数据集文件结构
以「猫狗识别」为例
训练结果
epoch(训练次数)
training loss(训练集损失值)
validation loss(测试集损失值)
accuracy(准确率)
[epoch , training loss, validation loss, accuracy]
[ 0. 0.04955 0.02605 0.98975]
学习率寻找器(Learning rate finder)
-
学习率的核心目的:训练过程,迭代的步伐
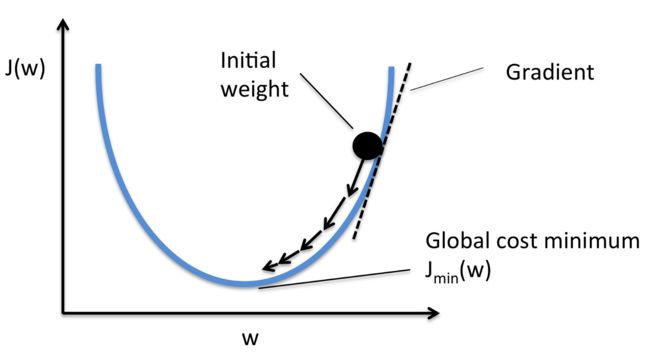 image.png
image.png - 学习率太低,寻找到碗状图形底部,耗时过长
- 学习率太高,最低点容易震荡
- 学习率寻找器
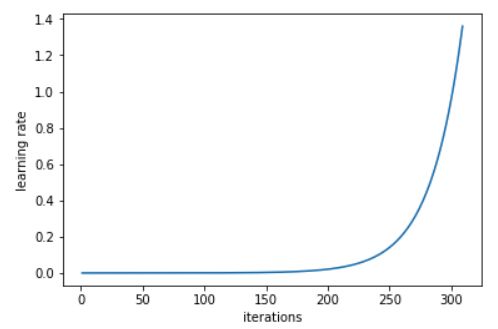
learn.lr_find会在训练完一批批尺寸(mini_batch) 之后,持续提高学习率,最终,学习率升高后,会导致损失值(loss)增大。通过观看学习率与损失值关系的折线图,我们可以选定最低损失值(loss)对应的学习率,选择上一个指数级别的学习率。(下图的例子,选择的是1e-2,也就是0.01为学习率)。
- 问题:为何不选损失值最小的底部的学习率。
-
回答:红箭头所指的是最底部的学习率,但其实它的数值较大,不太可能收拢,而更小一级别的学习率是更好的选择,它有更多的提升空间,更容易收拢。一般而言,学习率尽量小一些。
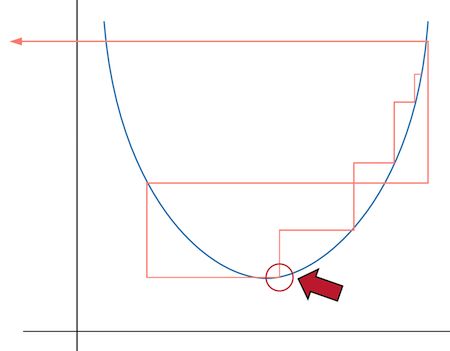 image.png
image.png
- 批尺寸(mini_batch)是我们的模型一次“学习观看”的一组图片,一般而已,mini_batch的数值会设置为64或128,意味着GPU 可以高效地利用它并行计算的优势来加速计算学习的过程。
-
Python 代码写法:

- 选对学习率,fast.ai的模块会自动选择其他的超参数。
-
learn.lr_find比其他优化器(optimizer,比如 momentum、Adam 等等)性能更佳
Overfitting 过拟合
过拟合 overfitting是指我们的模型过于拘泥与训练集图片的独特细节特征,而不是适合迁移至其他验证数据的通用特征。

数据增强
提升深度学习模型表现,最直接的办法就是——训练更多的数据。在不收集更多的数据时,可以通过数据增强(Data Rugmentation)的技术来制造更多的数据。

- 每一次训练,我们会随机的转变图片一点点。也就说,每一次训练,模型学习的图片外观,都稍有不同。
- 不同类型的图片,可以使用不同的数据增强形式。
- 水平/垂直翻转图片
- 放大/缩小
- 更改对比度/亮度...
代码示例
tfms = tfms_from_model(resnet34, sz, aug_tfms=transforms_side_on, max_zoom=1.1)
-
transform_side_on是侧面图的默认转换方式。 - 它实质上并没有创造新数据,而是让卷积神经网络从不同角度来学习图片。
训练模型
data = ImageClassifierData.from_paths(PATH, tfms=tfms)
learn = ConvLearner.pretrained(arch, data, precompute=True)
learn.fit(1e-2, 1)
- 创建 data 对象,使用数据增强,但因为 precompute 设置为True,因此数据增强没有做任何事情。
- 卷积神经网络中包含了Activation,一个Activation的含义是在此处这个特征的概率置信值(概率)的数字。
-
我们使用的是预训练的模型,它已经学习过如何识别特征了,所以在隐藏层(hidden layer),我们用的是预训练的 Activation,只训练末尾的线性部分。
 image.png
image.png - 因此,第一次训练耗时较长,它预先计算这些 Activations
- 为了使用数据增强,
learn.precompute=False
learn.precompute=False
learn.fit(1e-2, 3, cycle_len=1)
[ 0. 0.03597 0.01879 0.99365]
[ 1. 0.02605 0.01836 0.99365]
[ 2. 0.02189 0.0196 0.99316]
SDGR(stochastic gradient descent with restarts )
(文字待更新)
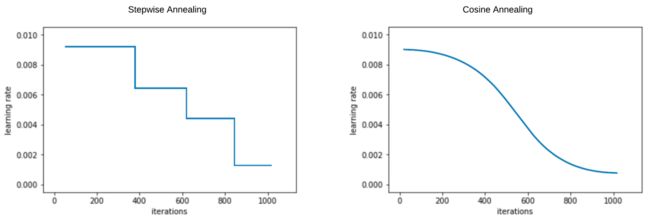
微调(Fine-Tuning)& Differential Learning Rate
learn.unfreeze()
- 冻结层是未训练的神经层,
unfreeze解冻它们,在下一次 epoch 训练时,会更新它们的参数值。 - 浅层(比如第一层,侦测对角边缘或渐变的神经层。或是是第二层,侦测曲线或者边角)的神经层,相对而言需要迭代更新的幅度较小。
- 深层的神经层需要更大幅度的更新迭代。
因此,不同深浅的神经层,我们采用不同的学习率。
lr=np.array([1e-4,1e-3,1e-2])
卷积神经基本理论
图片滤波器Image Kernels
卷积:在深度学习里,卷积一般是一个33的矩阵(Matrix),与图片的每一块33的区域相乘,并求和得到卷积的一个点。

Excel表格&可视化
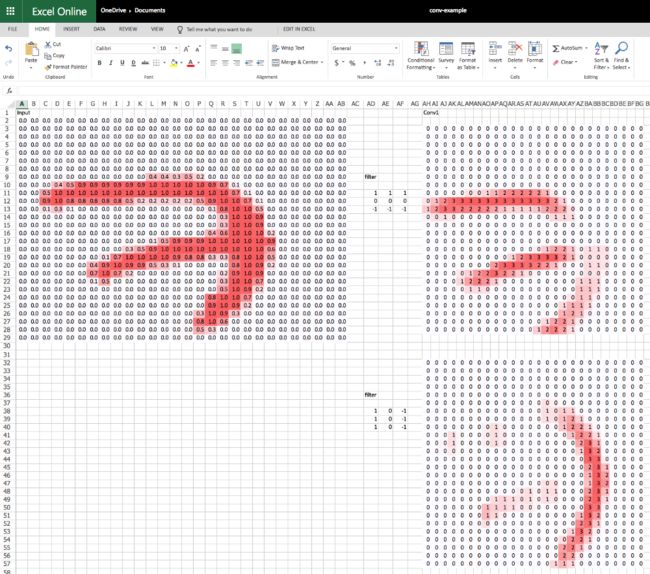
- Activation:对输入值进行线性计算,得到的数值
- Relu 函数:负值归零,正值依旧。
- 滤波器(Filter/Kernel):三维张量中的 一块 3X3 矩阵
- 张量(Tensor): 多维数组
- 最大池化(Max Pooling):一个(2,2)大小的最大池化会对分辨率进行平分切割,分别从高/宽维度。
- 全连接层(Fully Connected Layer):给每一次激活赋予权重并计算总和乘积。权重的矩阵与整个输入一样大。
- 注意:最大池化层之后,可以有许多操作。过度使用全连接层,容易造成过拟合以及减缓速度。ResNet和 ResNext 没有使用很大的全连接层。
端到端&猫狗识别
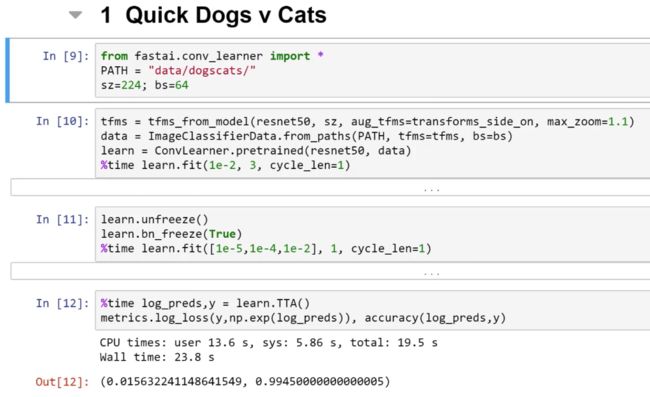
代码解析:
data = ImageClassifierData.from_paths(PATH, tfms= tfms, bs=bs, test_name='test')
-
from_paths表明子文件夹的名称便是标签。如果你的train或者valid文件夹有其他名称,你可以传入trn_name和val_name参数。 -
test_name:如果你要上传结果到 Kaggle 比赛,你需要填写测试集的文件夹名称。
learn = ConvLearner.pretrained(resnet50, data)
- 注意:我们没有设置
pre_compute=True.这是一条捷径,隐藏掉不需要重新计算的中间步骤。如果你感到迷惑,就先不管它。 - 谨记:当
pre_compute=True,数据增强不起效。
learn.unfreeze()
learn.bn_freeze(True)
%time learn.fit([1e-5, 1e-4,1e-2], 1, cycle_len=1)
-
bn_freeze如果你用更大更深的模型,像 ResNet50或者 ResNet101(任何后缀数字大于34)的模型,应用在于 ImageNet 类似的图片集(侧面图&标准物体&在200-500像素之间),你要加上这一行代码。这一知识点,会在课程第二部分讲解,“but it is causing the batch normalization moving averages to not be updated.”
如何在其他库里实现类似的模型-Keras
- 定义数据生成器
train_data_dir = f'{PATH}train'
validation_data_dir = f'{PATH}valid'
train_datagen = ImageDataGenerator(rescale=1. / 255,
shear_range=0.2, zoom_range=0.2, horizontal_flip=True)
test_datagen = ImageDataGenerator(rescale=1. / 255)
train_generator = train_datagen.flow_from_directory(train_data_dir,
target_size=(sz, sz),
batch_size=batch_size, class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_data_dir,
shuffle=False,
target_size=(sz, sz),
batch_size=batch_size, class_mode='binary')
- Keras 代码更多,需要设置的参数更多。
- Keras 要定义
DataGenerator,详细指明需要用什么样的数据增强形式及标准化。相比而言,fastai 只需要说:“ResNets50需要设置什么,就帮我搞定吧。”
base_model = ResNet50(weights='imagenet', include_top=False)
x = base_model.output
x = GlobalAveragePooling2D()(x)
x = Dense(1024, activation='relu')(x)
predictions = Dense(1, activation='sigmoid')(x)
- 在Keras 使用 ResNets50的原因是,Keras 不提供 ResNets34
- Keras里,建模需要手动设置
- 首先,你得创建一个基本的模型,然后在此基础上搭积木
model = Model(inputs=base_model.input, outputs=predictions)
for layer in base_model.layers: layer.trainable = False
model.compile(optimizer='rmsprop', loss='binary_crossentropy',
metrics=['accuracy'])
- 你还得编译模型
- 你还得历遍神经层,使用
layer.trainable=False手动冻结它们 - 你还得定义选择优化器、损失函数和评估指标
model.fit_generator(train_generator, train_generator.n//batch_size,
epochs=3, workers=4, validation_data=validation_generator,
validation_steps=validation_generator.n // batch_size)
- worker:使用多少处理器
- Keras需要知道一次 epoch 有多少 batch
split_at = 140
for layer in model.layers[:split_at]: layer.trainable = False
for layer in model.layers[split_at:]: layer.trainable = True
model.compile(optimizer='rmsprop', loss='binary_crossentropy',
metrics=['accuracy'])
%%time model.fit_generator(train_generator,
train_generator.n // batch_size, epochs=1, workers=3,
validation_data=validation_generator,
validation_steps=validation_generator.n // batch_size)
- Pytorch如果你想部署模型到移动端,Pytorch 还不成熟
- Tensorflow如果你想把本课程所学,迁移到这个框架,在 Keras 上工作量更大,未来可能会开发 TensorFlow 框架的 fastai
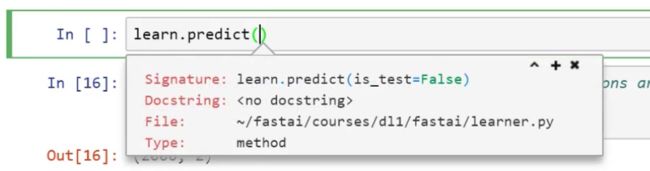
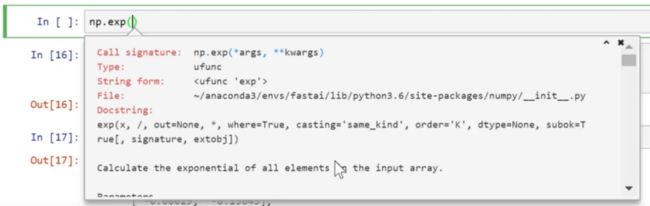
Jupyter NoteBook 函数技巧
F-Score
Instead of accuacy, we used F-beta for this notebook — it is a way of weighing false negatives and false positives. The reason we are using it is because this particular Kaggle competition wants to use it. Take a look at planet.py to see how you can create your own metrics function. This is what gets printed out at the end [ 0\. 0.08932 0.08218 **0.9324**]
The F-beta score is the weighted harmonic mean of precision and recall, reaching its optimal value at 1 and its worst value at 0.
To be continue......未完待续
参考资料
Deep Learning 2: Part 1 Lesson 2
TimeLog
2019.1.11 0.5h