # 过滤器在二维的大小是(5,5)
strides=1, # 步长是1
padding='same', # same表示输出的大小不变,因此需要在外围补0两圈
activation=tf.nn.relu # 激活函数是Relu
) # 形状[14, 14, 64]
# 第 2 层池化(亚采样)
pool2 = tf.layers.max_pooling2d(
inputs=conv2, # 形状[14, 14, 64]
pool_size=[2,2], # 过滤器在二维的大小是(2 * 2)
strides=2 # 步长是2
) # 形状[7, 7, 64]
# 平坦化(flat)
flat = tf.reshape(pool2, [-1, 7 * 7 * 64]) # 形状[7 * 7 * 64, ]
# 1024个神经元的全链接层
dense = tf.layers.dense(inputs=flat, units=1024, activation=tf.nn.relu)
# Dropout:丢弃50%,rate=0.5
dropout = tf.layers.dropout(inputs=dense, rate=0.5)
# 10个神经元的券链接层,这里不用激活函数来做非线性话了
logits = tf.layers.dense(inputs=dropout, units=10) # 输出。形状[1, 1, 10]
# 计算误差(计算Cross entropy(交叉熵),再用Softmax计算百分比概率)
loss = tf.losses.softmax_cross_entropy(onehot_labels=output_y, logits=logits)
# Adam 优化器来最小化误差,学习率0。001
train_op = tf.train.AdamOptimizer(learning_rate=0.001).minimize(loss)
# 精度。计算 预测值 和 实际标签的匹配程度
# 返回(accuracy, update_op),会创建两个局部变量
accuracy = tf.metrics.accuracy(
labels=tf.argmax(output_y, axis=1),
predictions=tf.argmax(logits, axis=1),)[1]
with tf.Session() as sess:
# 初始化全局和局部变量
init = tf.group(tf.global_variables_initializer(), tf.local_variables_initializer())
sess.run(init)
for i in range(20000):
batch = mnist.train.next_batch(50) # 从训练集中取下一个50个样本
train_loss, train_op_ = sess.run([loss, train_op], {input_x: batch[0], output_y: batch[1]})
if i % 100 == 0:
test_accuracy = sess.run(accuracy, {input_x: test_x, output_y: test_y})
print("Step=%d, Train loss=%.4f, [Test accuracy=%.2f]" % (i, train_loss, test_accuracy))
test_output = sess.run(logits, {input_x: test_x[:20]})
inferenced_y = np.argmax(test_output, 1)
print(inferenced_y, 'Inferenced numbers') # 推测的数字
print(np.argmax(test_y[:20], 1), 'Real numbers') # 真实的数字