- Python之七彩花朵代码实现
PlutoZuo
Pythonpython开发语言
Python之七彩花朵代码实现文章目录Python之七彩花朵代码实现下面是一个简单的使用Python的七彩花朵。这个示例只是一个简单的版本,没有很多高级功能,但它可以作为一个起点,你可以在此基础上添加更多功能。importturtleastuimportrandomasraimportmathtu.setup(1.0,1.0)t=tu.Pen()t.ht()colors=['red','skybl
- Shader面试题100道之(81-100)
还是大剑师兰特
#Shader综合教程100+大剑师shader面试题shader教程
Shader面试题(第81-100题)以下是第81到第100道Shader相关的面试题及答案:81.Unity中如何实现屏幕空间的热扭曲效果(HeatDistortion)?热扭曲效果可以通过GrabPass抓取当前屏幕图像,然后在片段着色器中使用噪声或动态UV偏移模拟空气扰动,再结合一个透明通道控制扭曲强度来实现。82.Shader中如何实现物体轮廓高亮(OutlineHighlight)?轮廓
- Java特性之设计模式【责任链模式】
Naijia_OvO
Java特性java设计模式责任链模式
一、责任链模式概述顾名思义,责任链模式(ChainofResponsibilityPattern)为请求创建了一个接收者对象的链。这种模式给予请求的类型,对请求的发送者和接收者进行解耦。这种类型的设计模式属于行为型模式在这种模式中,通常每个接收者都包含对另一个接收者的引用。如果一个对象不能处理该请求,那么它会把相同的请求传给下一个接收者,依此类推主要解决:职责链上的处理者负责处理请求,客户只需要将
- Kafka系列之:Dead Letter Queue死信队列DLQ
快乐骑行^_^
KafkaKafka系列DeadLetterQueue死信队列DLQ
Kafka系列之:DeadLetterQueue死信队列DLQ一、死信队列二、参数errors.tolerance三、创建死信队列主题四、在启用安全性的情况下使用死信队列更多内容请阅读博主这篇博客:Kafka系列之:KafkaConnect深入探讨-错误处理和死信队列一、死信队列死信队列(DLQ)仅适用于接收器连接器。当一条记录以JSON格式到达接收器连接器时,但接收器连接器配置期望另一种格式,如
- Maya自定义右键菜单样例教程
holy-pills
本文还有配套的精品资源,点击获取简介:本文详细指导如何在Maya中通过脚本节点自定义右键菜单,增强工作效率和个性化工作环境。自定义右键菜单允许用户根据个人习惯调整菜单项,使之更加便捷。文章介绍了创建脚本节点、编写菜单脚本、关联菜单到视图以及保存和加载自定义菜单的具体步骤。同时提供了实际操作样例,帮助用户更好地理解和应用这一技巧。1.Maya自定义右键菜单的重要性Maya,作为三维动画制作的行业标准
- 【AI大模型学习路线】第三阶段之RAG与LangChain——第十六章(Advanced RAG[1])基于历史对话重新生成Query?
985小水博一枚呀
AI大模型学习路线人工智能学习langchainRAG
【AI大模型学习路线】第三阶段之RAG与LangChain——第十六章(AdvancedRAG[1])基于历史对话重新生成Query?【AI大模型学习路线】第三阶段之RAG与LangChain——第十六章(AdvancedRAG[1])基于历史对话重新生成Query?文章目录【AI大模型学习路线】第三阶段之RAG与LangChain——第十六章(AdvancedRAG[1])基于历史对话重新生成Q
- 【AI大模型学习路线】第三阶段之RAG与LangChain——第十六章(Advanced RAG[1])其他Query优化相关策略?
985小水博一枚呀
AI大模型学习路线人工智能学习langchain
【AI大模型学习路线】第三阶段之RAG与LangChain——第十六章(AdvancedRAG[1])其他Query优化相关策略?【AI大模型学习路线】第三阶段之RAG与LangChain——第十六章(AdvancedRAG[1])其他Query优化相关策略?文章目录【AI大模型学习路线】第三阶段之RAG与LangChain——第十六章(AdvancedRAG[1])其他Query优化相关策略?一
- AI 图像编辑提示词参考之:背景替换
在AI图像编辑中(以FluxKontext为例),“替换背景”(BackgroundReplacement)是提升图像表现力的关键手段之一。但背景更换不仅仅是简单的视觉置换,更重要的是:确保人物主体外观不变,并与新背景在色温、色调、光影等方面自然融合。只有这样,最终图像才会呈现出“原本拍摄于该背景环境”的真实感。建议使用以下结构组织提示词:Replacethebackgroundwith[新背景]
- redis集群之Sentinel哨兵高可用
会飞的爱迪生
redisredissentinelbootstrap
Sentinel是官网推荐的高可用(HA)解决方案,可以实现redis的高可用,即主挂了从代替主工作,在一台单独的服务器上运行多个sentinel,去监控其他服务器上的redismaster-slave状态(可以监控多个master-slave),当发现master宕机后sentinel会在slave中选举并启动新的master。至少需要3台redis才能建立起基于哨兵的reids集群。一、通过s
- .NET中的安全性之数字签名、数字证书、强签名程序集、反编译
hezudao25
NET.netassembly加密算法referenceheader
本文将探讨数字签名、数字证书、强签名程序集、反编译等以及它们在.NET中的运用(一些概念并不局限于.NET在其它技术、平台中也存在)。1.数字签名数字签名又称为公钥数字签名,或者电子签章等,它借助公钥加密技术实现。数字签名技术主要涉及公钥、私钥、非对称加密算法。1.1公钥与私钥公钥是公开的钥匙,私钥则是与公钥匹配的严格保护的私有密钥;私钥加密的信息只有公钥可以解开,反之亦然。在VisualStud
- AI Agent开发学习系列 - langchain之Chains的使用(7):用四种处理文档的预制链轻松实现文档对话
alex100
AIAgent学习人工智能langchainprompt语言模型python
在LangChain中,四种文档处理预制链(stuff、refine、mapreduce、mapre-rank)是实现文档问答、摘要等任务的常用高阶工具。它们的核心作用是:将长文档切分为块,分步处理,再整合结果,极大提升大模型处理长文档的能力。stuff直接拼接所有文档内容到prompt,一次性交给大模型处理。适合文档较短、token不超限的场景。refine递进式摘要。先对第一块文档生成初步答案
- Java Web 之 Session 详解
艾伦~耶格尔
java开发语言后端前端session
在JavaWeb开发中,Session就像网站的专属记忆管家,为每个用户保管着重要的信息和状态,确保用户在网站的旅程顺畅无阻。场景一:想象你去一家大型超市购物,推着购物车挑选商品。这个购物车就如同Session,它记录了你的购物信息,方便你在结账时一次性结算。场景二:你在玩一个在线游戏,登录账号后,你的游戏进度、等级、装备等信息都会被保存在Session中,即使你中途关闭游戏,下次登录时依然可以继
- Ajax之核心语法详解
AA-代码批发V哥
Ajax/Axiosajax
Ajax之核心语法详解一、Ajax的核心原理与优势1.1什么是Ajax?1.2Ajax的优势二、XMLHttpRequest:Ajax的核心对象2.1XHR的基本使用流程2.2核心属性与事件解析2.2.1`readyState`:请求状态2.2.2`status`:HTTP状态码2.2.3响应数据属性2.2.4常用事件三、HTTP请求方法与数据传递3.1GET请求:获取数据3.2POST请求:提交
- JavaScript之DOM操作与事件处理详解
AA-代码批发V哥
JavaScriptjavascript
JavaScript之DOM操作与事件处理详解一、DOM基础:理解文档对象模型二、DOM元素的获取与访问2.1基础获取方法2.2集合的区别与注意事项三、DOM元素的创建与修改3.1创建与插入元素3.2修改元素属性与样式3.2.1属性操作3.2.2样式操作3.3元素内容的修改四、DOM元素的删除与替换4.1删除元素4.2替换元素五、事件处理:实现页面交互5.1事件绑定的三种方式5.1.1HTML属性
- V少JS基础班之第五弹
V少在逆向
JS基础班javascript开发语言ecmascript
文章目录一、前言二、本节涉及知识点三、重点内容1-函数的定义2-函数的构成1.函数参数详解1)参数个数不固定2)默认参数3)arguments对象(类数组)4)剩余参数(Rest参数)5)函数参数是按值传递的6)解构参数传递7)参数校验技巧(JavaScript没有类型限制,需要手动校验)2.函数返回值详解3-函数的分类1-函数声明式:2-函数表达式:3-箭头函数:4-构造函数:5-IIFE:6-
- Javaweb学习之Vue模板语法(三)
不要数手指啦
vue.js学习前端
目录学习资料前情回顾本期介绍(vue模板语法)文本插值Vue的Attribute绑定使用JavaScript表达式综合实例代码:学习资料Vue.js-渐进式JavaScript框架|Vue.js(vuejs.org)前情回顾项目的创建大家可以看这篇文章Vue学习之项目的创建-CSDN博客本期介绍(vue模板语法)首先,找到我们编写代码的地方找到自己项目的src文件夹,打开之后点击component
- Vue框架之模板语法全面解析
AA-代码批发V哥
Vuevue.js
Vue框架之模板语法全面解析一、模板语法的核心思想二、插值表达式:数据渲染的基础2.1基本用法:渲染文本2.2纯HTML渲染:`v-html`指令2.3一次性插值:`v-once`指令三、指令系统:控制DOM的行为3.1条件渲染:`v-if`与`v-show`3.1.1`v-if`:动态创建/销毁元素3.1.2`v-else`与`v-else-if`:条件分支3.1.3`v-show`:动态显示/
- 【Android】安卓四大组件之广播接收器(Broadcast Receiver):从基础到进阶
m0_59734531
AndroidandroidjavaBoradcast安卓四大组件
在Android开发中,广播接收器(BroadcastReceiver)是一个非常重要的组件,它能帮助应用接收来自系统或其他应用的事件通知,实现跨组件、跨应用的通信。大家可以把广播接收器想象成一个“收音机”。它的作用是监听系统或应用发出的“广播消息”,并在收到消息后执行相应的操作。(一)基础概念BroadcastReceiver用于监听系统或应用发出的广播事件,实现跨组件通信。其特点是发送方无需关
- 项目开发日记
框架整理学习UIMgr:一、数据结构与算法1.1关键数据结构成员变量类型说明m_CtrlsList当前正在显示的所有UI页面m_CachesList已打开过、但现在不显示的页面(缓存池)1.2算法逻辑查找缓存页面:从m_Caches中倒序查找是否已有对应ePageType页面,找到则重用。页面加载:从资源管理器ResMgr加载prefab并绑定控制器/视图组件。页面关闭:从m_Ctrls移除,添加
- AI MCP教程之 什么是 MCP?利用本地 LLM 、MCP、DeepSeek 集成构建您自己的 AI 驱动工具
知识大胖
NVIDIAGPU和大语言模型开发教程人工智能mcpdeepseek
介绍利用模型上下文协议(MCP)的工具吸引了我们的注意力—将AI变成触手可及的生产力引擎。它们巧妙、高效,让人难以抗拒。但如果您可以将这样的功能添加到自己的工具中,会怎么样呢?在本指南中,我将引导您构建一个具有本地运行的大型语言模型(LLM)和MCP集成的AI工具-让您以类似的方式自动执行利用MCP的工具您喜欢的任务。推荐文章《AnythingLLM教程系列之12AnythingLLM上的Olla
- 使用 Deepseek Zero Coding Experience 创建类似飞扬的小鸟游戏
知识大胖
NVIDIAGPU和大语言模型开发教程游戏deepseekollamajanuspro
简介Flappybird在苹果商店推出后,每天大约能赚5000美元,但后来被苹果故意下架。现在我正尝试使用Deepseek制作这样一款游戏。技术在不断变化,编码知识也在不断变化,只需修改代码即可获得结果。让我们在Deepseek上试试这款游戏:推荐文章《如何在本地电脑上安装和使用DeepSeekR-1》权重1,DeepSeek《Nvidia系列之使用NVIDIAIsaacSim和ROS2的命令行控
- 24GB GPU 中的 DeepSeek R1:Unsloth AI 针对 671B 参数模型进行动态量化
知识大胖
NVIDIAGPU和大语言模型开发教程人工智能deepseekollama
简介最初的DeepSeekR1是一个拥有6710亿个参数的语言模型,UnslothAI团队对其进行了动态量化,将模型大小减少了80%(从720GB减少到131GB),同时保持了强大的性能。当添加模型卸载功能时,该模型可以在24GBVRAM下以低令牌/秒的推理速度运行。推荐文章《本地构建AI智能分析助手之01快速安装,使用PandasAI和Ollama进行数据分析,用自然语言向你公司的数据提问为决策
- NVIDIA 系列之 使用生成式 AI 增强 ROS2 机器人技术:使用 BLIP 和 Isaac Sim 进行实时图像字幕制作
知识大胖
NVIDIAGPU和大语言模型开发教程人工智能机器人
简介在快速发展的机器人领域,集成先进的AI模型可以显著增强机器人系统的功能。在本博客中,我们将探讨如何在ROS2(机器人操作系统2)环境中利用BLIP(引导语言图像预训练)模型进行实时图像字幕制作,并使用NVIDIAIsaacSim进行模拟。我们将介绍如何实现一个ROS2节点,该节点订阅摄像头源、应用BLIP模型进行图像字幕制作,并实时显示结果。这种集成展示了生成式AI在增强人机交互方面的强大功能
- 卫星分析系列之 使用卫星图像量化野火烧毁面积 在 Google Colab 中使用 Python 使用 Sentinel-2 图像确定森林火灾烧毁面积
知识大胖
NVIDIAGPU和大语言模型开发教程pythonsentinel开发语言
简介几年前,当大多数气候模型预测如果我们不采取必要措施,洪水、热浪和野火将会发生更多时,我没想到这些不寻常的灾难现象会成为常见事件。其中,野火每年摧毁大量森林面积。如果你搜索不同地方的重大野火表格,你会发现令人震惊的统计数据,显示由于野火,地球上有多少森林面积正在消失。在本教程中,我将结合我已经发表过的关于下载、处理卫星图像和可视化野火的故事,量化加州发生的其中一场重大野火的烧毁面积。与之前的帖子
- OpenWebUI系列之 如何通过docker自动将其更新到OpenWebUI最新版本
知识大胖
NVIDIAGPU和大语言模型开发教程dockerllmopenwebui
实战需求OpenWebUI是一个可扩展、功能丰富且用户友好的自托管WebUI,旨在完全离线运行。它支持各种LLM运行器,包括Ollama和OpenAI兼容API。如何通过docker自动将其更新到OpenWebUI最新版本?系列文章《OpenWebUI系列之如何通过docker更新到OpenWebUI的最新版本》权重0,本地类、opewebui类《OpenWebUI系列之如何通过docker自动将
- AnythingLLM教程系列之 12 AnythingLLM 上的 Ollama 与 MySQL+PostgreSQL
知识大胖
NVIDIAGPU和大语言模型开发教程mysqlpostgresql数据库anythingllmollama
简介一款全栈应用程序,可让您将任何文档、资源或内容转换为上下文,任何LLM都可以在聊天期间将其用作参考。此应用程序允许您选择要使用的LLM或矢量数据库,并支持多用户管理和权限。本文将介绍如何在AnythingLLM上将Ollama与MySQL+PostgreSQL连接起来。系列文章如何安装《无需任何代码构建自己的大模型知识库:AnythingLLM最易于使用的一体化AI应用程序,可以执行RAG、A
- AnythingLLM教程系列之 09 AnythingLLM 支持自定义音频转录提供程序
知识大胖
NVIDIAGPU和大语言模型开发教程llama3anythingllmllm
什么是AnythingLLM?AnythingLLM是最易于使用的一体化AI应用程序,可以执行RAG、AI代理等操作,且无需任何代码或基础设施难题。您需要为您的企业或组织提供一款完全可定制、私有且一体化的AI应用程序,该应用程序基本上是一个具有许可的完整ChatGPT,但具有任何LLM、嵌入模型或矢量数据库。如何安装《无需任何代码构建自己的大模型知识库:AnythingLLM最易于使用的一体化AI
- AnythingLLM教程系列之 04 AnythingLLM 允许您以正确的格式导出聊天日志,以构建 GPT-3.5 和 OpenAI 上其他可用模型的微调模型(教程含安装步骤)
知识大胖
NVIDIAGPU和大语言模型开发教程llama3aianythinllmllama
什么是AnythingLLM?AnythingLLM是最易于使用的一体化AI应用程序,可以执行RAG、AI代理等操作,且无需任何代码或基础设施难题。您需要为您的企业或组织提供一款完全可定制、私有且一体化的AI应用程序,该应用程序基本上是一个具有许可的完整ChatGPT,但具有任何LLM、嵌入模型或矢量数据库。如何安装《无需任何代码构建自己的大模型知识库:AnythingLLM最易于使用的一体化AI
- Java实习模拟面试之安徽九德 —— 面向对象编程、Spring框架与数据库技术详解
培风图南以星河揽胜
java面试java面试spring
关键词:Java实习生、模拟面试、安徽九德、SpringBoot、MySQL、Redis、面向对象编程、团队协作一、前言作为一名计算机相关专业的学生,想要顺利进入一家互联网公司或软件开发企业实习,技术面试是必须面对的一道门槛。本文将带你走进一场真实的Java实习生模拟面试场景,以“安徽九德”公司为背景,围绕其发布的招聘岗位要求,进行一次全方位的技术面试演练。本次模拟面试涵盖以下核心知识点:Java
- 【Modern C++ Part8】Prefer-nullptr-to-0-and-NULL
莫彩
C++ModernC++c++开发语言jvm
优先使用nullptr而不是0或者NULL0字面上是一个int类型,而不是指针,这是显而易见的。C++扫描到一个0,但是发现在上下文中仅有一个指针用到了它,编译器将勉强将0解释为空指针,但是这仅仅是一个应变之策。C++最初始的原则是0是int而非指针。经验上讲,同样的情况对NULL也是存在的。对NULL而言,仍有一些细节上的不确定性,因为赋予NULL一个除了int(即long)以外的整数类型是被允
- 关于旗正规则引擎中的MD5加密问题
何必如此
jspMD5规则加密
一般情况下,为了防止个人隐私的泄露,我们都会对用户登录密码进行加密,使数据库相应字段保存的是加密后的字符串,而非原始密码。
在旗正规则引擎中,通过外部调用,可以实现MD5的加密,具体步骤如下:
1.在对象库中选择外部调用,选择“com.flagleader.util.MD5”,在子选项中选择“com.flagleader.util.MD5.getMD5ofStr({arg1})”;
2.在规
- 【Spark101】Scala Promise/Future在Spark中的应用
bit1129
Promise
Promise和Future是Scala用于异步调用并实现结果汇集的并发原语,Scala的Future同JUC里面的Future接口含义相同,Promise理解起来就有些绕。等有时间了再仔细的研究下Promise和Future的语义以及应用场景,具体参见Scala在线文档:http://docs.scala-lang.org/sips/completed/futures-promises.html
- spark sql 访问hive数据的配置详解
daizj
spark sqlhivethriftserver
spark sql 能够通过thriftserver 访问hive数据,默认spark编译的版本是不支持访问hive,因为hive依赖比较多,因此打的包中不包含hive和thriftserver,因此需要自己下载源码进行编译,将hive,thriftserver打包进去才能够访问,详细配置步骤如下:
1、下载源码
2、下载Maven,并配置
此配置简单,就略过
- HTTP 协议通信
周凡杨
javahttpclienthttp通信
一:简介
HTTPCLIENT,通过JAVA基于HTTP协议进行点与点间的通信!
二: 代码举例
测试类:
import java
- java unix时间戳转换
g21121
java
把java时间戳转换成unix时间戳:
Timestamp appointTime=Timestamp.valueOf(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(new Date()))
SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd hh:m
- web报表工具FineReport常用函数的用法总结(报表函数)
老A不折腾
web报表finereport总结
说明:本次总结中,凡是以tableName或viewName作为参数因子的。函数在调用的时候均按照先从私有数据源中查找,然后再从公有数据源中查找的顺序。
CLASS
CLASS(object):返回object对象的所属的类。
CNMONEY
CNMONEY(number,unit)返回人民币大写。
number:需要转换的数值型的数。
unit:单位,
- java jni调用c++ 代码 报错
墙头上一根草
javaC++jni
#
# A fatal error has been detected by the Java Runtime Environment:
#
# EXCEPTION_ACCESS_VIOLATION (0xc0000005) at pc=0x00000000777c3290, pid=5632, tid=6656
#
# JRE version: Java(TM) SE Ru
- Spring中事件处理de小技巧
aijuans
springSpring 教程Spring 实例Spring 入门Spring3
Spring 中提供一些Aware相关de接口,BeanFactoryAware、 ApplicationContextAware、ResourceLoaderAware、ServletContextAware等等,其中最常用到de匙ApplicationContextAware.实现ApplicationContextAwaredeBean,在Bean被初始后,将会被注入 Applicati
- linux shell ls脚本样例
annan211
linuxlinux ls源码linux 源码
#! /bin/sh -
#查找输入文件的路径
#在查找路径下寻找一个或多个原始文件或文件模式
# 查找路径由特定的环境变量所定义
#标准输出所产生的结果 通常是查找路径下找到的每个文件的第一个实体的完整路径
# 或是filename :not found 的标准错误输出。
#如果文件没有找到 则退出码为0
#否则 即为找不到的文件个数
#语法 pathfind [--
- List,Set,Map遍历方式 (收集的资源,值得看一下)
百合不是茶
listsetMap遍历方式
List特点:元素有放入顺序,元素可重复
Map特点:元素按键值对存储,无放入顺序
Set特点:元素无放入顺序,元素不可重复(注意:元素虽然无放入顺序,但是元素在set中的位置是有该元素的HashCode决定的,其位置其实是固定的)
List接口有三个实现类:LinkedList,ArrayList,Vector
LinkedList:底层基于链表实现,链表内存是散乱的,每一个元素存储本身
- 解决SimpleDateFormat的线程不安全问题的方法
bijian1013
javathread线程安全
在Java项目中,我们通常会自己写一个DateUtil类,处理日期和字符串的转换,如下所示:
public class DateUtil01 {
private SimpleDateFormat dateformat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
public void format(Date d
- http请求测试实例(采用fastjson解析)
bijian1013
http测试
在实际开发中,我们经常会去做http请求的开发,下面则是如何请求的单元测试小实例,仅供参考。
import java.util.HashMap;
import java.util.Map;
import org.apache.commons.httpclient.HttpClient;
import
- 【RPC框架Hessian三】Hessian 异常处理
bit1129
hessian
RPC异常处理概述
RPC异常处理指是,当客户端调用远端的服务,如果服务执行过程中发生异常,这个异常能否序列到客户端?
如果服务在执行过程中可能发生异常,那么在服务接口的声明中,就该声明该接口可能抛出的异常。
在Hessian中,服务器端发生异常,可以将异常信息从服务器端序列化到客户端,因为Exception本身是实现了Serializable的
- 【日志分析】日志分析工具
bit1129
日志分析
1. 网站日志实时分析工具 GoAccess
http://www.vpsee.com/2014/02/a-real-time-web-log-analyzer-goaccess/
2. 通过日志监控并收集 Java 应用程序性能数据(Perf4J)
http://www.ibm.com/developerworks/cn/java/j-lo-logforperf/
3.log.io
和
- nginx优化加强战斗力及遇到的坑解决
ronin47
nginx 优化
先说遇到个坑,第一个是负载问题,这个问题与架构有关,由于我设计架构多了两层,结果导致会话负载只转向一个。解决这样的问题思路有两个:一是改变负载策略,二是更改架构设计。
由于采用动静分离部署,而nginx又设计了静态,结果客户端去读nginx静态,访问量上来,页面加载很慢。解决:二者留其一。最好是保留apache服务器。
来以下优化:
- java-50-输入两棵二叉树A和B,判断树B是不是A的子结构
bylijinnan
java
思路来自:
http://zhedahht.blog.163.com/blog/static/25411174201011445550396/
import ljn.help.*;
public class HasSubtree {
/**Q50.
* 输入两棵二叉树A和B,判断树B是不是A的子结构。
例如,下图中的两棵树A和B,由于A中有一部分子树的结构和B是一
- mongoDB 备份与恢复
开窍的石头
mongDB备份与恢复
Mongodb导出与导入
1: 导入/导出可以操作的是本地的mongodb服务器,也可以是远程的.
所以,都有如下通用选项:
-h host 主机
--port port 端口
-u username 用户名
-p passwd 密码
2: mongoexport 导出json格式的文件
- [网络与通讯]椭圆轨道计算的一些问题
comsci
网络
如果按照中国古代农历的历法,现在应该是某个季节的开始,但是由于农历历法是3000年前的天文观测数据,如果按照现在的天文学记录来进行修正的话,这个季节已经过去一段时间了。。。。。
也就是说,还要再等3000年。才有机会了,太阳系的行星的椭圆轨道受到外来天体的干扰,轨道次序发生了变
- 软件专利如何申请
cuiyadll
软件专利申请
软件技术可以申请软件著作权以保护软件源代码,也可以申请发明专利以保护软件流程中的步骤执行方式。专利保护的是软件解决问题的思想,而软件著作权保护的是软件代码(即软件思想的表达形式)。例如,离线传送文件,那发明专利保护是如何实现离线传送文件。基于相同的软件思想,但实现离线传送的程序代码有千千万万种,每种代码都可以享有各自的软件著作权。申请一个软件发明专利的代理费大概需要5000-8000申请发明专利可
- Android学习笔记
darrenzhu
android
1.启动一个AVD
2.命令行运行adb shell可连接到AVD,这也就是命令行客户端
3.如何启动一个程序
am start -n package name/.activityName
am start -n com.example.helloworld/.MainActivity
启动Android设置工具的命令如下所示:
# am start -
- apache虚拟机配置,本地多域名访问本地网站
dcj3sjt126com
apache
现在假定你有两个目录,一个存在于 /htdocs/a,另一个存在于 /htdocs/b 。
现在你想要在本地测试的时候访问 www.freeman.com 对应的目录是 /xampp/htdocs/freeman ,访问 www.duchengjiu.com 对应的目录是 /htdocs/duchengjiu。
1、首先修改C盘WINDOWS\system32\drivers\etc目录下的
- yii2 restful web服务[速率限制]
dcj3sjt126com
PHPyii2
速率限制
为防止滥用,你应该考虑增加速率限制到您的API。 例如,您可以限制每个用户的API的使用是在10分钟内最多100次的API调用。 如果一个用户同一个时间段内太多的请求被接收, 将返回响应状态代码 429 (这意味着过多的请求)。
要启用速率限制, [[yii\web\User::identityClass|user identity class]] 应该实现 [[yii\filter
- Hadoop2.5.2安装——单机模式
eksliang
hadoophadoop单机部署
转载请出自出处:http://eksliang.iteye.com/blog/2185414 一、概述
Hadoop有三种模式 单机模式、伪分布模式和完全分布模式,这里先简单介绍单机模式 ,默认情况下,Hadoop被配置成一个非分布式模式,独立运行JAVA进程,适合开始做调试工作。
二、下载地址
Hadoop 网址http:
- LoadMoreListView+SwipeRefreshLayout(分页下拉)基本结构
gundumw100
android
一切为了快速迭代
import java.util.ArrayList;
import org.json.JSONObject;
import android.animation.ObjectAnimator;
import android.os.Bundle;
import android.support.v4.widget.SwipeRefreshLayo
- 三道简单的前端HTML/CSS题目
ini
htmlWeb前端css题目
使用CSS为多个网页进行相同风格的布局和外观设置时,为了方便对这些网页进行修改,最好使用( )。http://hovertree.com/shortanswer/bjae/7bd72acca3206862.htm
在HTML中加入<table style=”color:red; font-size:10pt”>,此为( )。http://hovertree.com/s
- overrided方法编译错误
kane_xie
override
问题描述:
在实现类中的某一或某几个Override方法发生编译错误如下:
Name clash: The method put(String) of type XXXServiceImpl has the same erasure as put(String) of type XXXService but does not override it
当去掉@Over
- Java中使用代理IP获取网址内容(防IP被封,做数据爬虫)
mcj8089
免费代理IP代理IP数据爬虫JAVA设置代理IP爬虫封IP
推荐两个代理IP网站:
1. 全网代理IP:http://proxy.goubanjia.com/
2. 敲代码免费IP:http://ip.qiaodm.com/
Java语言有两种方式使用代理IP访问网址并获取内容,
方式一,设置System系统属性
// 设置代理IP
System.getProper
- Nodejs Express 报错之 listen EADDRINUSE
qiaolevip
每天进步一点点学习永无止境nodejs纵观千象
当你启动 nodejs服务报错:
>node app
Express server listening on port 80
events.js:85
throw er; // Unhandled 'error' event
^
Error: listen EADDRINUSE
at exports._errnoException (
- C++中三种new的用法
_荆棘鸟_
C++new
转载自:http://news.ccidnet.com/art/32855/20100713/2114025_1.html
作者: mt
其一是new operator,也叫new表达式;其二是operator new,也叫new操作符。这两个英文名称起的也太绝了,很容易搞混,那就记中文名称吧。new表达式比较常见,也最常用,例如:
string* ps = new string("
- Ruby深入研究笔记1
wudixiaotie
Ruby
module是可以定义private方法的
module MTest
def aaa
puts "aaa"
private_method
end
private
def private_method
puts "this is private_method"
end
end
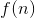 ,那么
,那么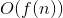 即表示程序的平均时间复杂度(这只是一种简易的记法,关于算法复杂度有严格的数学定义,参见《算法导论》一书,此处不做赘述)。比如我们有一个循环的函数代码如下:
即表示程序的平均时间复杂度(这只是一种简易的记法,关于算法复杂度有严格的数学定义,参见《算法导论》一书,此处不做赘述)。比如我们有一个循环的函数代码如下: 的,也就是
的,也就是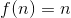 。但是为什么呢?我们可以很简单的算出doSomething();这个语句被执行了n次。而我们的f(n)表示的就是对于某个函数,它执行了多少次基础操作。这里我们很容易看出doSomething()执行了n次,因此f(n)=n。
。但是为什么呢?我们可以很简单的算出doSomething();这个语句被执行了n次。而我们的f(n)表示的就是对于某个函数,它执行了多少次基础操作。这里我们很容易看出doSomething()执行了n次,因此f(n)=n。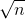 ),因为doSomething();语句被执行了
),因为doSomething();语句被执行了 )。这很好理解,因为当数据规模n很大的时候,
)。这很好理解,因为当数据规模n很大的时候, )、O(
)、O( )、O(logn)、0(n!)。但是呢,不同的时间复杂度之间可以相互组合。更专业的说法是算法复杂度的函数f(n)是线性的。通俗来讲就是说,当我的T算法和S算法属于并列关系,我的总算法时间复杂度是
)、O(logn)、0(n!)。但是呢,不同的时间复杂度之间可以相互组合。更专业的说法是算法复杂度的函数f(n)是线性的。通俗来讲就是说,当我的T算法和S算法属于并列关系,我的总算法时间复杂度是