十一.增加数据
现有一张student表,表设计如下:

sno为主键并自增,saddress 表示地址,设定了默认值:'广东省广州市'
1.完整的增加一条 insert into tables values(val1,val2,...,valn)
insert into student values(NULL,'李冰','男','[email protected]')
注意:
a.必需要保证values() 中的值 与 表中列的按顺序顺序一一对应 ,个数一致
b.sno主键设置自增后,可以交由mysql 自动处理, 可以传入NULL值,此时该记录的 sno 会由自动生成
缺点:当表结构发生变化时,此时insert 会报错
2.按照指定列增加 insert into table_name(column1,column2,...,columnn) values(val1,val2,...,valn)
insert into student(sname,ssex) values('王明','男')
注意:
a.同样需要保证values中的值的个数 与前面指定的 列的个数顺序 对应
优点:
a.列的顺序可以自己指定, 同样value值也要与列名对应 ,以后表中新增列时,insert 语句 不会受影响
b.相比插入完整的一行 , 插入指定列,一些不必要的值,可以不用传, 只需要传一些必传的值,sql语句变的更简洁了
3.增加多行记录 Insert into table_name valuesvalues(val1,val2,...,valn),values(val1,val2,...,valn),values(val1,val2,...,valn)
insert into student values(NULL,'李玲','女','liling163.com'),(NULL,'大才','男',NULL),(NULL,'逍遥','男','[email protected]')
在 1 ,2 的基础上 只需要在values 后 跟上多组数据即可,插入多行
优点: 插入多行有两种形式, 单行插入执行多次 , 多行插入执行1次 , 相比前者而言 ,多行插入执行1次, 性能耗时会大大减少
4.插入 select语句查询出的数据
insert into student(sname,ssex,semail,saddress)
select sname,ssex,semail,saddress from student
这种方式 不会要求select查出的列名与 需要插入数据的表的列名 一致, 只需保证顺序一致, 数据兼容即可
insert 提高数据库性能:
1.生产中, 可能会出现并发访问数据库,进行增删改查的情况, 一般情况查的优先级更高一些. 同时insert 时,需要建立索引 耗时较久,同时还可能造成后续select语句性能的降低
此时可以通过降低 insert 语句的优先级, 来提高性能 ;语法格式: insert low_priority into ... . 同样也适用于delete update语句
2.多行插入执行1次 性能要高于 一行插入执行多次
安全: 可以禁用用户的insert权限,限制部分用户的不可以进行insert 保证数据的安全
十二.更新,删除 数据
update 语句一定要搭配where子句使用,否则更新就是更新整张表中的所有数据,这种误操作,会造成难以想象的结果....
错误: update table_name set column = newValue #会更新表中所有记录该列的值
更新单列 update tablename set column = newValue where condition
update student set semail = '[email protected]' where sname = '王明'
更新多列update tablename set column1 = newValue1 ,column2 = newValue2,...column_n = newValuen where condition
update student set semail = '[email protected]',saddress = '广东省东莞市' where sname = '王明'
如果希望在更新某一列或多列出现错误时,不停止update,而是跳过出错的这一列,保持其他列的更新,则可以使用 ignore关键字,格式如下:
update ignore tablename set .....
例子:
不加ignore关键字:
update student set ssex = '未知性别' ,semail = '[email protected]',saddress = '广东省深圳市' where sname = '王明'
执行报错:[Err] 1406 - Data too long for column 'ssex' at row 2
加上ignore关键字:
update IGNORE student set ssex = '未知性别' ,semail = '[email protected]',saddress = '广东省深圳市' where sname = '王明'

如上图所示, 跳过出错处.继续执行
如果希望删除满足条件的行中某一列的值,则直接将 set column = NULL ,即可实现
delete 语句 可以删除 1行 或 多行
同update语句一样,一定要配合where子句使用,否则将会删除整张表中所有的记录
错误:delete from tablename #删除表中所有记录
正确:delete from tablename where .... #删除表中所有符合条件的记录
例子:删除学生表中所有email为空的记录
delete from student where semail = NULL
结果 
由于 update , delete没有撤销动作,因此 生产上 如果不加上where 会很危险,未防止误操作,可以取消部分账户的权限访问
如果真的希望清空整张表, 删除所有记录可以使用 truncate table_name 进行代替,
truncate 语句 清空的本质是直接删除原来的表,再重新创建一个同结构的空表. 相对 delete from table_name(逐行删除数) 更快,更高效
十三. 创建表 操作表
13.1.创建表的方式
a:使用可视化工具 ,例如 navicat
b:使用mysql语句
使用mysql 创建表的语法格式
使用括号引起各个列,类似于 java中创建1个表对象 时,初始化各个字段
create table new_table_name (cloumn1 value_type feature, cloumn2 value_type ,feature ... PRIMARY KEY (cloumn)) ENGINE = 存储引擎
mysql语句有一个特点, 会忽略空格, 因此一条语句可以写成一个长行 也可以分成很多行,对于书写新建一个表的操作sql语句,最好是进行换行,更加直观,美观
CREATE TABLE student(
sno int NOT NULL AUTO_INCREMENT,
sname char(50) NOT NULL,
ssex char(2) NOT NULL,
semail char(50) NULL,
saddress char(50) NULL,
PRIMARY KEY (sno)
)ENGINE = InnoDB
其中
NULL 表示允许该列为空值
NOT NULL 表示不允许该列为空值
AUTO_INCREMENT 表示本列值可以自动自增
PRIMARY KEY() 表示主键为哪一列
ENGINE 设置表的存储引擎为 (一般是 InnoDB 和 MyISAM)
注意:
1.如果相同表名 已经在该数据库中存在,此时会报错,而不是覆盖旧的表(这么设计也是为了保证旧表中的数据安全)
2.NULL值不等于 空串 NULL就是没有值的意思
3.PRIMARY KEY 应当保证每个表中都设置主键, 如果使用单列作为主键,则必需保证改列值唯一, 如果使用多列做主键 , 则必需保证多列的组合值唯一,大多数情况都是使用单列作为主键
CREATE TABLE student(
...
PRIMARY KEY (sno,sname)#sno 与 sname 设置为主键
...
)
除此之外 , 主键列,其值不能为NULL ,如果某一列可以允许值为NULL ,则不能作为主键
4.AUTO_INCREMENT 自动递增
在区别学生是否唯一时,设置sno 为主键并且自增 ,因为业务仅仅需要一个不重复且唯一的值即可, 在这个表中 我并关心主键具体的值时多少,因此可以交由mysql自动生成即可!
每个表中只允许有一列设置为 自增,并且他必需被索引(例如,设置为主键)
5.DEFAULT 给定默认值, 如果在插入数据时,没有指定该列的值是多少 ,则新增的这一条件记录 的该列的值 就会设定的默认值
例如,希望新增的值默认性别为男,默认地址为广东省广州市,如果新增时传入,则使用传入的值 设定默认值语法如下:
CREATE TABLE student(
...
ssex char(2) NOT NULL DEFAULT '男',
saddress char(50) NULL DEFAULT '广东省广州市',
...
)
insert into student(sname) values('王明')
![]()
默认值 只支持常量值, 不支持 函数
6.ENGINE 引擎类型
创建新表时,如果不加上 ENGINE = value 这个语句, 则表的默认存储引擎是 InnoDB
常用的存储引擎有:
InnoDB: 支持可靠的事务,支持外键,mysql 5.6版本后 支持全文检索, 如果需要事务,则应当选择InnoDB(数据存储在磁盘中)
MyISAM:性能非常高的一种引擎. 支持全文检索,但是不支持事务 (数据存储在磁盘中)
MEMORY:功能等同于MyISAM 但由于数据存储在内存中, 速度要更快 .特别适用于临时表
存储引擎选择:
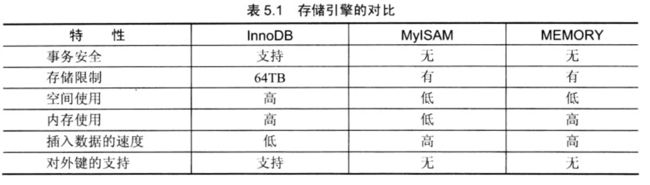
SHOW ENGINES 查看mysql 支持的所有存储引擎
注意:外键不能跨存储引擎 ,假如:当前表的存储引擎是InnoDB ,需要设置的外键所在表存储引擎为 MyISAM ,则不允许
13.2 修改表
ALTER TABLE table_name operation
1.新增一列 ALTER TABLE 表名 add 列名 列的类型
ALTER TABLE student add test_column char(10)
2.删除一列 ALTER TABLE 表名 drop column 列名
ALTER TABLE student drop column test_column
3.新增外键 新增
新增成绩表 关联学生表
CREATE TABLE score(
d_id int(10) NOT NULL AUTO_INCREMENT,
s_id int(10) NOT NULL ,
dgree decimal(10) NOT NULL,
PRIMARY KEY (d_id)
)
4.建立外键:
ALTER TABLE score
ADD CONSTRAINT fk_score_student FOREIGN KEY(s_id)
REFERENCES student(sno)
ALTER TABLE 之前,应对现有的表做备份后,再进行操作,如果删除了不该删除的列,可以做一定的弥补
13.3 删除表
DROP TABLE score #永久删除 score表
如果删除的表的某一列 被 其他表 设置为外键 ,则必需要删除关联表之后,才能删除该表
报错提示:[Err] 1217 - Cannot delete or update a parent row: a foreign key constraint fails
13.4 重命名表
RENAME TABLE table_name TO new_table_name
例如:修改score表的名称 :
RENAME TABLE score TO my_score
十四.视图
使用数据仍然是 SQL必知必会 中提供的数据
视图不是真正存在的表, 视图相当于把 SELECT 语句 查询出的结果集 存储起来,便于多次使用
14.1 为什么用视图?
1.重用SQL
2.简化复杂的SQL
3.使用表的组成部分,而不是整张表
4.保护数据,修改视图中的内容不会影响原始表中的数据
5.更改数据格式, 视图可以返回与原始表 格式不同的数据
每使用一次视图,就相当于执行一次查询,当创建了复杂的视图 或者视图嵌套较多时,会降低执行的效率
14.2 视图的规则 与 限制
1.视图名称必需唯一, 不能与别的表 和 视图同名
2.视图数量无限制
3.创建视图需要足够的权限
4.视图可进行嵌套
5.视图不能索引,也不能有关联的触发器或默认值
6.视图可以和表一起联结使用
7.ORDER BY 可以用在视图中, 单如果从该视图检索数据SELECT 中 也包含有ORDER BY , 那么该视图中的 ORDER BY 将被覆盖
14.3 创建视图
语法:
方式1:CREATE VIEW view_name AS SELECT ...
方式2:CREATE OR REPLACE VIEW AS SELECT ...如果视图不存在则创建 ,如果存在则替换
14.4 删除视图
DROP VIEW view_name
14.5 查找视图 & 视图的常用之处
使用select 检索 视图内容 与 检索表的用法完全一致
#14.5.1.利用视图简单化复杂的SQL联结
#例:查找产品id 为 TNT2的客户
select * from product_customers_view where prod_id = 'TNT2'
#14.5.2.利用视图重新格式化检索出的数据
#例如将供应商表中的供应商名称与国家 组合成一列进行显示
CREATE VIEW vend_titles AS
SELECT CONCAT(vend_name,'(',vend_country,')') AS vend_title FROM vendors
#14.5.3.利用视图过滤掉不想要的数据
#列出email地址不为空的所有的顾客信息
CREATE VIEW customer_email_list AS
select * from customers where cust_email IS NOT NULL
#在对包含where 子句的视图, 再次使用where子句时, mysql会将两次where子句自动整合
#14.5.4.视图中使用计算字段
#将每个订单的数量 , 单价 与总价显示出
CREATE VIEW orderitem_expend AS
select order_num,
quantity,
item_price,
quantity * item_price as total_price
from orderitems
14.6 视图中的内容是否可更新?
并不是所有的视图都支持更新, 当视图中包含: 分组 , 联结 ,子查询, 聚集函数 ,DISTINCT ,计算列时 ,不可以更新
也就意味着 ,只有简单的SQL单表查询语句构建出的视图,才可以使用更新; 但是正常情况下,构建视图的SQL语句,一般都不会是这种SQL语句
所以基本上视图 是不支持更新的 ,视图的主要功能是用来检索,而不是用于更新
十五.存储过程
简单理解存储过程: 它是为了以后的使用而保存的一条或者多条MySQL的语句集合,可以将其视为批文件,虽然他们的作用不仅仅是批处理;
15.1 创建简单的存储过程
一般逻辑写在 BEGIN 与 END 之间
CREATE PROCEDURE product_avg_price()
BEGIN
SELECT AVG(prod_price) as avg_price FROM products;
END;
15.2 存储过程的调用
调用时需在存储过程的名称后 加上(), 类似于java中调用方法一样
call product_avg_price()
15.3 创建带参数的存储过程
#OUT param 表示由存储过程向外传出1个值 , IN 表示传入存储过程的值 ,INOUT 表示对存储过程传入和传出
#product_price(p1,p2,p3)表示存储过程接收三个参数 ,同时必须指定参数是IN 还是 OUT 以及参数类型
#INTO param 将值保存在指定变量param中 ,一般语法为 SELECT ... INTO param
#根据订单号 检索订单总价
CREATE PROCEDURE getTotalPriceByOrderNum(
IN orderNum INT,
OUT total_price DECIMAL(8,2)
)
BEGIN
SELECT SUM( quantity * item_price)
FROM orderitems
WHERE order_num = orderNum
INTO total_price;
END;
#调用该存储过程,传递的参数必须以@开头 ,
call getTotalPriceByOrderNum(20005,@total_price);
执行后的值将存储在@total_price中, 直接从 SELECT 变量 即可获取
SELECT @total_price
15.4 删除存储过程
DROP PROCEDURE getTotalPriceByOrderNum
15.5 查看存储过程的创建语句 与 状态信息
#查看存储过程的创建语句
SHOW CREATE PROCEDURE product_avg_price
#查看所有已创建的存储过程的状态信息
SHOW PROCEDURE STATUS
15.6 书写稍复杂的存储过程
需求:根据订单号,获取订单号的总金额,并根据传递的标志,判断是否包含税额,如包含,需返回税额与订单总金额
CREATE PROCEDURE getTotalPriceAndTaxByOrderNum(
IN orderNum INT,
IN flag INT,
OUT total_price DECIMAL(8,2)
)
BEGIN
DECLARE total DECIMAL(8,2);
-- 默认税率为6%
DECLARE taxRate INT DEFAULT 6;
-- 求出不包含税额的订单总金额
SELECT SUM( quantity * item_price)
FROM orderitems
WHERE order_num = orderNum
INTO total;
-- 如果包含税额,则将总金额 += 税额
-- flag 非0 即 TRUE
IF flag THEN
SELECT total+(total*taxRate/100) INTO total;
END IF;
-- 最终将总金额赋值给参数total_price,并返回
SELECT total INTO total_price;
END;
#调用该存储过程
#含税
call getTotalPriceAndTaxByOrderNum(20005,0,@total);
SELECT @total;
#不含税
call getTotalPriceAndTaxByOrderNum(20005,1,@total);
SELECT @total;
十六. 游标
游标:是一个存储在MySQL服务器上的数据库查询,它不是一条SELECT 语句,而是被该语句检索出来的结果集.通过游标的移动,可以切换结果集
16.1 创建游标的语法
#创建游标
DECLARE cursor_name CURSOR FOR ... CREATE PROCEDURE processorders() BEGIN DECLARE ordernumbers CURSOR FOR SELECT order_nums FROM orders; END;
16.2 打开与关闭游标的语法
CREATE PROCEDURE processorders() BEGIN DECLARE ordernumbers CURSOR FOR SELECT order_nums FROM orders; #打开游标 OPEN ordernumbers; #关闭游标(此时释放游标所占用的内存资源,在使用完游标后,应当关闭游标,如果没有手动关闭游标,那么MySQL会在到达END语句后自动关闭游标) CLOSE ordernumbers; END;
上述例子仅仅是演示如何创建游标,使用 与 关闭游标. 并没有做额外的操作
16.3 使用游标数据,将游标中的数据 插入到新创建的表中
#创建存储过程 CREATE PROCEDURE processorders() BEGIN #创建Boolean标识 DECLARE done BOOLEAN DEFAULT 0; #创建 tempValue 用于接收游标中的值 DECLARE tempValue INT; #表示订单总额加税后的价格 DECLARE totalPrice DECIMAL(8,2); #创建游标 DECLARE ordernumbers CURSOR FOR SELECT order_num FROM orders; #定义游标的结束--当遍历完成时,将DONE设置为1 DECLARE CONTINUE HANDLER FOR SQLSTATE '02000' SET done = 1; #创建新表 CREATE TABLE IF NOT EXISTS ordertotals( order_num INT NOT NULL, totalPrice DECIMAL(8,2) ); #打开游标 OPEN ordernumbers; #循环取出游标中的数据 REPEAT -- 取出游标中的数据 FETCH ordernumbers INTO tempValue; #根据上一章节定义的存储过程,求出带税价格 CALL getTotalPriceAndTaxByOrderNum(tempValue,1,totalPrice); #将当前数据插入到表ordertotals中 INSERT INTO ordertotals VALUES(tempValue,totalPrice); #当done 为 true时 ,结束循环 UNTIL done END REPEAT; #关闭游标 CLOSE ordernumbers; END; #执行存储过程 CALL processorders();
#执行完毕后即可发现,数据库中新增了一个表
十七. 触发器
触发器,可以理解为 前端中的事件机制,当发生 something时 do someting
MySQL中只有以下语句执行时 可以触发 触发器:
INSERT ,DELETE , UPDATE
17.0 触发器分类
INSERT ,DELETE , UPDATE 的 BEFORE ,AFTER 即前后都可以创建一次触发器,所以每张表最多可创建6个触发器
尽管在MYSQL中只需要保证同一张表的触发器名称唯一,但是在其他DBMS 中触发器的名称在数据库中必须要保持唯一,因此建议触发器名称要保持唯一
17.1 创建触发器
a.创建触发器的四要素:
1.唯一的触发器名称
2.为哪张表新增触发器
3.触发器响应的活动(即INSERT 或 DELETE 或 UPDATE)
4.触发器何时可以执行(在处理之前还是处理之后)
b.创建触发器的语法:
CREATE TRIGGER
#创建触发器 CREATE TRIGGER insert_product AFTER INSERT ON products FOR EACH ROW SELECT NEW.prod_id;
17.2 删除触发器
#删除触发器 DROP TRIGGER insert_product
17.3 使用触发器
#使用INSERT触发器 CREATE TRIGGER insert_order AFTER INSERT ON orders FOR EACH ROW SELECT NEW.order_num; #在INSERT 触发器内部,提供一个可以引用的名为NEW的虚拟表,访问被插入的行 #测试触发器 INSERT INTO orders (order_date,cust_id) VALUES(now(),10001);
#使用DELETE触发器
未完待补充...
十八.事务处理
事务处理:可以用来维护数据库的完整性,它能保证成批的MySQL操作要么完全执行,要么完全不执行
支持事务的存储 : InnoDB
18.1事务存在与否的差别:
当前数据库中有 客户表 customers , 订单表 orders , 订单明细表 orderitems ,通过主键相互关联
当没有事务时流程是:
a.判断数据库中有没有该客户
b.如果有,则检索出客户的ID, 如果没有新增客户 同样可获取到客户ID
c.关联客户ID,新增一行记录到orders 中
d.关联order_num,新增一行记录到orderitems中
正常情况下,该流程没有问题:
假设:
在创建客户后, 新增order记录前 出现了异常,此时客户被新增,订单未被创建; 正常情况下允许,客户没有订单记录 ,这种情况不会造成什么影响
但是在新增order记录后, 新增orderitems之前出现了异常, 此时order记录已经生成, orderitems却没有生成该记录. 一条order记录生成,单没有订单明细,这是非常严重的错误,不应该出现
18.2 有事务支持时流程是:
a.判断数据库中有没有该客户
b.如果有,则检索出客户的ID, 如果没有新增客户 同样可获取到客户ID
c.关联客户ID,新增一行记录到orders 中
d.如果新增orders记录时出现了故障,则回退,整个流程就当从来没有执行过
e.关联order_num,新增一行记录到orderitems中
f.如果新增orderitems记录时出现故障,则回退
g.提交订单信息
18.3 名词介绍:
1.事务(transaction):指一组SQL语句
2.回退(rollback):指撤销SQL语句的过程
3.提交(commit):指将未存储的SQL语句结果写入数据库表中
4.保留点(savepoint):指事务处理过程中设置的临时占位符(placehodler),你可以对他回退,与回退整个事务不同,
类似于打小霸王时,有的游戏支持存档,一旦游戏失败,不会完全从头开始,而是从你的存档处继续
18.4 控制事务
18.4.1 事务的回退/回滚
下面举个简单的例子测试事务的回退/回滚
#第一次查询 存在记录 select * from ordertotals; #开始事务 START TRANSACTION; DELETE FROM order ordertotals #删除后 才是查询ordertotals 表为空 select * from ordertotals; #回滚/回退 事务 ROLLBACK; #最后再次执行检索,发现ordertotals数据恢复了 select * from ordertotals;
哪些语句支持回退?
INSERT , DELETE ,UPDATE ,不支持SELECT语句(这样做并没有意义),不能回退DROP,CREATE操作
18.4.2 事务的commit
一般的SQL语句是直接针对数据库表执行与操作的,这就是所谓的隐含提交(implicit commit),即提交操作是自动进行的
但是在事务处理块中,即事务开启后,所有的操作不会再 隐含提交 ,一切都需要明确的提交 ,即手动提交,此时需要使用 COMMIT语句
commit实例代码如下:
#开启事务 START TRANSACTION; DELETE FROM orderitems where order_num = 20011; DELETE FROM orders where order_num = 20011; #提交事务 COMMIT;
如果在commit之前出了错误, 则事务会自动回退到开启事务时的那个状态,两个删除语句都不会执行
不管是ROLLBACK(回退) 还是 COMMIT (提交) 这两者一旦执行后,事务都会自动关闭
18.4.5 使用保留点
#创建test表
CREATE TABLE test(
id INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
tname VARCHAR(10) NOT NULL
)
#开启事务 START TRANSACTION; INSERT INTO test(tname) VALUES('hello'); #创建一个保留点 SAVEPOINT insert_customer; INSERT INTO test(tname) VALUES('miss'); #回退到指定保留点 ROLLBACK TO insert_customer; INSERT INTO test(tname) VALUES('bye'); #提交事务 COMMIT; SELECT * FROM test
此时结果是 miss 这条记录没有添加进test表中 ,而第一次 与 第三次 都已成功插入;
18.4.6 更改默认提交行为
在非事务中,mysql默认对表的操作的都会自动提交, 可以通过更改autocommit 字段 为 fasle 来关闭自动自动提交,直至自动提交再次开启
#关闭自动提交 SET autocommit = 0; INSERT INTO test(tname) VALUES('cherry'); #此时通过select * 可以读到, 但是未更改autocommit 为真时,表中是不存在该记录的 SELECT * FROM test #开启自动提交 SET autocommit = 1;
十九.全球化 与 本地化
#查看支持的字符集完整列表 SHOW CHARACTER set; #查看所支持校对的完整列表 SHOW COLLATION #查看所有的字符集与校对 SHOW VARIABLES LIKE 'character%'; SHOW VARIABLES LIKE 'collation%'; #创建表时,可以更改默认的字符集与校对 CREATE TABLE test4( id int, tname VARCHAR(10) )DEFAULT CHARSET=utf8 COLLATE utf8_general_ci;
二十.安全管理
在本地测试中,一般使用的账户是root,这个账户拥有所有的权限,但是一般生产上的用户,我们最好单独给他们建立不同的账号,对账号开放不同的权限
例如:某一个用户只需要查找的权限,不希望他能删除,修改表, 那么只需要赋予其查找的权限即可.
又或者需要对某个账号的登录地点做限制 ,只允许该用户在某台主机上访问数据库
为了数据库中数据的安全,建立不同权限的账号是完全有必要的
查看当前数据库创建的所有用户:
#进入mysql数据库 use mysql; #从user表中查询 SELECT * FROM user;
用户权限的相关操作:
#查看某个用户拥有的权限 SHOW GRANTS FOR root #为某个用户增加权限 #为root用户 增加 test数据库下所有表的 SELECT 权限 GRANT SELECT ON test.* TO root
#多个权限之间用逗号隔开
GRANT SELECT,INSERT ON test.* TO root
#移除权限 REVOKE SELECT ON test.* TO root
上述仅举例了SELECT 权限 ,所有可赋予 或者 可撤销权限如下:

二十一.数据库维护
21.1 备份数据
mysql提供了命令可以导入导出数据:
#导出数据前,未保证数据完整,应当刷新当前库中的所有数据
FLUSH TABLES
#导出数据 #1.导出数据库 数据 + 结构 : mysqldump -uroot -p customer > C:\Users\Treasure\Desktop\test.dump #2.导出数据库结构: mysqldump -uroot -p -d customer > C:\Users\Treasure\Desktop\test.dump
21.2 数据库的维护
#分析表 ANALYZE TABLE orders; #检查表 CHECK TABLE orders,productnotes; #如果MyISAM检查结果发现问题, 可以使用REPAIR TABLE 来修复相应的表,这条语句不应该被经常使用,如果经常使用,则可能存在更多的问题 REPAIR TABLE productnotes
二十二.改善性能
仅列举优化的方向:
1.MySQL具有特有的硬件建议(其他DBMS也一样) , 硬件与my.ini配置文件 优化 请参阅:https://www.cnblogs.com/devinzhang/p/8192064.html
2.生产中较为关键的DBMS应该运行在自己专用服务器上
3.MySQL是用一系列默认配置,这些配置开始可能没问题,长时间后可能需要调整内存分配,缓冲区大小,参考 (1) 中的文章
4.MySQL是一个多用户多线程的DBMS,它经常执行多个任务,如果这些任务中的某一个执行缓慢,则所有的请求都会执行缓慢,如果遇到显著的性能不良的请求
则可以使用 SHOW PROCESSLIST 显示所有的活动进程(及他们的线程ID 与 执行时间) 你还可以用KILL 命令终结某个特定的进程(需管理员登录操作)
5.实现同一功能的SQL语句,可能有多种编写方式,尝试联结,子查询 找出性能最优的方案
6.使用EXPLAIN 语句让MySQL解释它将如何执行一条SELECT 语句
7.一般来说 存储过程执行的比一条条执行各个MySQL语句快得多
8.正确的使用列的数据类型也会提高性能
9.绝不要轻易检索比需要多的数据, 例如: 不要轻易使用SELECT * 除非你真的需要这么做
10.有的操作 例如 INSERT 支持一个可选的DELAYED 关键字(延迟调用) ,如果使用它 ,将把控制立即返回给调用程序,并且一旦有可能就实际执行该操作
11.在导入数据时,应该关闭自动提交,你可能还想删除索引, 在导入完成后,重建它们
12.索引是非常有必要的,可以改善数据检索的性能 , 确定索引是一件很微不足道的事情,需要分析使用的SELECT 语句以找出重复的WHERE 与 ORDER BY 子句,如果一个剪得WHERE 子句返回结果
所花时间太长,则可以断定其中使用的列(或几个列)就是需要索引的对象
13.SELECT 语句中 如果存在复杂的OR条件, 可以使用多条SELECT 语句 通过UNION 连接 ,来代替, 可以有显著的性能提升;直观的查看UNION带来的性能提升,请阅:https://blog.csdn.net/bigtree_3721/article/details/72628608
14.LIKE 很慢(需要对数据表中的每一列都进行匹配尝试),一般来说,最好使用FULLTEXT(中文的全文本检索是个问题) 而不是LIKE
15.数据库是不断变化的实体,一组优化良好的表一会可能就面目全非了,由于表的使用和内容的更改,理想的优化和配置也会发生改变.简言之,如果表结构或内容发生了改变,则之前的好的优化方案可能还要跟着变动
16.最重要的规则就是,每条规则在某些特定的条件下都会被打破. 简言之, 应该根据具体情况具体对待
写在结尾:
三篇文章如有描述或sql语句错误,欢迎各位评论中指出,批评
历时1周多终于写完完整的博客,当初的出发点是为了方便自己复习SQL知识,所以排版格式可能有些不成熟 ,不友善.后续的博客会更加注意这方面的问题 后面几个章节可能描述不够细致,如果需要更详细的了解这几张内容,可能需要查阅其他资料
这三篇博客虽然内容大多数参考<< MySQL必知必会>>,但书中有些文字表达可能不够直观,本人对这些地方进行改善,加上自己的话语进行描述,一些代码也是本人亲自书写验证可实施性. 而不是一味的照着书中的内容抄袭;
<< MySQL必知必会>> 我认为是一本非常适合SQL入门的书籍
MySQL 性能优化计划还会额外再写一篇博客, 有这方面需求的可以加个关注.