ARTS学习打卡--第四周
Leetcode:
1051. Height Checker
原题:Students are asked to stand in non-decreasing order of heights for an annual photo.
Return the minimum number of students not standing in the right positions. (This is the number of students that must move in order for all students to be standing in non-decreasing order of height.)
解释:一个队伍的学生需要按照从低到高进行排序,找出这个队伍中至少要移动几个人,才能形成从低到高的队伍。
思路:把原本无序的队伍排成有序,形成一个新的有序序列。然后在各个位置与无序的序列进行比较,不相同的次数就是至少移动的人数。
class Solution {
public:
int heightChecker(vector& heights) {
vectorB;
int length = heights.size();
B=heights;
sort(B.begin(),B.end());
int ans=0;
for(int i=0;i
Review
最近在medium上阅读了老外写的一篇介绍机器学习的文章。
现将整体内容叙述给你。你也可以自行查看原文:链接(需要梯子)。
https://medium.com/@ageitgey/machine-learning-is-fun-80ea3ec3c471
机器学习指的是你给机器一些数据,机器可以通过一些通用的算法告诉你一些你感兴趣的事情。
机器学习可以分为两类:监督学习和无监督学习。为便于理解,可以举个例子。
假设你是一个房地产经纪人,当你知道一套房子的信息(房子面积、卧室个数、地理位置)后,可以估计房子的价格。你手上有许多相关交易的信息。
由于业务的发展,你手头的房源信息越来越多,一个人开始忙不过来。于是你打算找一个人来帮你。但是这个新手不可能像你这么有经验,于是你打算将你的经验传授给他。对于有监督学习来说,你根据以往的经验,制作了一张房子信息估计表,里面有许多相关的房子信息、以及对应的房子价格信息。你将这张表交给新手,期望他能够学习经验并对新的房源信息做出价格估计。一个学习能力强的人能够很快发现表格中的规律,并将新规律用于新的房源价格预测,取得了很好的结果。而一个学习能力弱的人无法从表格中发现规律,对于新的房源信息,预测结果与实际偏差很大。
这是不是有点像小学时候的找规律。给你几个数字,中间缺失了对应的符号,要求能够代入相关符号,使得左边的运算结果等于右边。而机器学习,就是给定机器一堆数据后,让机器从中找出隐含的规律。并对新的数据做出判断(如房价预测或数字分类)。
而对于无监督学习来说,给的表格中只含有房源信息,没有房源的价格信息。你希望新手能够从中学到规律。学习能力强的新手从新的表格中发现:一些学习能力强的人就发现,对于交易成功的订单,在郊区的订单往往房间面积比较大。在城区的订单往往住房面积比较小。同时出现了一些偏离大部分点范围的离散点。这部分买家可能喜欢买面积很大的房子,可能是潜在的重要顾客。
那么,如果学习规律呢?你需要对各种信息进行量化。一种很简单的方法就是,你对每个房源信息,将面积*1.0+卧室个数*1.0+位置(郊区5000,城区10000)*1.0的结果作为最后的价格。显然,这样算出来的结果肯定与实际情况相差很大。因此,对每个指标不断地进行权重调整,尝试各种可能的数字组合,使得计算结果与实际结果相差最小,这样就完成了学习的过程。
而机器学习要做的,就是将新人要做的工作,让机器进行完成。即让机器实现对于数据集的规律发现以及新数据集的预测工作。
下面进行头脑风暴
“尝试各种可能的数字组合”这步是如何做到的呢?我们可以定义一个函数用来评价预测的好坏。
如果对含有两个参数的函数进行大量取值,可以得到如下的变量关系示意图。
 来源: Adam Geitgey, Machine Learning is Fun!
来源: Adam Geitgey, Machine Learning is Fun!
 来源: Adam Geitgey, Machine Learning is Fun!
来源: Adam Geitgey, Machine Learning is Fun!
我们想要从当前点到达最优的底部点,只需要不断地进行权重调整即可。根据高等数学的知识可知,一个函数沿着梯度的方向变化最快,因此,我们只需要将权重按照梯度方向进行调整即可到达我们的目标。
而在实际过程中,会出现一些问题:模型在给的数据集上效果很好,但是在新的数据集上预测效果很差,我们称之为过拟合。针对这个问题,许多学者都提出了相关的解决方案。
对于机器学习的思考
看到这,你可能会以为机器学习可以完成任何问题,只要你提供了数据,机器就可以绘制出完美拟合这些数据的曲线。但是要记住一点,只有当你给出的数据对于问题来说是可解的,机器才能解决这个问题。
最后,作者给出了一些学习机器学习的方式。
总结
我觉得这篇文章写得很好,将机器学习这个专业名词用几个实际的实例来具体说明,能够让人快速明白机器学习的本质。
Tips
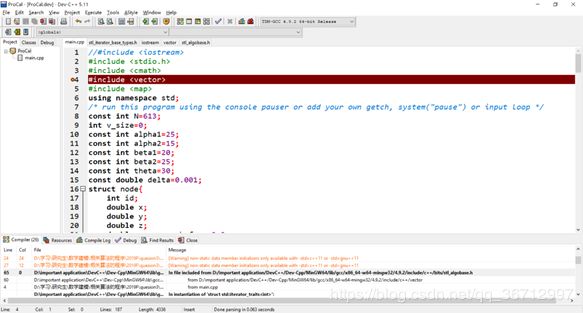
最近在用C语言写代码的时候,编译后发现了一个之前从来都没见到过的错误:[Error] 'int' is not a class, struct, or union type。错误指向了include语句所在的位置(见下图)。这让我百思不得其解,头文件怎么可能出错呢?因为找不到错误,只能将代码进行肢解,一个一个地去掉原本写的函数。结果发现删掉我自己写的一个用来计算两点之间距离的distance函数后,错误消失了。通过百度可以知道,原来C语言内部也有个叫做distance函数,在头文件
Share
计算机图形学能够将实际的事物通过计算机进行绘制与仿真。并且计算机图形学在计算机辅助设计、仿真设计等方面得到了广泛的运用。
在笛卡尔坐标系中,我们很方便地表示直线,但是在计算机中,坐标的值只能是整数,是离散的,无法做到连续的直线,只能通过一个个的像素点去逼近连续的直线。因此,要想在计算机上画直线,必须先把直线的方程确定,然后用一系列在直线附近的点进行近似。
直线的生成算法
最简单的一个想法就是给定两个点后,求解出直线的斜率k和截距b。然后利用y=kx+b代入计算y的值。
但是这样做有个问题,就是每次求y,都要进行乘法运算。乘法运算比较耗时,能否将乘法运算转化为加法运算呢?答案是肯定的。
我们可以利用下列迭代公式进行转换。


利用上述迭代式可以快速计算y的坐标值(对上述值进行四舍五入取整,因为坐标肯定是整数)。
虽然上述算法能够将乘法运算转化为加法运算,但是存在一个问题,比如在x=5处,正确的y值是6.2,但是计算得到的y是6.8(四舍五入后取7)。可以看到,这个点最正确的值应该是6才对。可以发现,该算法由于误差的积累,会导致计算值偏离实际值。
因此,有学者又提出了新的直线生成算法—Bresenham算法。
当0 另外还有中点直线生成算法,通过yk与yk+1的中点与实际点之间的关系来判断选择哪个点(对比Bresenham算法需要两个点,中点直线生成算法只需要一个点)。 至于具体的画点函数,可以调用openGL中的setpixel(x,y,color)函数画点。