ConcurrentHashMap1.8 - 结构组成与经典二进制方法
简介说明
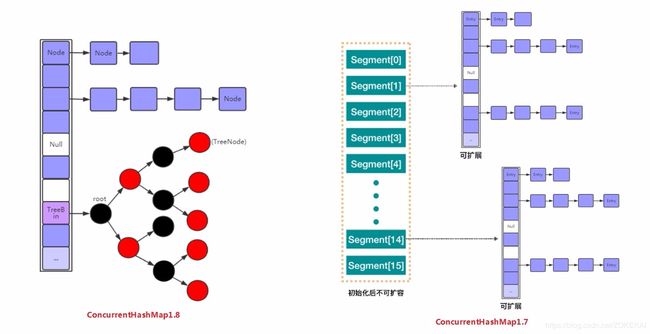
ConcurrentHashMap 是 J.U.C ( java.util.concurrent包 ) 的重要成员,它是HashMap的一个线程安全的、支持高效并发的版本。在默认理想状态下,ConcurrentHashMap可以支持多线程执行并发写操作及读操作。相比于 JDK1.7 的版本,JDK1.8 上的 ConcurrentHashMap 实现已经抛弃了 Segment 分段锁机制,利用CAS + Synchronized 来保证并发更新的安全,底层采用 数组 + 链表 + 红黑树 的存储结构。
说明:该源码来自于 jdk_1.8.0_162 版本。
图解部分
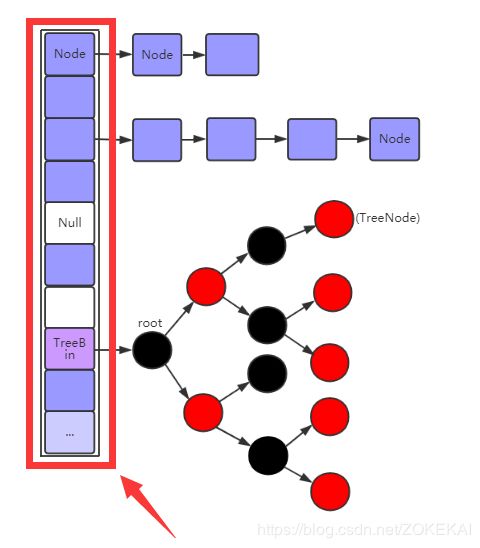
整体结构
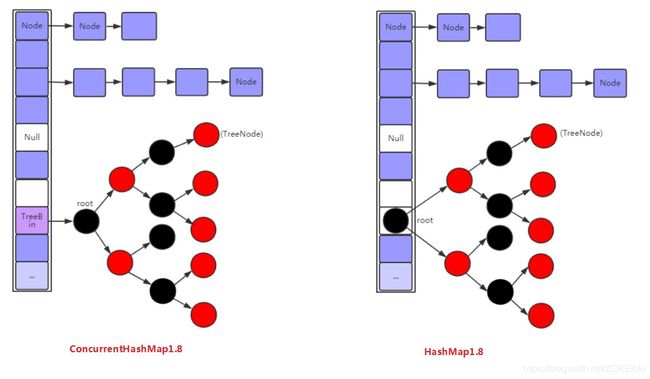
ConcurrentHashMap1.8 与 HashMap1.8 对比
ConcurrentHashMap 1.7 与 1.8 对比
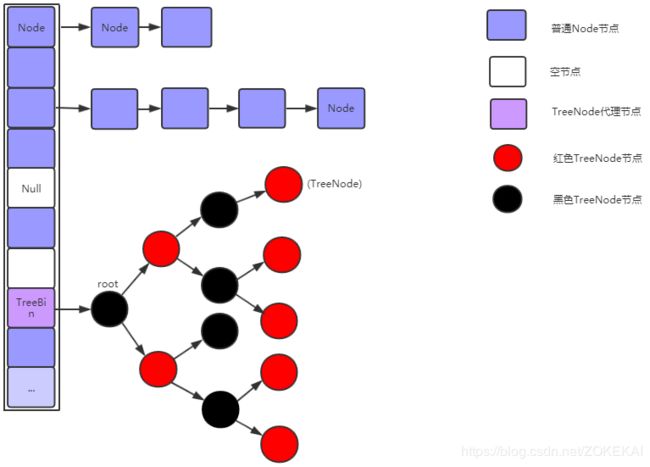
ConcurrentHashMap各结构详解
1、Node节点
Node节点代码:
static class Node implements Map.Entry {
final int hash;
final K key;
volatile V val;
volatile Node next;
Node(int hash, K key, V val, Node next) {
this.hash = hash;
this.key = key;
this.val = val;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return val; }
public final int hashCode() { return key.hashCode() ^ val.hashCode(); }
public final String toString(){ return key + "=" + val; }
public final V setValue(V value) {
throw new UnsupportedOperationException();
}
public final boolean equals(Object o) {
Object k, v, u; Map.Entry e;
return ((o instanceof Map.Entry) &&
(k = (e = (Map.Entry)o).getKey()) != null &&
(v = e.getValue()) != null &&
(k == key || k.equals(key)) &&
(v == (u = val) || v.equals(u)));
}
Node find(int h, Object k) {
Node e = this;
if (k != null) {
do {
K ek;
if (e.hash == h &&
((ek = e.key) == k || (ek != null && k.equals(ek))))
return e;
} while ((e = e.next) != null);
}
return null;
}
} (1) 使用 Node 代替 HashEntry 的原因。
说明:Node 结构和 HashEntry 并无区别,为了便于和红黑树节点 TreeNode 相互转换。
(2) 如何锁住整条Node链表。
说明:使用 synchronized 锁住链表头结点,因为单向链表的操作都是从头结点开始,所以也就锁住了整条链表。
2、Table数组
Table数组相关代码:
/**
* The array of bins. Lazily initialized upon first insertion.
* Size is always a power of two. Accessed directly by iterators.
*/
transient volatile Node[] table;
/**
* The next table to use; non-null only while resizing.
*/
private transient volatile Node[] nextTable; 说明:
(1) table数组在首次 put 操作时初始化。
(2) nextTable数组只在扩容时才被使用到 。
(3) nextTable数组是table数组容量的两倍 。
3、TreeNode节点

TreeNode节点代码:
static final class TreeNode extends Node {
TreeNode parent; // red-black tree links
TreeNode left;
TreeNode right;
TreeNode prev; // needed to unlink next upon deletion
boolean red;
TreeNode(int hash, K key, V val, Node next,
TreeNode parent) {
super(hash, key, val, next);
this.parent = parent;
}
Node find(int h, Object k) {
return findTreeNode(h, k, null);
}
/**
* Returns the TreeNode (or null if not found) for the given key
* starting at given root.
*/
final TreeNode findTreeNode(int h, Object k, Class kc) {
if (k != null) {
TreeNode p = this;
do {
int ph, dir; K pk; TreeNode q;
TreeNode pl = p.left, pr = p.right;
if ((ph = p.hash) > h)
p = pl;
else if (ph < h)
p = pr;
else if ((pk = p.key) == k || (pk != null && k.equals(pk)))
return p;
else if (pl == null)
p = pr;
else if (pr == null)
p = pl;
else if ((kc != null ||
(kc = comparableClassFor(k)) != null) &&
(dir = compareComparables(kc, k, pk)) != 0)
p = (dir < 0) ? pl : pr;
else if ((q = pr.findTreeNode(h, k, kc)) != null)
return q;
else
p = pl;
} while (p != null);
}
return null;
}
} 说明:
(1) 继承 Node 节点,所以 TreeNode 可以和 Node 相互转换。
(2) 由于 TreeNode 新增了 prev 指针,又因为继承的 Node 本身是个单向链表,同时拥有 next 和 prev 指针,所以 TreeNode 是一个双向链表。
(3) 由于 TreeNode 拥有了 prev 指针,ConcurrentHashMap 使用红黑树的方式删除某一个 TreeNode 时更加方便,这是因为通常我们使用单向链表的方式删除一个节点时,必须从头节点往后遍历,遍历到要删除的节点才可以删除,而使用红黑树的方式删除某个节点时并不按单向链表的方式遍历,而可能是从链表的中间删除某个节点,这个时候直接可以拿到上个链表的指针就可以从任意地方删除节点。
(4) TreeNode 作为红黑树节点,自然就可以以红黑树的方式遍历 TreeNode 节点,但我们上面也提到,TreeNode 同时还拥有着一个双向链表的性质,这也就意味着我们在遍历红黑树节点时不仅可以以红黑树的方式去遍历他,还能以链表的方式去遍历他,为什么要这么做呢,下面 TreeBin 部分的内容将会对这个疑问进行解答。
4、TreeBin 节点

说明:
(1) TreeBin 是操作 TreeNode 的入口(代理节点) 。这么说的原因是因为 TreeBin 包含有红红黑树的 root 节点以及双向链表的 first 节点,所有对双向链表和红黑树的操作都必须要从 first / root 节点开始,操作时锁住 first / root 节点即可锁住 双向链表 / 红黑树,所以说 TreeBin 是操作 TreeNode 的代理节点 。
(2) TreeBin 内部锁 。 TreeBin 继承于 Node 节点,同样也可以使用相同的方式,也就是使用 synchronized 对节点自身进行加锁,由上面的结构可以看出,TreeBin 还额外定义了一个内部锁,用于对红黑树的读写操作进行更细致的控制,以达到性能的提升 (后面再详解) 。
内部锁大致工作方式如下:
<1> 在 put / remove / replace 操作之前,和对 Node 链表的操作一样,均会先锁住 TreeBin 节点;
<2> 然后根据实际情况设置 TreeBin 里面维护的 读 / 写 锁的状态;
<3> get 操作时先判断 TreeBin 自己维护的锁状态,根据锁状态选择用链表还是红黑树的方式遍历节点;
涉及到的经典二进制方法
一、位运算基础
1、移位操作

2、按位运算

二、tableSizeFor 方法
1、tableSizeFor 方法用处


说明:tableSizeFor 方法主要用于创建 ConcurrentHashMap 时将任意输入的初始值转换为大于或等于该初始值的 2 ^ n 的数 。典型的应用是在初始化集合时计算初始容量大小 。
2、tableSizeFor 方法引入

结论:想要用二进制构造一个 2^n 的数,从左往右看,从第一个不为 0 的数开始,将他的右边的数全部变为 1 ,最后再加 1 。
即可得到一个距离该数最近的并且大于该数的 2 ^ n 的数。
不信,我们实践一下:

3、tableSizeFor 方法详解 (借鉴了一下别人的图)

探讨:这里我们来探讨一下一个有趣的问题,那就是tableSizeFor 方法的入参:
(1) 我们先来看看 JDK8 早期版本的入参:

(2) JDK1.8.0_162上面的入参

这里面肯定是一个优化,既然猜不出来那我们就实际运行起来看看结果对比:

结论:对比前后两个结果,我们直接看 [tableSizeFor] 这一列的对比,当 initialCapacity = 1 时,没有使用 [initialCapacity + (initialCapacity >>> 1) + 1] 入参计算出来的容量为 1,而使用后结果为 2,我们都知道一个数组长度 n 为 1 的 Map 集合,只要向其存入一个值就会扩容,而数组长度 n 为 2 的 Map 集合就不会 。继续,一般来说,当我新建一个容量为 2 的 Map 时,我往往都会存入 2 个元素,所以如果没有使用 [initialCapacity + (initialCapacity >>> 1) + 1] 入参,tableSizeFor 方法计算出来的容量依旧是 2 ,当我插入第二个元素时,Map 集合就会发生扩容 。由以上分析可见,不恰当的集合初始化值的计算结果会导致集合频繁扩容,尤其是集合数据较多时影响更大,而由上面的分析可知,使用这个修改过后的入参正好可以避免频繁扩容的问题,算是 ConcurrentHashMap 的一个性能优化 。
三、spread 方法
1、spread 方法用处
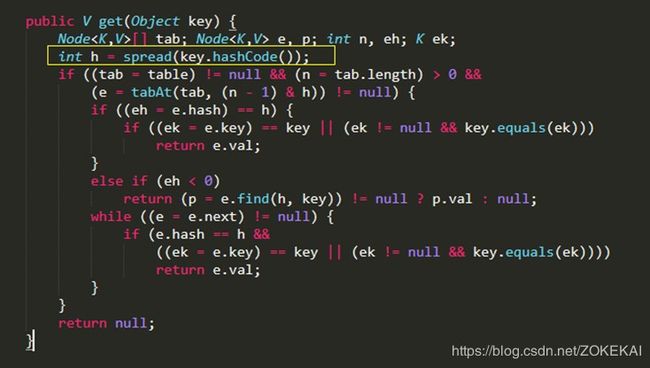

说明:spread 方法又称扰动函数,这个方法普遍在各种 get put 方法中都有用到,目的在于将 hash 值的 高16位 和 低16位 的特征进行混合,从而尽可能得到一个独特的 hash 值,以减少 hash 冲突。在获取或者插入数据操作之前都要使用这个方法对原始的 hashCode 进行二次 hash 。
2、使用 spread 方法的效果
使用前:

使用后:

结论:由上图可以看出,在使用前,两个不同的hash值(也可理解为两个不同的key),在直接进行&运算后,结果发生hash冲突了,在使用 spread 方法后,可以看出最后没有发生hash冲突,可以看出 spread 方法的作用就是减少 hash 冲突 。(举的例子不是特例,而是普遍情况)
3、(h ^ (h >>> 16)) & HASH_BITS 详解
接下来我们就来看看 spread 方法能达到减少 hash 冲突的原因所在:
说明:HASH_BITS = 0x7FFFFFFF = 0111 1111 1111 1111 1111 1111 1111 1111 (和该特殊值做与运算有取绝对值的效果)

四、 (n - 1) & h 解析
1、(n - 1) & h 用处

说明:在 get put 等方法中,在获得 spread 方法进行二次 hash 的 hash 值后,(n - 1) & h 用于计算该元素在table数组中的位置。
2、求证: h & (n - 1) = h % n
我们普遍的一个认知是在获取HashMap集合上数组某个位置的值时可以通过取模的方式去定位到该位置,但是ConcurrentHashMap 在这里使用的却不是常规的取模操作,但最后的计算结果是一样的 。原因在于这里面的 % 运算比 & 运算效率要低,通过这种位运算能够提高定位效率,所以就引出了标题的这个问题,为什么这两种做法的结果会是一样的,我们来探讨一下:

总结:n – 1 也就是 2的幂次方数 -1 的数 ,而 2的幂次方数 - 1 转化成二进制数后就是上图中的后面若干位数值全为 1 的数,通过这个后几位全为 1 的数,正好可以把不足 2的幂次方数的数值(余数) 很巧妙的取(框)出来 。这也是为什么HashMap之类的集合的数组长度为什么取 2的幂次方数的原因之一,因为 & 运算比 % 运算性能要高 。
n - 1 同时还能防止数组越界:

说明:如果上面的 n 没有减去 1,那我们去定位的时候很容易获取到一个超过数组下标的值,引发数组越界异常(数组长度为 16 的最大数组下标是 15) 。