备忘:Wiki关于Graph数据库信息汇总
Graph database
来源:http://en.wikipedia.org/wiki/Graph_database
In computing, a graph database is a database that uses graph structures with nodes, edges, and properties to represent and store data. A graph database is anystorage system that provides index-free adjacency.[1] This means that every element contains a directpointer to its adjacent elements and no index lookups are necessary. General graph databases that can store any graph are distinct from specialized graph databases such astriplestores and network databases.
Contents
- 1Structure
- 2Properties
- 3Graph database projects
- 4Graph database features
- 5Distributed Graph Processing
- 6GPGPU Graph Processing
- 7APIs and Graph Query/Programming Languages
- 8See also
- 9References
- 10External links
Structure
Graph databases are based on graph theory. Graph databases employ nodes, properties, and edges.
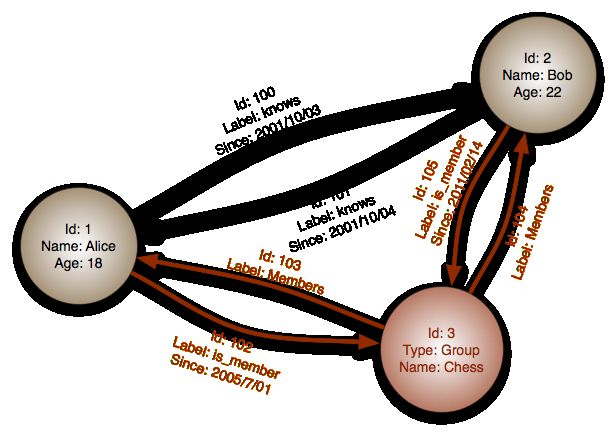
Nodes represent entities such as people, businesses, accounts, or any other item you might want to keep track of.
Properties are pertinent information that relate to nodes. For instance, if "Wikipedia" were one of the nodes, one might have it tied to properties such as "website", "reference material", or "word that starts with the letter 'w'", depending on which aspects of "Wikipedia" are pertinent to the particular database.
Edges are the lines that connect nodes to nodes or nodes to properties and they represent the relationship between the two. Most of the important information is really stored in the edges. Meaningful patterns emerge when one examines the connections and interconnections of nodes, properties, and edges.
Properties
Compared with relational databases, graph databases are often faster for associative data sets[citation needed], and map more directly to the structure of object-oriented applications. They can scale more naturally to large data sets as they do not typically require expensivejoin operations. As they depend less on a rigid schema, they are more suitable to manage ad hoc and changing data with evolving schemas. Conversely, relational databases are typically faster at performing the same operation on large numbers of data elements.
Graph databases are a powerful tool for graph-like queries, for example computing the shortest path between two nodes in the graph. Other graph-like queries can be performed over a graph database in a natural way (for example graph's diameter computations or community detection).
Graph database projects
The following is a list of several well-known graph database projects:[2]
| Name | Version | License | Language | Description |
|---|---|---|---|---|
| AllegroGraph | 4.13.1 (November 2013) | Proprietary, Clients - Eclipse Public License v1 | C#,C, Common Lisp, Java, Python | A RDF and graph database. |
| ArangoDB | 2.2.1 (July 2014) | Apache 2 | C,C++ &Javascript | A distributed multi-model document store and graph database. Highly scalable supporting ACID and full transaction support. Including a built-in graph explorer. |
| Bigdata | 1.3.1 (May 2014) | GPLv2, evaluation license, or commercial license. | Java | A RDF/graph database capable of clustered deployment. Bigdata supports high availability (HA) mode, embedded mode, single server mode. As of version 1.3.1, it supports the Blueprints API and Reification Done Right (RDR). |
| Bitsy | 1.5.0 | AGPL, Enterprise license (unlimited use, annual/perpetual) | Java | A small, embeddable, durable in-memory graph database |
| BrightstarDB | MIT License[3] | C# | An embeddable NoSQL database for the .NET platform with code-first data model generation. | |
| DEX/Sparksee[4] | 5.0.0 (2014) | evaluation, research or development use (free) / commercial use | C++ | A high-performance and scalable graph database management system from Sparsity Technologies, a technology transition company from DAMA-UPC. Its main characteristics is its query performance for the retrieval & exploration of large networks.Sparksee 5 mobile is the first graph database for mobile devices. |
| Filament | BSD | Java | A graph persistence framework and associated toolkits based on a navigational query style. | |
| GraphBase | 1.0.03a | Proprietary | Java | A customizable, distributed, small-footprint graph store with a rich tool set fromFactNexus. |
| Graphd | Proprietary | The proprietary back-end of Freebase. | ||
| Horton | Proprietary | C# | A graph database from Microsoft Research Extreme Computing Group (XCG) based on the cloud programming infrastructureOrleans. | |
| HyperGraphDB | 1.2 (2012) | LGPL | Java | A graph database supporting generalized hypergraphs where edges can point to other edges. |
| IBM System G Native Store | v1.0 (July 2014) | Proprietary | C,C++,Java | A high performance graph store using natively implemented graph data structures and primitives for achieving superior efficiency. IBM System G Native Store can handle various simple graphs, property graphs, and RDF graphs, in terms of storage, analytics, and visualization. Native Store is accessible from most programming languages by providing APIs in C++, Java (Tinkerpop/Blueprints), and Python. Its gShell graph command collection and the Native Store REST APIs provide language-free interfaces. |
| InfiniteGraph | 3.0 (January 2013) | Proprietary | Java | A distributed and cloud-enabled commercial product with flexible licensing. |
| InfoGrid | 2.9.5 (2011) | AGPLv3, free for small entities[5] | Java | A graph database with web front end and configurable storage engines (MySQL, PostgreSQL, Files, Hadoop). |
| jCoreDB Graph | An extensible database engine with a graph database subproject. | |||
| MapGraph | v3 (2014) | Apache 2 | CUDA | MapGraph is Massively Parallel Graph processing on GPUs. The MapGraph API makes it easy to develop high performance graph analytics on GPUs. The API is based on the Gather-Apply-Scatter (GAS) model as used in GraphLab.[6] MapGraph is up to two orders of magnitude faster than parallel CPU implementations on up 24 CPU cores and has performance comparable to a state-of-the-art manually optimized GPU implementation. New algorithms can be implemented in a few hours that fully exploit the data-level parallelism of the GPU and offer throughput of up to 3.3 billion traversed edges per second on a single GPU.[7] and up to 30 billion traversed edges per second on a cluster with 64 GPUs [8] |
| Neo4j | 2.1.3 (April 2014) | GPLv3 Community Edition. Commercial & AGPLv3 options for Enterprise and Advanced editions[9] | Java | A highly scalable open source graph database that supports ACID, has high-availability clustering for enterprise deployments, and comes with a web-based administration tool that includes full transaction support and visual node-link graph explorer.[10] Neo4j is accessible from most programming languages using its built-in REST web API interface. Neo4j is the most popular graph database in use today.[11] |
| Orly | [4] (March 2014) | Apache 2[12] | C++ | A highly scalable open source graph database.[13] Orly is accessible from most programming languages using its built-in REST web API interface. Orly is a popular graph database in use today. |
| OpenLinkVirtuoso | 7.1 (March 2014) | GPLv2 forOpen Source Edition. Proprietary for Enterprise Edition. | C,C++ | A hybrid database server handling RDF and other graph data, RDB/SQL data, XML data, filesystem documents/objects, and free text. May be deployed as a local embedded instance (as used in theNepomuk Semantic Desktop), a single-instance network server, or a shared-nothing elastic-cluster multiple-instance networked server.[14] |
| Oracle Spatial and Graph | 11.2 (2012) | Proprietary | Java, PL/SQL | 1) RDF Semantic Graph: comprehensive W3C RDF graph management in Oracle Database with native reasoning and triple-level label security. 2) Network Data Model property graph: for physical/logical networks with persistent storage and a Java API for in-memory graph analytics. |
| Oracle NoSQL Database | 2.0.39 (2013) | Proprietary | Java | RDF Graph for Oracle NoSQL Database is a feature of Enterprise Edition providing W3C RDF graph capabilities in NoSQL Database. |
| OrientDB | 1.6.1 (November 2013) | Apache 2 | Java | A distributed Graph Database with a hybrid model taken from Document Database. |
| OQGRAPH | GPLv2 | A graph computation engine for MySQL, MariaDB and Drizzle. | ||
| OntotextOWLIM | 5.3 | OWLIM Lite is free OWLIM SE and Enterprise are commercially licenced |
Java | A graph database engine, based entirely on Semantic Web standards from W3C: RDF, RDFS, OWL, SPARQL. OWLIM Lite is an "in memory" engine. OWLIM SE is robust standalone database engine. OWLIM Enterprise is a clustered version which offers horizontal scalability and failover support and other enterprise features. |
| R2DF | R2DF framework for ranked path queries over weighted RDF graphs. | |||
| ROIS | Freeware | Modula-2 | A programmable knowledge server that supports inheritance and transitivity. Used in OpenGALEN as a Terminology Server. | |
| sones GraphDB | AGPLv3[15] | C# | A graph database and universal access layer (funded by Deutsche Telekom). | |
| Sqrrl Enterprise | v1.5.1 (August 2014) | Proprietary | Java | Distributed, real-time graph database featuring cell-level security and massive scalability. |
| Stardog | v2.2 (July 2014) | Proprietary | Java | Fast, scalable, pure Java semantic graph database. |
| Teradata Aster | v6 (2013) | Proprietary | Java,SQL, Python, C++, R | A high performance, multi-purpose, highly scalable and extensible MPP database incorporating patented engines supporting native SQL, MapReduce and Graph data storage and manipulation. An extensive set of analytical function libraries and data visualization capabilities are also provided. |
| Titan | 0.5.0 (2014) | Apache 2 | Java | A distributed, real-time,scalable transactional graph database developed by Aurelius. |
| Trinity | C#,C, X64 Assembly | A distributed general purpose graph engine on a memory cloud. | ||
| VelocityGraph | Open source with proprietary back-end | C# | High performance, scalable & flexible graph database build with VelocityDB object database. | |
| VertexDB | Revised BSD | C | A graph database server that supports automatic garbage collection. | |
| WhiteDB | 0.7.0 (October 2013) | GPLv3 and a free commercial licence | C | A graph/N-tuples shared memory database library. |
Graph database features
The following table compares the features of the above graph databases.
| Name | Graph Model | API | Query Methods | Visualizer | Consistency | Backend | Scalability |
|---|---|---|---|---|---|---|---|
| AllegroGraph | RDF | Java, Java:Sesame, JavaJena, Python, Ruby, Perl, C#, Clojure, Lisp, Scala, REST | SPARQL 1.1, Prolog, JIG, JavaScript | Gruff - View Graphs, Visual Query Builder for SPARQL and Prolog | ACID | Native Graph Storage | 1 Trillion RDF triples |
| ArangoDB | Property Graph | JavaScript, Blueprints, REST | Graph Traversals via JavaScript, Gremlin | Built-in graph explorer | MVCC/ACID | native C/C++ | Replication and Sharding |
| Bigdata | RDF | Java, Sesame, Blueprints, Gremlin, SPARQL, REST | SPARQL, Gremlin | Bigdata Workbench UI | MVCC/ACID | Native Java | Embedded,Client/Server, High Availability (HA) |
| Bitsy | Property Graph | Blueprints | Gremlin, Pixy | ACID with optimistic concurrency control | Human-readable JSON-encoded text files with checksums and markers for recovery | ||
| DEX/Sparksee[16] | Labeled and directed attributed multigraph | Java,C++,.NET, Python | Native Java, C#, Python and C++ APIs, Blueprints, Gremlin | Exporting functionality to visualization formats | Consistency, durability and partial isolation and atomicity | Native graph. light and independent data structures with a small memory footprint for storage | Master/Slave replication |
| Filament | |||||||
| GraphBase Enterprise(1)GraphBase Agility(2) | (1) mixed, (2) Framework-managed Simple Graph | Java | Bounds Language, embedded java | GraphPad, BoundsPad, Navigator | ACID, graph-based transactions | proprietary native | (1) shared nothing distributed, (2) simple replication, 100+ Billion arcs per server |
| Graphd | |||||||
| Horton | Attributed multigraph | Horton Query Language (Regular Language Expression + SQL) | C#, .Net Framework, Asynchronous communication protocols | ||||
| HyperGraphDB | Object-oriented multi-relational labeled hypergraph | Custom,Java | MVCC/STM | ||||
| IBM System G Native Store | Property Graph, RDF* | C++, Java, Python | Native Store gShell, Gremlin, SPARQL | Built-in Visualizer | ACID | Native Graph Storage | Both scale-up (using multithreading) and scale-out (using IBM PAMI) |
| InfiniteGraph | Labeled and directed multi-property graph | Java, Blueprints (Read Only) | Java (with parallel, distributed queries), Gremlin (Read Only) | Graph browser for developers. Plugins to allow use of external libraries. | ACID. There is also a parallel, loosely synchronized batch loader. | Objectivity/DB on standard filesystems | Distributed & Sharded. Objectivity/DB was the first DBMS to store a Petabyte of objects. |
| InfoGrid | Dynamically typed, object-oriented graph, multigraphs, semantic models | ||||||
| jCoreDB Graph | |||||||
| Neo4j | Property Graph | Java, Python, JPython, Ruby, JRuby, JavaScript (Node.js), PHP, .NET, Django, Clojure, Spring, Scala, or REST (any language) | Cypher (native/preferred), Native Java APIs (special cases), Traverser API, REST, Blueprints, Gremlin | Data Browser included. Supports a variety of 3rd party tools: Gephi, Linkurio.us, Cytoscape, Tom Sawyer, Keylines, etc. | ACID | Native graph storage with native graph processing engine | Horizontal read scaling via master-slave clustering with cache sharding. |
| OpenLinkVirtuoso | RDF graph: Triple & Quad (named graphs); expandable column store | SPARQL, XMLA, ODBC, JDBC, ADO.NET, OLE DB, Jena, Sesame, Virtuoso PL/SQL, Java, Python, Perl, PHP, HTTP, etc. | SPARQL 1.1; SPARQL web service endpoint; SQL; others | Pivot Viewer (Silverlight or HTML5); OpenLink Data Explorer; SPARQL-compliant tools; Apache Jena-based tools; XML & JSON-based tools; SQL based tools | ACID | Internal column-store or row-store (depending on licensure), hybrid RDF/SQL/RDB engine | Infinite via Commercial Edition's Cluster Module elastic cluster functionality; simple master-slave clustering of single-server instances also an option. |
| Oracle Spatial and Graph | RDF graph: Triple & Quad (named graphs); Network Data Model property graph | Java; Apache Jena; PL/SQL | SPARQL 1.1; SPARQL web service end point; SQL | SPARQL-compliant tools; Apache Jena-based tools; XML & JSON-based tools; SQL based tools | ACID | Efficient, compressed, partitioned graph storage; Native persisted in-database inferencing; SPARQL 1.1 & SQL integration; Triple-level label security; Semantic indexing of documents | Parallel load, query, inference; Query controls; Scales from PC to Oracle Exadata; Supports Oracle Real Application Clusters and Oracle Database 8 exabytes |
| Oracle NoSQL Database | RDF graph: Triple default graph, Triple & Quad named graphs | Java (Apache Jena) | SPARQL 1.1; SPARQL web service end point | SPARQL-compliant tools; Apache Jena-based tools; XML & JSON-based tools | ACID; Configurable consistency & durability policies | Key/value store; W3C SPARQL 1.1 & Update; In-memory RDFS/OWL inferencing | Parallel load/query; Query controls for: parallel execution, timeout, query optimization hints |
| OrientDB | Property Graph | Java Traverser API, Blueprints, Rexster, Javacript[17] | Own SQL-like Query Language, Gremlin | ACID, MVCC | Custom on disc or in memory | ||
| OQGRAPH | |||||||
| R2DF | |||||||
| ROIS | |||||||
| sones GraphDB | |||||||
| Sqrrl Enterprise | Property Graph | Thrift, Blueprint | Own SQL-like query language and Java API | Integrates with 3rd party tools | Fully Consistent and ACID (transactions limited to a single graph node) | Accumulo | Distributed cluster with tens of trillions of edges |
| Stardog | RDF | Java, Sesame, Jena, SNARL, HTTP/REST, Python, Ruby, Node.js, C#, Clojure, Spring | SPARQL 1.1 | Stardog Web, Pelorus | ACID | Native Graph Storage | 50 billion RDF triples on $10,000 server |
| Titan | Property Graph | Java, Blueprints, REST, RexPro binary protocol, Python, Clojure (any language) | Gremlin, SPARQL | Integrates with 3rd party tools | ACID or Eventually Consistent | Cassandra, HBase, MapR M7 Tables, Berkeley DB, Persistit, Hazelcast | Distributed cluster (120 billion+ edges) or single server. |
| Trinity | Cell Based Graph Model | C# | Trinity Query Language | Cell level Atomicity | Native graph store and processing engine | billion node in-memory graph | |
| VertexDB |
Distributed Graph Processing
- Angrapa - graph package inHama, a bulk synchronous parallel (BSP) platform
- Apache Hama - a pure BSP(Bulk Synchronous Parallel) computing framework on top of HDFS (Hadoop Distributed File System) for massive scientific computations such as matrix, graph and network algorithms.
- Bigdata - A RDF/graph database capable of clustered deployment. Bigdata supportshigh availability (HA) mode, embedded mode, single server mode and has available commercial licenses. As of version 1.3.1, it supports the Blueprints API and Reification Done Right (RDR).
- Faunus - a Hadoop-based graph computing framework that uses Gremlin as its query language. Faunus provides connectivity to Titan, Rexster-fronted graph databases, and to text/binary graph formats stored in HDFS. Faunus is developed byAurelius.
- FlockDB - an open source distributed, fault-tolerant graph database based onMySQL and theGizzard framework for managing Twitter-like graph data (single-hop relationships)FlockDB on GitHub.
- Giraph - a Graph processing infrastructure that runs on Hadoop (see Pregel).
- GraphBase - Enterprise Edition supports embedding of callable Java Agents within the vertices of a distributed graph.
- GoldenOrb - Pregel implementation built on top of Apache Hadoop
- GraphLab - A framework for machine learning and data mining in the cloud
- GraphX - GraphLab built on theSpark cluster computing system. Dr. Joseph Gonzalez is the project lead, the creator of GraphLab.
- HipG - a library for high-level parallel processing of large-scale graphs. HipG is implemented in Java and is designed for distributed-memory machine
- IBM System G Graph Analytics Toolkit - A comprehensive graph analytics library consisted of network topological analysis tools, graph matching and search tools, and graph path and flow tools. It has been applied to various use cases and industry solutions.
- InfiniteGraph - a commercially available distributed graph database that supports parallel load and parallel queries.
- JPregel - In-memory java based Pregel implementation
- KDT - An open-source distributed graph library with a Python front-end and C++/MPI backend (Combinatorial BLAS).
- OpenLinkVirtuoso - the shared-nothing Cluster Edition supports distributed graph data processing.
- Oracle Spatial and Graph - loading, inferencing, and querying workloads are automatically and transparently distributed across the nodes in an Oracle Real Application Cluster, Oracle Exadata Database Machine, and Oracle Database Appliance.
- Phoebus - Pregel implementation written in Erlang
- Pregel - Google's internal graph processing platform, released details in ACM paper.
- Powergraph - Distributed graph-parallel computation on natural graphs.
- PowerLyra - A distributed graph analytics based on GraphLab using differentiated graph computation and partitioning on skewed (e.g. power-law and bipartite) graphs (dynamically applying different computation and partition strategies for different vertices).
- Cyclops - A computation and communication efficient graph processing system with significantly low communication cost.
- Imitator - A reliable distributed graph processing system with replication-based fault-tolerance.
- Sedge - A framework for distributed large graph processing and graph partition management (including an open source version of Google's Pregel)
- Signal/Collect - a framework for parallel graph processing written in Scala
- Sqrrl Enterprise - distributed graph processing utilizingApache Accumulo and featuring cell-level security, massive scalability, and JSON support
- Titan - A distributed, disk-based graph database developed byAurelius.
- Trinity - Distributed in-memory graph engine under development at Microsoft Research Labs.
- Parallel Boost Graph Library (PBGL) - aC++ library for graph processing on distributed machines, part ofBoost framework.
- Mizan - An optimized Pregel clone that can be deployed easily on Amazon EC2, local clusters, stand-alone Linux systems and supercomputers (IBM BlueGene/P). It utilizes runtime graph repartitioning between iterations to provide dynamic load balancing for better algorithm performance.[18]
GPGPU Graph Processing
- Medusa - A framework for graph processing using Graphics Processing Units (GPUs) on both shared memory and distributed environments. Medusa allows users with no GPU programming expertise to leverage GPUs for graph processing.
APIs and Graph Query/Programming Languages
- Bounds Language - terse C-style syntax which initiates concurrent traversals in GraphBase and supports interaction between them.
- Blueprints - a Java API for Property Graphs fromTinkerPop and supported by a few graph database vendors.
- Blueprints.NET - a C#/.NET API for generic Property Graphs.
- Bulbflow - a Python persistence framework for Rexster, Titan, and Neo4j Server.
- Cypher Query Language - a declarative graph query language forNeo4j that enables ad hoc as well as programmatic (SQL-like) access to the graph
- Gremlin - an open-source graph programming language that works over various graph database systems.
- Neo4jClient - a .NET client for accessingNeo4j.
- Neography - a thin Ruby wrapper that provides access toNeo4j via REST.
- Neo4jPHP - a PHP library wrapping the Neo4j graph database.
- NodeNeo4j - a Node.js driver for Neo4j that provides access toNeo4j via REST
- Pacer - a Ruby dialect/implementation of the Gremlin graph traversal language.
- Pipes - a lazy dataflow framework written in Java that forms the foundation for various property graph traversal languages.
- Pixy - a declarative graph query language that works on any Blueprints-compatible graph database
- PYBlueprints - a Python API for Property Graphs.
- Pygr - a Python API for large-scale analysis of biological sequences and genomes, with alignments represented as graphs.
- Rexster - a graph database server that provides a REST or binary protocol API (RexPro). Supports Titan, Neo4j, OrientDB, Dex, and any TinkerPop/Blueprints-enabled graph.
- SPARQL - a query language for databases, able to retrieve and manipulate data stored inResource Description Framework format.
- SPASQL - an extension of the SQL standard, allowing execution of SPARQL queries within SQL statements, typically by treating them as subquery or function clauses. This also allows SPARQL queries to be issued through "traditional" data access APIs (ODBC,JDBC, OLE DB, ADO.NET, etc.)
- Spring Data Neo4j - an extension toSpring Data (part of the Spring Framework), providing direct/native access to Neo4j
- Oracle SQL and PL/SQL APIs - have graph extensions for Oracle Spatial and Graph.
- Styx (previously named Pipes.Net) - a data flow framework for C#/.NET for processing generic graphs and Property Graphs.
- Thunderdome - a Titan Rexster Object-Graph Mapper for Python
See also
- NoSQL
- Document-oriented database
- Structured storage
- Object database
- Resource Description Framework (RDF) - framework to express node-edge graphs
- Graph transformation for a complementary topic (rule based in memory manipulation of graphs instead oftransaction safe persistence).
- RDF Database
References
- "Glossary of Big Data Terminology". Retrieved 5 August 2013.
- http://graph-database.org
- http://brightstardb.com/blog/2013/02/brightstardb-goes-open-source/
- http://sparsity-technologies.com#sparksee
- http://infogrid.org/wiki/Docs/License
- [1] Retrieved Aug 7, 2014.
- [2] Retrieved Aug 7, 2014.
- [3] Retrieved Aug 7, 2014.
- neo4j.org
- Neo4j, World’s Leading Graph Database. Retrieved September 16, 2013.
- DB-Engines Ranking of Graph DBMS. Retrieved July 19, 2013.
- neo4j.org
- Orly, Graph Database. Retrieved March 16, 2014.
- OpenLink Software."Clustering Deployment Architecture Diagrams for Virtuoso (Release 6 and later, Commercial Edition only)".Virtuoso Open-Source Wiki. OpenLink Software. Retrieved 2014-05-01.
- http://sones.com/
- http://sparsity-technologies.com#sparksee
- OrientDB Javascript API wiki on the project's Github page
- http://dl.acm.org/citation.cfm?id=2465369
External links
- NoSQL Frankfurt 2010 - The GraphDB Landscape and sones
- Graph Databases and the Future of Large-Scale Knowledge Management
- Top Graph Databases
- Social networks in the database: using a graph database
- Scaling Online Social Networks without Pains
- Large-scale Graph Computing at Google
- Eric Lai. (2009, July 1). No to SQL? Anti-database movement gains steam
- Renzo Angles, Claudio Gutierrez. Survey of graph database models. ACM Computing Surveys, Feb. 2008.
- InfoGrid - an open-source application platform including a graph database
- Rodriguez, M.A., Neubauer, P, The Graph Traversal Pattern article.
- Optimizing Schema-Last Tuple-Store Queries in Graphd SIGMOD 2010
- IBM System G Native Graph Store
|
||||||||||||||
- Graph databases
- Database models