中文语句情感分类系统的设计与实现
今日翻出了在毕业时候写的毕业设计,是一个稍微细腻一点的情感分类系统,大家可以看一下。未经许可,禁止商业转载。
相关资源下载地址:【百度网盘(218 MB (229,225,735 字节))】提取码:q0xq
环境如下(迫真):
Package Version
--------------------------------
attrs 19.1.0
backcall 0.1.0
bleach 1.5.0
certifi 2019.3.9
chardet 3.0.4
colorama 0.4.1
decorator 4.4.0
defusedxml 0.5.0
entrypoints 0.3
enum34 1.1.6
h5py 2.9.0
html5lib 0.9999999
ipykernel 5.1.0
ipython 7.3.0
ipython-genutils 0.2.0
ipywidgets 7.4.2
jedi 0.13.3
jieba 0.39
Jinja2 2.10
jsonschema 3.0.1
jupyter 1.0.0
jupyter-client 5.2.4
jupyter-console 6.0.0
jupyter-core 4.4.0
Keras 2.1.2
Keras-Applications 1.0.7
Keras-Preprocessing 1.0.9
Markdown 3.0.1
MarkupSafe 1.1.1
mistune 0.8.4
nbconvert 5.4.1
nbformat 4.4.0
notebook 5.7.6
numpy 1.12.1
pandocfilters 1.4.2
parso 0.3.4
pickleshare 0.7.5
pip 19.0.3
prometheus-client 0.6.0
prompt-toolkit 2.0.9
protobuf 3.7.0
Pygments 2.3.1
pyrsistent 0.14.11
python-dateutil 2.8.0
pywinpty 0.5.5
PyYAML 5.1
pyzmq 18.0.1
qtconsole 4.4.3
scipy 1.2.1
Send2Trash 1.5.0
setuptools 40.8.0
six 1.12.0
tensorflow-gpu 1.4.0
tensorflow-tensorboard 0.4.0
terminado 0.8.1
testpath 0.4.2
tornado 6.0.1
traitlets 4.3.2
wcwidth 0.1.7
Werkzeug 0.14.1
wheel 0.33.1
widgetsnbextension 3.4.2
wincertstore 0.2
本文对深度学习在自然语言处理上的应用进行了研究与设计。自互联网的普及以来,人们越来越多地在互联网上表达自己的观点、情感与见解,这样产生了大量的带有个人情感的文本信息。本文使用了深度学习的方式,对互联网上的文本的情感进行了分类系统的设计,研究内容有:
-
解决低内存设备使用大型词嵌入造成的内存资源不足的问题;
-
对文本情感分类成7大类21小类,使用切片神经网络(Sliced Recurrent Neural Networks,SRNN)对文本进行分析,训练出基于SRNN的分类模型,再使用该分类器对互联网的文本进行分类。
关键词:深度学习,情感分析,情感分类
文章目录
- @[toc]
- 第1章 绪论
- 1.1 研究背景
- 1.2 研究意义
- 1.3 国内外相关研究现状概况
- 1.4 深度学习在情感分析上的应用
- 第2章 模型理论
- 2.1 标准RNN模型
- 2.2 标准RNN单元
- 2.3 标准RNN单元变体:长短时记忆(Long Short-Term Memory ,LSTM)
- 2.3.1 遗忘门(Forget gate)
- 2.3.2 更新门(Update gate)
- 2.3.3 更新单元(Updating the cell)
- 2.3.4 输出门(Output gate)
- 2.4 LSTM变体:门控循环单元GRU
- 2.5 切片循环神经网络(Sliced Recurrent Neural Networks,SRNN)
- 2.5.1 SRNN结构
- 2.5.2 数据分类
- 2.5.3 损失函数
- 2.6 情感分类
- 第3章 项目设计
- 3.1 数据预处理
- 3.1.1 分词
- 3.1.2 去除无关及特殊字符
- 3.1.3 Embedding
- 3.2 数据集处理
- 3.2.1 数据集的构建
- 3.2.2 打乱数据集
- 3.2.3 数据集的分配
- 3.2.4 分词器
- 3.2.5 文本填充
- 3.2.6 句子分割
- 3.3 词嵌入的加载
- 3.4 进度条
- 3.5 模型构建
- 3.6 编译与训练
- 3.7 加载训练好的模型
- 3.8模型训练与观测
- 3.8.1 模型的训练
- 3.8.2 模型的观测
- 第4章 总结
- 参考文献
- 致谢
文章目录
- @[toc]
- 第1章 绪论
- 1.1 研究背景
- 1.2 研究意义
- 1.3 国内外相关研究现状概况
- 1.4 深度学习在情感分析上的应用
- 第2章 模型理论
- 2.1 标准RNN模型
- 2.2 标准RNN单元
- 2.3 标准RNN单元变体:长短时记忆(Long Short-Term Memory ,LSTM)
- 2.3.1 遗忘门(Forget gate)
- 2.3.2 更新门(Update gate)
- 2.3.3 更新单元(Updating the cell)
- 2.3.4 输出门(Output gate)
- 2.4 LSTM变体:门控循环单元GRU
- 2.5 切片循环神经网络(Sliced Recurrent Neural Networks,SRNN)
- 2.5.1 SRNN结构
- 2.5.2 数据分类
- 2.5.3 损失函数
- 2.6 情感分类
- 第3章 项目设计
- 3.1 数据预处理
- 3.1.1 分词
- 3.1.2 去除无关及特殊字符
- 3.1.3 Embedding
- 3.2 数据集处理
- 3.2.1 数据集的构建
- 3.2.2 打乱数据集
- 3.2.3 数据集的分配
- 3.2.4 分词器
- 3.2.5 文本填充
- 3.2.6 句子分割
- 3.3 词嵌入的加载
- 3.4 进度条
- 3.5 模型构建
- 3.6 编译与训练
- 3.7 加载训练好的模型
- 3.8模型训练与观测
- 3.8.1 模型的训练
- 3.8.2 模型的观测
- 第4章 总结
- 参考文献
- 致谢
第1章 绪论
1.1 研究背景
自2004年起,Web2.0得以迅猛发展,随着科学技术的迅猛发展与计算机的快速更新换代,社交平台也逐渐涌现并开始发展。各个社交平台把整个世界缩小到了一个个文本框内,用户在各个社交平台上表达自己的观点、发表自己的意见,在互联网上抒发自己的情感也成为了用户的表达方式之一。
知乎、微博、豆瓣、推特、脸书、论坛空间等等各类在线社交的平台使得用户能够相互关注并发表自己的意见或者情感;淘宝、京东、亚马逊等各类电子商务平台也允许用户在商品下发表自己对商品的评论;除此之外,QQ、微信、Skype等各类实时聊天平台也承担着拉近空间距离的重任。对于非实时社交类平台而言,需要快速找到违反法律法规的不恰当言论并予以删除或对用户进行封禁,还需要屏蔽一些敏感词;对于电子商务平台而言,客户对某一商品的评论意见或建议有助于提升其产品的品质、售前售后服务的效果。考虑到较为传统的人工分析的低下效率,传统的手段已经没有办法满足现在快速发展的行业需求,所以现在越来越多的人开始使用自然语言处理这一近几年才得以快速发展的技术对互联网上的大规模文本来进行分析其包含的各类情感。
1.2 研究意义
用户在各个平台上表达的观点的同时也留下了大量的文本数据,这些文字会无形地围绕在用户周围,无形的影响人们的选择:人们会根据猫眼、豆瓣上的评分、评价作为参考来选择是否去电影院观看一部电影;根据在电子商务平台上的商品的购买过的人的评价来考虑是否购买这一个商品;根据某一社交平台上某一人的言论、观点来判断一个人的性格、爱好等。因此,这些文本数据对网络舆情、购买意愿、性格爱好的分析有着巨大的价值,收集这些数据并加以分析对舆情监控、产品的销售以及用户画像有着重要作用。
目前,由于现在互联网上文本信息数据量极为庞大且句式语法不规范,要冲这些数据中获取其真正的情感是非常困难的,但若仅仅依靠人工方式来判断,这是一件费时费力的事情,那么就需要计算机的帮助。使用自然语言处理这一方式是解决这一问题的有效途径之一,通过这一技术分析文本包含的情感倾向,从而判断信息发布者的主观情感,杂乱无章的海量数据就被归纳整理,成为了可直接使用的有价值的数据。
1.3 国内外相关研究现状概况
情感分析是由BoPang[1]等人于2002年提出的,情感分析是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程[2]。基于机器学习的方法是比较传统的学习方法,使用较为广泛的有支持向量机、贝叶斯、梯度下降等方法,其优点在于机器学习具有对特征有较好的建模能力,其缺点在于选取有效特征比较困难与人工标注训练数据的不足将会导致分类系统的性能;基于情感词典的方法的优点在于可以人工编写高质量的情感词典,记录词语或者短语的情感倾向和强度信息对文本进行分类,但是其缺点是情感词典是有限的,不同语境下的词语所涵盖的意义与情感很有可能是不一样的,尤其是在信息大爆炸下的今天,新兴词语很有可能会影响该方法的性能[3]。
目前而言,更好更快的计算资源、更多更大更有效的数据使得深度学习得以快速发展,深度学习是机器学习领域的分支之一,其神经网络是模拟人脑学习机制的黑盒模型。深度学习的技术在现有计算机强大的计算能力下不断成熟,并在图像、语音、文本分析等各个不同的领域取得了好成绩。卷积神经网络(Convolutional
Neural Network,CNN)、循环神经网络(Recurrent NeuralNetworks,RNN)、深度置信网络(Deep BeliefNet,DBN)等等各类神经网络表现十分优异,其原因在于这些网络能够把各类特征提取并由浅层向深层传递,从而最终获得高表达能力,它不仅仅能够解决情感分析的问题,还能够引用于信息检索、语义涵盖等等各类问题。
1.4 深度学习在情感分析上的应用
使用词袋(Bag ofWords,BOW)的方法进行文本的表示[4]这一方法是一个广泛使用的方法,其使用独热编码(One-hotRepresentation)的模型有词顺序特征的丢失、词语在语境上的忽视、数据的稀疏的问题。为了解决此问题,1986年Rumelhart等人提出了词语分布式[5],2006年Bengio等人使用了神经网络训练词语分布式,得到了其向量表示[6],Socher等人提出根据句子的语法分析,使用矩阵-向量操作对词向量根据语法分析树获得整个文本的向量表示[7],2010年,MikolovT[8]等人在Google发布Word2vec工具,该工具能够将词汇表达为空间词向量,后来搭建了基于RNN的一种语言模型,该模型能够利用上下文信息使得最终结果变得更好,2014年,YoonKim[9]使用了CNN模型处理情感分类,通过对CNN模型进行改进、使用静态向量取得了良好的效果。同年,梁军[10]使用了深度学习方法中的NN-LSTM模型分析了中文微博的文本数据中的情感倾向,取得了不错的效果。刘龙飞[11]使用了词向量在COAE2014数据集上取得了较高的准确率。
尽管现在的很多方法有着很好的正确率,但是对于中文文本的情感分析方面,传统的方法已不能满足现有的需要,因此,本文采用切片循环神经网络(SlicedRecurrent Neural Networks,SRNN)来对文本进行情感分析。
第2章 模型理论
2.1 标准RNN模型
循环神经网络(RNN)模型在处理序列数据上是高效的,在此模型中有着一些特殊的信号决定了此模型是否需要记住上下文信息。他们可以从上一个时间步获取信息并传递到下一个时间步中,即它们可以获知上下文信息。下面是一个标准循环神经网络的图,在这里使用的是Tx=Ty ,本文将会依据此通用模型实现SRNN模型。

其中:
-
上标 [ l ] \lbrack l\rbrack [l]表示第 l l l层,如: a [ 4 ] a^{\lbrack 4\rbrack} a[4]表示第 4 4 4层的激活值, W [ 5 ] W^{\lbrack 5\rbrack} W[5]与 b [ 5 ] b^{\lbrack 5\rbrack} b[5]是第 5 5 5层的参数。
-
上标 ( i ) (i) (i)表示第 i i i个样本,如: x ( i ) x^{(i)} x(i)表示第 i i i个输入的样本。
-
上标 < t > < t > <t>表示第 t t t个时间步,如: x < t > x^{< t >} x<t>表示输入数据 x x x的第 t t t个时间步, x ( i ) < t > x^{(i) < t >} x(i)<t>表示输入输入数据 x x x的第 i i i个样本的第 t t t个时间步。
-
下标 i i i表示向量的第 i i i项,如: a i [ l ] a_{i}^{\lbrack l\rbrack} ai[l]表示 l l l层中的第 i i i个项的激活值。
2.2 标准RNN单元
循环神经网络可以看作是RNN模块的多个组合链接,图2.2描述了单个循环神经网络单元的单个时间步的计算过程。

当前的输入数据 x ⟨ t ⟩ x^{\langle t\rangle} x⟨t⟩ 与 a ⟨ t − 1 ⟩ a^{\langle t - 1\rangle} a⟨t−1⟩(包含过去信息的激活值), 通过计算后输出 a ⟨ t ⟩ a^{\langle t\rangle} a⟨t⟩传递给下一个RNN单元,作为下一个基本单元的部分输入数据,每一个RNN单元都可以作为 y ⟨ t ⟩ y^{\langle t\rangle} y⟨t⟩,一般而言,最后一个RNN单元作为预测单元。其关键公式计算如下:
a ⟨ t ⟩ = t a n h ( W aa a ⟨ t − 1 ⟩ + W ax x ⟨ t ⟩ + b a ) a^{\langle t\rangle} = tanh(W_{\text{aa}}a^{\langle t - 1\rangle} + W_{\text{ax}}x^{\langle t\rangle} + b_{a}) a⟨t⟩=tanh(Waaa⟨t−1⟩+Waxx⟨t⟩+ba)
y ^ ⟨ t ⟩ = softmax ( W ya a ⟨ t ⟩ + b y ) {\hat{y}}^{\langle t\rangle} = \text{softmax}(W_{\text{ya}}a^{\langle t\rangle} + b_{y}) y^⟨t⟩=softmax(Wyaa⟨t⟩+by)
2.3 标准RNN单元变体:长短时记忆(Long Short-Term Memory ,LSTM)
LSTM模型是用来解决标准RNN对长时间依赖的(Long TermDependency)的问题,因为标准RNN在长时间线上的推理与判断上有着较差的性能,特此引入LSTM这一概念。LSTM的核心思想是加入“门”控,“门”是可以学习的参数,学习后网络就可以知道在什么时候“记住”一些信息,在什么时候“遗忘”一些信息,LSTM的示意图如下:

2.3.1 遗忘门(Forget gate)
假如我们正在阅读一篇英文文章,使用LSTM来记忆其语法与词汇结构,比如一段文章的主语从单数变为复数,那么LSTM就会将之前的单数形式的主语更改为复数形式的主语,在LSTM中,遗忘门是这样更新数据的:
Γ f ⟨ t ⟩ = σ ( W f [ a ⟨ t − 1 ⟩ , x ⟨ t ⟩ ] + b f ) \Gamma_{f}^{\langle t\rangle} = \sigma(W_{f}\lbrack a^{\langle t - 1\rangle},x^{\langle t\rangle}\rbrack + b_{f}) Γf⟨t⟩=σ(Wf[a⟨t−1⟩,x⟨t⟩]+bf)
其中, W f W_{f} Wf是控制遗忘门的权值,把 a ⟨ t − 1 ⟩ , x ⟨ t ⟩ a^{\langle t - 1\rangle},x^{\langle t\rangle} a⟨t−1⟩,x⟨t⟩进行连接转变为 [ a ⟨ t − 1 ⟩ , x ⟨ t ⟩ ] \lbrack a^{\langle t - 1\rangle},x^{\langle t\rangle}\rbrack [a⟨t−1⟩,x⟨t⟩],乘以 W f W_{f} Wf,得到矢量值 Γ f ⟨ t ⟩ \Gamma_{f}^{\langle t\rangle} Γf⟨t⟩,其值在 0 0 0与 1 1 1之间。遗忘门向量 Γ f ⟨ t ⟩ \Gamma_{f}^{\langle t\rangle} Γf⟨t⟩将与上一个单元状态 c ⟨ t − 1 ⟩ c^{\langle t - 1\rangle} c⟨t−1⟩进行矩阵相乘,如果 Γ f ⟨ t ⟩ \Gamma_{f}^{\langle t\rangle} Γf⟨t⟩的值是 0 0 0(或 ≈ 0 \approx 0 ≈0),则LSTM需要删除对应的信息,如果其中有为 1 1 1的值,那么LSTM将保留该信息。
2.3.2 更新门(Update gate)
LSTM在“忘记”主语是单数,那么就会一种方法来更新其值以表示现在的主语是复数,更新门的计算方式如下:
Γ u ⟨ t ⟩ = σ ( W u [ a ⟨ t − 1 ⟩ , x ⟨ t ⟩ ] + b u ) \Gamma_{u}^{\langle t\rangle} = \sigma(W_{u}\lbrack a^{\langle t - 1\rangle},x^{\langle t\rangle}\rbrack + b_{u}) Γu⟨t⟩=σ(Wu[a⟨t−1⟩,x⟨t⟩]+bu)
与遗忘门 Γ f ⟨ t ⟩ \Gamma_{f}^{\langle t\rangle} Γf⟨t⟩相似的是, Γ u ⟨ t ⟩ \Gamma_{u}^{\langle t\rangle} Γu⟨t⟩向量的值在 0 0 0与 1 1 1之间,为了计算 c ⟨ t ⟩ c^{\langle t\rangle} c⟨t⟩,它会与 c ~ ⟨ t ⟩ {\tilde{c}}^{\langle t\rangle} c~⟨t⟩相乘。
2.3.3 更新单元(Updating the cell)
为了要更新信息,需要创建 c ~ ⟨ t ⟩ {\tilde{c}}^{\langle t\rangle} c~⟨t⟩作为新的信息添加到单元之前的状态中。使用的公式是:
c ~ ⟨ t ⟩ = t a n h ( W c [ a ⟨ t − 1 ⟩ , x ⟨ t ⟩ ] + b c ) {\tilde{c}}^{\langle t\rangle} = tanh(W_{c}\lbrack a^{\langle t - 1\rangle},x^{\langle t\rangle}\rbrack + b_{c}) c~⟨t⟩=tanh(Wc[a⟨t−1⟩,x⟨t⟩]+bc)
最后,单元的新状态是:
c ⟨ t ⟩ = Γ f ⟨ t ⟩ ∗ c ⟨ t − 1 ⟩ + Γ u ⟨ t ⟩ ∗ c ~ ⟨ t ⟩ c^{\langle t\rangle} = \Gamma_{f}^{\langle t\rangle}*c^{\langle t - 1\rangle} + \Gamma_{u}^{\langle t\rangle}*{\tilde{c}}^{\langle t\rangle} c⟨t⟩=Γf⟨t⟩∗c⟨t−1⟩+Γu⟨t⟩∗c~⟨t⟩
2.3.4 输出门(Output gate)
为了决定使用哪种输出,将使用以下两个公式:
Γ o ⟨ t ⟩ = σ ( W o [ a ⟨ t − 1 ⟩ , x ⟨ t ⟩ ] + b o ) \Gamma_{o}^{\left\langle t \right\rangle} = \sigma\left( W_{o}\left\lbrack a^{\left\langle t - 1 \right\rangle},x^{\left\langle t \right\rangle} \right\rbrack + b_{o} \right) Γo⟨t⟩=σ(Wo[a⟨t−1⟩,x⟨t⟩]+bo)
a ⟨ t ⟩ = Γ o ⟨ t ⟩ ∗ t a n h ( c ⟨ t ⟩ ) a^{\langle t\rangle} = \Gamma_{o}^{\langle t\rangle}*tanh(c^{\langle t\rangle}) a⟨t⟩=Γo⟨t⟩∗tanh(c⟨t⟩)
2.4 LSTM变体:门控循环单元GRU
GRU作为长短时记忆(Long Short-TermMemory,LSTM)的一种变体,将LSTM中的遗忘门和输入门进行了整合,变成了更新门,在此基础上还把细胞状态和隐藏状态也进行了整合,除此之外还有一些其他的小改动,最终的模型比标准的LSTM 模型要简单,也是一种非常流行的变体。
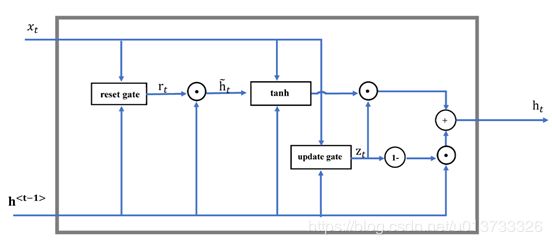
其关键方程如下:
c ~ ⟨ t ⟩ = tanh ( W c [ Γ f ∗ c ⟨ t − 1 ⟩ , x ⟨ t ⟩ ] + b c ) {\tilde{c}}^{\left\langle t \right\rangle} = \tanh\left( W_{c}\left\lbrack \Gamma_{f}*c^{\left\langle t - 1 \right\rangle},x^{\left\langle t \right\rangle} \right\rbrack + b_{c} \right) c~⟨t⟩=tanh(Wc[Γf∗c⟨t−1⟩,x⟨t⟩]+bc)
Γ u = σ ( W u [ c ⟨ t − 1 ⟩ , x ⟨ t ⟩ ] + b u \Gamma_{u} = \sigma(W_{u}\lbrack c^{\left\langle t - 1 \right\rangle},x^{\left\langle t \right\rangle}\rbrack + b_{u} Γu=σ(Wu[c⟨t−1⟩,x⟨t⟩]+bu
Γ r = σ ( W r [ c ⟨ t − 1 ⟩ , x ⟨ t ⟩ ] + b r \Gamma_{r} = \sigma(W_{r}\lbrack c^{\left\langle t - 1 \right\rangle},x^{\left\langle t \right\rangle}\rbrack + b_{r} Γr=σ(Wr[c⟨t−1⟩,x⟨t⟩]+br
c ⟨ t ⟩ = Γ u ∗ c ~ ⟨ t ⟩ + ( 1 − Γ u ) ∗ c ⟨ t − 1 ⟩ c^{\left\langle t \right\rangle} = \Gamma_{u}*{\tilde{c}}^{\left\langle t \right\rangle} + \left( 1 - \Gamma_{u} \right)*c^{\left\langle t - 1 \right\rangle} c⟨t⟩=Γu∗c~⟨t⟩+(1−Γu)∗c⟨t−1⟩
a ⟨ t ⟩ = c ⟨ t ⟩ a^{\langle t\rangle} = c^{\langle t\rangle} a⟨t⟩=c⟨t⟩
2.5 切片循环神经网络(Sliced Recurrent Neural Networks,SRNN)
传统的循环神经网络在长序列下的缺陷表现在每一个单元的输入都需要等待前一个单元的输出,输入的序列越长,等待的时间越长,这大大限制了循环神经网络的速度。为了解决这一问题,上海交通大学研究人员Zeping
Yu[12]等人构建了切片循环神经网络(SRNN),这一模型可将一段序列分割多个子序列来进行计算,在使用线性函数作为激活函数时时,标准RNN模型即SRNN模型的一种特殊结构,这一方法打破了传统的计算方式,实现了循环神经网络的并行计算,其结构如下:
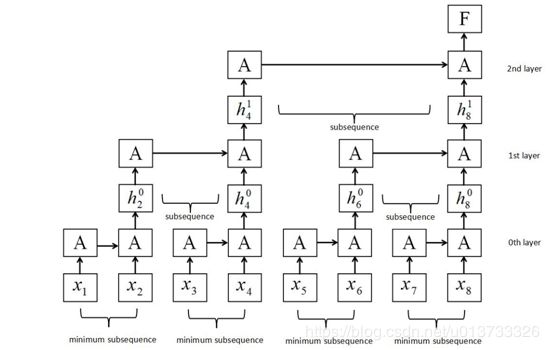
2.5.1 SRNN结构
SRNN将输入的一段序列分割为几个等长度的最小序列,循环单元在每层的最小序列上同时进行运算,信息在层与层之间进行传递,如果输入数据序列X的长度为T,那么:
X = [ x 1 , x 2 , x 3 , ⋯ , x T ] X = \lbrack x_{1},x_{2},x_{3},\cdots,x_{T}\rbrack X=[x1,x2,x3,⋯,xT]
其中, x x x为每一步的输入,然后将序列X进行拆分,拆分为 n n n个等长的子序列,那么每个子序列 N N N的长度就可以表示为 t = T n t = \frac{T}{n} t=nT,因此,整个序列X可以表示为:
X = [ N 1 , N 2 , N 3 , ⋯ , N n ] X = \left\lbrack N_{1},N_{2},N_{3},\cdots,N_{n} \right\rbrack X=[N1,N2,N3,⋯,Nn]
子序列 N p N_{p} Np就可以表示为:
N p = [ x ( p − 1 ) × t + 1 , x ( p − 1 ) × t + 2 , x ( p − 1 ) × t + 3 , ⋯ , x ( p − 1 ) × t ] N_{p} = \lbrack x_{\left( p - 1 \right) \times t + 1},x_{\left( p - 1 \right) \times t + 2},x_{\left( p - 1 \right) \times t + 3},\cdots,x_{\left( p - 1 \right) \times t}\rbrack Np=[x(p−1)×t+1,x(p−1)×t+2,x(p−1)×t+3,⋯,x(p−1)×t]
重复拆分,再将每个子序列N拆分为 n n n个等长的子序列, k k k次后,最小子序列长度满足设定值(如图6中的第0层)。经过了 k k k次分割后,得到了$k
- 1$层网络,在此网络中第0层的序列长度为:
l 0 = T n k l_{0} = \frac{T}{n^{k}} l0=nkT
因为每次分割都是按照 n n n块来分割,所以 l p l_{p} lp的子序列长度计算方法为:
l p = n l_{p} = n lp=n
在 l 0 l_{0} l0中最小子序列的条目数计算方法为:
S 0 = n k S_{0} = n^{k} S0=nk
同理, l p l_{p} lp的子序列数量计算方法为:
S p = n k − p S_{p} = n^{k - p} Sp=nk−p
以图2.5为例,序列长度 T = 8 T = 8 T=8,切片次数 k = 2 k = 2 k=2,切片数 n = 2 n = 2 n=2,那么通过2次分割,在 l 0 l_{0} l0处得到 S 0 = 2 2 = 4 S_{0} = 2^{2} = 4 S0=22=4个最小子序列,其长度为 l 0 = n = 2 l_{0} = n = 2 l0=n=2,考虑到存在序列长度无法被 n n n整除的情况,可以视情况选择padding方式或者根据序列长度另选参数 n n n的值。
在 l 0 l_{0} l0选取每个最小子序列最终的隐藏状态 h t 1 h_{t}^{1} ht1作为第 l 1 l_{1} l1层的输入,由此可得,在 l p − 1 l_{p- 1} lp−1选取每个最小子序列最终的隐藏状态 h t p + 1 h_{t}^{p + 1} htp+1作为第 l p l_{p} lp层的输入,即:
h t 1 = GRU → 0 ( ms s ( t − l 0 + 1 ) ∼ t 0 ) h_{t}^{1} = {\overrightarrow{\text{GRU}}}^{0}\left( \text{ms}s_{\left( t - l_{0} + 1 \right) \sim t}^{0} \right) ht1=GRU0(mss(t−l0+1)∼t0)
h t p + 1 = GRU → p ( h t − l p p ∼ h t p ) h_{t}^{p + 1} = {\overrightarrow{\text{GRU}}}^{p}\left( h_{t - l_{p}}^{p \sim h_{t}^{p}} \right) htp+1=GRUp(ht−lpp∼htp)
2.5.2 数据分类
与传统的RNN模型的分类一样,SRNN也使用softmax层在最终的隐藏状态 F F F下对 c c c类标签进行分类:
P = s o f t m a x ( W F F + b F ) P = softmax\left( W_{F}F + b_{F} \right) P=softmax(WFF+bF)
2.5.3 损失函数
损失函数使用负对数似然函数:
Loss = − ∑ log P dj \text{Loss} = - \sum_{}^{}{\log P_{\text{dj}}} Loss=−∑logPdj
2.6 情感分类
情感分析又称意见挖掘、倾向性分析等。文本情感分析是对一句话、一段文本的判断,分析出信息发布者的态度、情感、观点等等信息,比如句子“看到如此景象,他气得七窍生烟。”
所表达的情感大类是“怒”,具体情感是“愤怒”;句子“他心灰意冷,蜷缩在小房间的墙角。”所表达的情感大类是“哀”,具体情感是“失望”。
依据文本细腻度而言,文本情感在词汇数量上可以拆分成篇章、句子、词语三大类,依据情感细腻度而言,情感可以分为7大类21小类[13]。在此文中,主要研究的是句子级别的情感分类,同时借助高细腻度的情感,可以有以下分类:
| 编号 | 情感大类 | 情感类 |
|---|---|---|
| 1 | 乐 | 快乐(PA) |
| 2 | 安心(PE) | |
| 3 | 好 | 尊敬(PD) |
| 4 | 赞扬(PH) | |
| 5 | 相信(PG) | |
| 6 | 喜爱(PB) | |
| 7 | 祝愿(PK) | |
| 8 | 怒 | 愤怒(NA) |
| 9 | 哀 | 悲伤(NB) |
| 10 | 失望(NJ) | |
| 11 | 疚(NH) | |
| 12 | 思(PF) | |
| 13 | 惧 | 慌(NI) |
| 14 | 恐惧(NC) | |
| 15 | 羞(NG) | |
| 16 | 恶 | 烦闷(NE) |
| 17 | 憎恶(ND) | |
| 18 | 贬责(NN) | |
| 19 | 妒忌(NK) | |
| 20 | 怀疑(NL) | |
| 21 | 惊 | 惊奇(PC) |
第3章 项目设计
3.1 数据预处理
通常而言,未标注好的数据具有大量的噪声,噪声会对模型的效果产生直接的影响,所以在使用这些数据前,应当对数据进行数据预处理,比如分词、标注、空间向量转换等。
3.1.1 分词
情感词是一段文本中起着关键作用的单元,甚至单个情感词就可以决定一段文本所具有的核心情感,因此将中文语句进行合理分割是一件关键性的事情。
不同于英文,英文文本是依据空格区分每一个单词,但是在中文文本中,段落与句子之间使用中文特定分隔符分割开,但是在句子级别上,词与词之间没有很明显分隔符号,这使得中文文本的分隔要比英文文本困难。为此,现在针对中文词语的分隔方法主要分为基于字符串匹配、基于理解、基于统计的分词这三大类[14],国内比较成熟的系统有复旦大学研发的FudanNLP、中科院研发的NLPIR、哈工大研发的LTP、还有一些国人自己研发的结巴(jieba)中文分词系统等。其中jieba分词系统拥有高效、准确的分词效果,除此之外,它还拥有词性标注、基于TextRank 算法的关键词抽取、基于 TF-IDF算法的关键词抽取、调整词典等一系列强大功能。因此,本文也使用jieba分词工具,分词部分关键代码如下:
# -\*- coding: UTF-8 -\*-
import jieba
class AutoSplitWords():
def split(self, sentence):
'''
自动分词工具
参数:
sentence -- 字符串类型的句子
返回:
list_seq -- 分割好的词语列表
举例:
sentence = '服务态度极其差'
list_seq = ['服务态度', '极其', '差']
'''
tmp = " ".join(jieba.cut(sentence))
list_seq = tmp.split()
return list_seq
3.1.2 去除无关及特殊字符
停用词(StopWords)是指没有意义的词,比如“啊”、“哎”、“唉”、“吧”、“这”、“那”、“的”、“了”、“在”等语气词、介词、助词、代词等,去除之后对情感分析没有实际影响,甚至还可以降低数据噪声、特征向量维度、提高分类准确性等效果。本文使用常见停用词字典对数据进行清洗。
特殊字符(Specialsymbols)是指数学符号、单位符号、货币符号、日文片假名、汉语注音符号、制表符等使用频率较少且难以输入的一类字符,比如“ㄅ”、“≠”、“ǎ”、“▇”等。这一些特殊字符在自然语言处理中无实际意义,去除亦不影响分类效果,同时提升了数据的有效词占比,
从互联网上下载停用词表,其使用关键代码如下:
#使用分词工具将句子分为短词语
list_seq = AutoSplitWords.split(sentence)
#去除停用词
for word in list_seq:
if word in sw_list:
list_seq.remove(word)
3.1.3 Embedding
计算机不能像人一样直接阅读文字,它只能通过计算与逻辑来获知数字含义。因此,计算机对于自然语言的理解只能通过把文本转化为向量、矩阵的形式,通过计算来获取有用的信息,词嵌入应运而生。
词嵌入(WordEmbedding)的目的在于把某个词语、短语映射到高维空间,让相同、相近含义的字词在空间距离上距离相近,比如斯坦福大学训练好的GloVe词嵌入、Google发布的word2vec等都是英文的词语在高维空间上的映射。在中文领域,腾讯发布了AILab
ChineseEmbedding的词嵌入的映射文件,将字词直接映射到了200维的空间,此中文词向量数据在覆盖率、新鲜度和准确性上有大幅提高,其故本文使用腾讯的词嵌入。
由于中文的词向量映射集在解压后有15.5G,共计有8,824,330条字词短语,内存较小的计算机显然不能直接加载,故为满足小内存、低性能的计算机的需要,特建立对词嵌入的映射关系文件,映射后只有313MB,满足了此类计算机的需求,保留中文字段、词嵌入文件对应字段起始位置与空间长度,并提供生成映射文件、查询字表等功能,代码如下:
# -*- coding: UTF-8 -*-
import linecache
import sys
import numpy as np
import gc
import copy
import random
#sys.path.append('../')
from utils.ShowProcess import ShowProcess
class ReadEmbeddings():
def __init__(self, emb_file='embeddings/Tencent_AILab_ChineseEmbedding.txt',map_file='embeddings/embeddings_map_index.txt', \
encoding='utf8', process=ShowProcess(max_steps=8824330)):
self.map_file = map_file
self.emb_file = emb_file
self.encoding = encoding
self.processer = process
self.counter = 0
self.max_count = 8824330
def creat_map_file(self):
'''
当映射表损坏或丢失时,可用此函数来创建映射表,映射表为313MB(320,873KB),大约需要1h+,
【警告】:本函数的所有代码在修改前请三思。
'''
emb_file_name = self.emb_file
map_file_name = self.map_file
start_seek = 12
length = 0
process.max_steps=8824330
i = 1
with open(emb_file_name, 'rb') as emb_file:
next(emb_file) # 跳过第一行的无用数据。
with open(map_file_name, 'a', encoding='utf8') as map_file:
for e in emb_file:
length = len(e)
curr_e = str(e, encoding='utf8').split()[0]
curr_m = '{word} {index} {start_seek} {length}\n'.format(word=curr_e, index=i, start_seek=start_seek, length=length)
map_file.write(curr_m)
start_seek = start_seek + length
i += 1
process.show_process(i)
def load_map_in_memery(self):
'''
因为词嵌入文件过大,所以我们只需要加载它的映射就可以了
返回:
map_list -- 映射列表
'''
# 将映射表加载进内存
tmp_map_list = linecache.getlines(self.map_file)
map_list = []
for m in tmp_map_list:
curr_m = m.split()
curr_list_word = [curr_m[0]]
curr_list_value = list(map(int, curr_m[1:]))
map_list.append(curr_list_word + curr_list_value)
return map_list
def clear_cache(self):
'''
当不再需要映射列表的时候,调用此函数可以立即清除缓存,释放空间。
'''
linecache.clearcache()
def find_by_list(self, map_list, query_list ,f_log_obj=None):
'''
批量查询它的词嵌入权值
参数:
map_list -- 映射列表,可通过load_map_in_memery()函数得到。
query_list -- 要查询的词汇的列表
defalut -- 默认值【"0" | "random"】
返回:
return_dict -- 字典类型,键为词汇,值为对应的词嵌入权值。
example:{'我们':[0.238955, -0.192848, ... , 0.137744],'...':[...],...}
'''
is_log = False
if f_log_obj:
is_log = True
query_list2 = copy.deepcopy(query_list)
if len(query_list2) == 0:
if is_log:
is_log = False
f_log_obj.write("query_list is empty!\n")
return -1
return_dict = {}
with open(self.emb_file, 'rb') as emb:
for m in map_list:
for q in query_list2:
if q in m:
emb.seek(m[2])
value = list(map(float, emb.read(m[3]).split()[1:]))
return_dict[str(q)] = value
query_list2.remove(q)
if len(query_list2) >= 1:
for q in query_list2:
#print("Waring: " + q + " not in the embeddings.")
if is_log:
f_log_obj.write("未找到:{word} \n".format(word=str(q)))
return_dict[str(q)] = [0.0]*200
query_list2.remove(q)
return return_dict
def find_by_word(self, map_list, word, is_del_element=False, f_log_obj=None):
is_log = False
if f_log_obj:
is_log = True
value = []
with open(self.emb_file, 'rb') as emb:
for m in map_list:
if word in m:
emb.seek(m[2])
value = list(map(float, emb.read(m[3]).split()[1:]))
if is_del_element:
map_list.remove(m)
f_log_obj.write("删除:{m} \n".format(m=str(m)))
return value
if is_log:
f_log_obj.write("未找到:{word} \n".format(word=word))
return [0.0]*200
3.2 数据集处理
3.2.1 数据集的构建
在本文中,数据集中的句子需要使用分词工具分隔后再使用空格作分隔符存储至文件中,再另起文件存储标签,格式如下:
| 数据原文 | 分隔后的句子 | 存储内容 |
|---|---|---|
| ‘服务态度极其差’ | ‘服务态度’ ‘极其’ ‘差’ | 服务态度 极其 差 |
对于标签,则使用另外一个文件进行存储,与数据集的存储顺序一致,存储方式如下:
| 数据原文 | 分隔后的句子 | 存储内容 |
|---|---|---|
| ‘服务态度极其差’ | ‘服务态度’ ‘极其’ ‘差’ | NJ |
在选用的数据集中,数据被分为7大类21小类,每个分类拥有200条的数据量,即数据集拥有 10000 × 21 = 210 , 000 10000 \times 21 = 210,000 10000×21=210,000条数据,与其对应的是相同数量的标签。
| 分类 | 数量 | 分类 | 数量 |
|---|---|---|---|
| NB | 10000 | PG | 10000 |
| PH | 10000 | PC | 10000 |
| NN | 10000 | NA | 10000 |
| PA | 10000 | PF | 10000 |
| PD | 10000 | NC | 10000 |
| PB | 10000 | NH | 10000 |
| PK | 10000 | PE | 10000 |
| NE | 10000 | NI | 10000 |
| NG | 10000 | NK | 10000 |
| NJ | 10000 | NL | 10000 |
| ND | 10000 |
3.2.2 打乱数据集
在使用数据集的过程中,为了避免数据集中数据的顺序对结果造成影响,需要对数据集进行乱序处理。其中, X X X代表数据集的数据部分, Y Y Y代表数据集的标签部分, X Y XY XY一一对应。代码如下:
from keras.utils.np_utils import to_categorical
import numpy as np
X = read_dataset_data()
Y = read_dataset_lables()
Y = to_categorical(Y,num_classes=21)
#shuffle the data
indices = np.arange(X.shape[0])
np.random.seed(2019)
np.random.shuffle(indices)
X = X[indices]
Y = Y[indices]
3.2.3 数据集的分配
在深度学习的数据集处理中,一项很重要的工作就是处理数据集。数据集的分配大多按照80%-10%-10%的大小进行分配,其中训练集占据80%,测试集占据10%,验证集占据10%。这里使用通用了的经验:
| 训练集 | 测试集 | 验证集 |
|---|---|---|
| 80% | 10% | 10% |
其代码为:
VALIDATION_SPLIT = 0.1
TEST_SPLIT = 0.1
#training set, validation set and testing set
nb_validation_samples_val = int((VALIDATION_SPLIT + TEST_SPLIT) \* X.shape[0])
nb_validation_samples_test = int(TEST_SPLIT \* X.shape[0])
x_train = X[:-nb_validation_samples_val]
y_train = Y[:-nb_validation_samples_val]
x_val = X[-nb_validation_samples_val:-nb_validation_samples_test]
y_val = Y[-nb_validation_samples_val:-nb_validation_samples_test]
x_test = X[-nb_validation_samples_test:]
y_test = Y[-nb_validation_samples_test:]
3.2.4 分词器
这里的分词器使用keras的Tokenizer,用于向量化文本、文本转序列的工具,其好处在于直接访问内存索引,不需要访问磁盘,大大提高效率。
| 词汇 | 转换值 |
|---|---|
| “你好” | 25896 |
| “hello” | 1248 |
与之对应的是词向量加载的值:
| 索引 | 词汇 | 词向量值 |
|---|---|---|
| 1248 | “hello” | 对应的200维的向量 |
| 25896 | “你好” | 对应的200维的向量 |
关键代码如下:
import json
def save_dict(filename, dic):
'''save dict into json file'''
with open(filename,'a+', encoding="utf8") as json_file:
json.dump(dic, json_file, ensure_ascii=False)
save_dict("vocab.json", vocab)
tokenizer1 = Tokenizer(num_words=MAX_NUM_WORDS, lower=False)
tokenizer1.fit_on_texts(X.tolist())
vocab = tokenizer1.word_index
x_train_word_ids = tokenizer1.texts_to_sequences(x_train)
x_test_word_ids = tokenizer1.texts_to_sequences(x_test)
x_val_word_ids = tokenizer1.texts_to_sequences(x_val)
3.2.5 文本填充
由于SRNN需要对文本进行多次分割,不同长度的句子在分割后会得到不同的长度,为了解决这一问题,引入文本填充,指定句子的长度,未达到长度的句子将会以“0”来进行填充,长度超过指定长度的句子将会被截断。
| 句子 | 结果(指定最长长度为10) |
|---|---|
| “你好世界” | “000000你好世界” |
| “这个世界需要更多的英雄” | “个世界需要更多的英雄” |
代码如下:
from keras.preprocessing.sequence import pad_sequences
MAX_LEN =128
x_train_padded_seqs = pad_sequences(x_train_word_ids,
maxlen=MAX_LEN,padding='pre',truncating='pre')
x_test_padded_seqs = pad_sequences(x_test_word_ids,
maxlen=MAX_LEN,padding='pre',truncating='pre')
x_val_padded_seqs = pad_sequences(x_val_word_ids,
maxlen=MAX_LEN,padding='pre',truncating='pre')
3.2.6 句子分割
在上文中提到SRNN需要对句子进行多次分割,其代码如下:
def split_seq(seq, n):
seq_split = []
for i in range(seq.shape[0]):
split1 = np.split(seq[i],n)
tmp = []
for j in range(n):
s = np.split(split1[j],n)
tmp.append(s)
seqs_split.append(tmp)
return seq_split
# 把数据集进行分割
n = 8
x_train_padded_seqs_split = split_seq(x_train_padded_seqs, n)
x_test_padded_seqs_split = split_seq(x_test_padded_seqs, n)
x_val_padded_seqs_split = split_seq(x_val_padded_seqs, n)
3.3 词嵌入的加载
使用预训练的词嵌入矩阵需要查询词嵌入的值然后添加进矩阵中,然后构建嵌入层。
代码如下:
embedding_matrix = np.random.random((MAX_NUM_WORDS + 1, EMBEDDING_DIM))
for word, i in vocab.items():
proc.show_process(i)
query_word = word.replace("'","").strip()
embedding_vector = emb.find_by_word(emb_map_list,query_word,is_del_element=True, f_log_obj = log_obj)
if embedding_vector == [0.0]*200:
embedding_matrix[i] = embedding_vector
embedding_layer = Embedding(MAX_NUM_WORDS + 1,
EMBEDDING_DIM,
weights=[embedding_matrix],
input_length=MAX_LEN//64,
trainable=True)
3.4 进度条
在使用的过程中会出现不知道当前进度的情况,这里实现了进度条的功能:
# -*- coding: UTF-8 -*-
import sys
class ShowProcess():
"""
显示处理进度的类
调用该类相关函数即可实现处理进度的显示
"""
i = 0 # 当前的处理进度
max_steps = 100 # 总共需要处理的次数
max_arrow = 100 #进度条的长度
infoDone = 'done'
# 初始化函数,需要知道总共的处理次数
def __init__(self, max_steps=max_steps, infoDone = 'Done'):
self.max_steps = max_steps
self.i = 0
self.infoDone = infoDone
# 显示函数,根据当前的处理进度i显示进度
# 效果为[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>]100.00% 100|100
def show_process(self, i=None):
if i is not None:
self.i = i
else:
self.i += 1
num_arrow = int(self.i * self.max_arrow / self.max_steps) #计算显示多少个'>'
num_line = self.max_arrow - num_arrow #计算显示多少个'-'
percent = self.i * 100.0 / self.max_steps #计算完成进度,格式为xx.xx%
process_bar = '[{curr_process}{incomplete}] {curr_percent:.2f}%\t{i}|{max_steps}\r'.format(
curr_process = '>' * num_arrow,
incomplete = '-' * num_line,
curr_percent = percent,
i = i,
max_steps = self.max_steps)
sys.stdout.write(process_bar) #这两句打印字符到终端
sys.stdout.flush()
if self.i >= self.max_steps:
self.close()
def close(self):
print('')
print(self.infoDone)
self.i = 0
3.5 模型构建
这里使用Keras框架构建模型:
input1 = Input(shape=(MAX_LEN//64,))
embed = embedding_layer(input1)
gru1 = GRU(NUM_FILTERS, recurrent_activation='sigmoid')(embed)
Encoder1 = Model(input1, gru1)
input2 = Input(shape=(8,MAX_LEN//64,))
embed2 = TimeDistributed(Encoder1)(input2)
gru2 = GRU(NUM_FILTERS, recurrent_activation='sigmoid')(embed2)
Encoder2 = Model(input2,gru2)
input3 = Input(shape=(8,8,MAX_LEN//64))
embed3 = TimeDistributed(Encoder2)(input3)
gru3 = GRU(NUM_FILTERS, recurrent_activation='sigmoid')(embed3)
preds = Dense(21, activation='softmax')(gru3)
model = Model(input3, preds)
参数分布如下:
| 层 | 层名 | 类型 | 输出维度 | 参数量 |
|---|---|---|---|---|
| 1 | input_1 | InputLayer | (None, 2) | 0 |
| embedding_1 | Embedding | (None, 2, 200) | 33478200 | |
| gru_1 | GRU | (None, 50) | 37650 | |
| 2 | input_2 | InputLayer | (None, 8, 2) | 0 |
| time_distributed_1 | TimeDistributed | (None, 8, 50) | 33515850 | |
| gru_2 | GRU | (None, 50) | 15150 | |
| 3 | input_3 | InputLayer | (None, 8, 8, 2) | 0 |
| time_distributed_2 | TimeDistributed | (None, 8, 50) | 33515850 | |
| gru_3 | GRU | (None, 50) | 15150 | |
| dense_1 | Dense | (None, 21) | 1071 |
每一层的总参数如下:
| 层 | 总参数量 | 可训练参数量 | 不可训练参数量 |
|---|---|---|---|
| 1 | 33,515,850 | 37,650 | 33,478,200 |
| 2 | 33,531,000 | 52,800 | 33,478,200 |
| 3 | 33,547,221 | 69,021 | 33,478,200 |
| 总结 | 100,597,071 | 159,471 | 100,434,600 |
3.6 编译与训练
模型构建之后就需要进行编译与训练,其代码为:
#使用adam optimizer
from keras.optimizers import Adam
opt = Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-08)
# 编译模型
model.compile(loss='categorical_crossentropy',
optimizer=opt,
metrics=['acc'])
# 保存在验证集中效果最好的模型
from keras.callbacks import ModelCheckpoint
savebestmodel = 'model/SRNN(8,2)_CN.h5'
checkpoint = ModelCheckpoint(savebestmodel, monitor='val_acc', verbose=1, save_best_only=True, mode='max')
callbacks=[checkpoint]
# 拟合模型
model.fit(np.array(x_train_padded_seqs_split), y_train,
validation_data = (np.array(x_val_padded_seqs_split), y_val),
nb_epoch = EPOCHS,
batch_size = Batch_size,
callbacks = callbacks,
verbose = 1)
3.7 加载训练好的模型
有保存就有加载,加载模型的代码为:
from keras.models import load_model
best_model= load_model(savebestmodel)
print(best_model.evaluate(np.array(x_test_padded_seqs_split),y_test,batch_size=Batch_size))
3.8模型训练与观测
3.8.1 模型的训练
模型使用了多种方式进行了训练,情况如下表:
| 数据填充方式 | 优化器 | 迭代次数 | 训练集准确度 | 验证集准确度 |
|---|---|---|---|---|
| 后填充 | Adam | 35 | 0.6366 | 0.6166 |
| 后填充 | Adam | 45 | 0.6866 | 0.5993 |
| 后填充 | RMSprop | 35 | 0.6897 | 0.6143 |
| 后填充 | RMSprop | 45 | 0.7215 | 0.6002 |
| 前填充 | Adam | 35 | 0.6934 | 0.6115 |
| 前填充 | Adam | 45 | 0.7801 | 0.6919 |
| 前填充 | RMSprop | 35 | 0.6916 | 0.6129 |
| 前填充 | RMSprop | 45 | 0.7111 | 0.6140 |
3.8.2 模型的观测
既然训练了模型,就要使用模型,使用模型的predict函数代码如下:
def predict(sentence="", vocab_file_path=None, vocab_obj=None, model_path=None, model_obj=None):
from keras.models import load_model
import json
def load_dict(vocab_file_path):
'''load dict from json file'''
with open(vocab_file_path,"r", encoding="utf8") as json_file:
dic = json.load(json_file)
return dic
return_dict = {}
if vocab_obj:
vocab = vocab_obj
if vocab_file_path:
# 加载vocab
vocab=load_dict(vocab_file_path)
if not vocab_obj and not vocab_file_path:
return_dict = {
"error": -1,
"reason": "未找到vocab的对象或文件地址",
"solution" : "请传入'vocab_file_path'或者'vocab_obj'"
}
return return_dict
if model_path:
model= load_model(model_path)
if model_obj:
model = model_obj
if not model_path and not model_obj:
return_dict = {
"error": -2,
"reason": "未找到模型的对象或模型的文件地址",
"solution" : "请传入'model_path'或者'model_obj'"
}
return return_dict
from keras.preprocessing.text import Tokenizer, text_to_word_sequence
from keras.preprocessing.sequence import pad_sequences
import numpy as np
import utils.AutoSplitWords as AutoSplitWords
def split_seq(seq, n):
seq_split = []
for i in range(seq.shape[0]):
split1 = np.split(seq[i],n)
a=[]
for j in range(n):
s = np.split(split1[j],n)
a.append(s)
seq_split.append(a)
return seq_split
def texts_to_sequences(vocab, list_words):
return_list = []
for word in list_words:
try:
return_list.append(vocab[word])
except:
return_list.append(0)
return return_list
lable_dict={
"NB": 0,
"PH": 1,
"NN": 2,
"PA": 3,
"PD": 4,
"PB": 5,
"PK": 6,
"NE": 7,
"NG": 8,
"NJ": 9,
"ND": 10,
"PG": 11,
"PC": 12,
"NA": 13,
"PF": 14,
"NC": 15,
"NH": 16,
"PE": 17,
"NI": 18,
"NK": 19,
"NL": 20,
}
value_map_classes_dict = {
0: 'NB',
1: 'PH',
2: 'NN',
3: 'PA',
4: 'PD',
5: 'PB',
6: 'PK',
7: 'NE',
8: 'NG',
9: 'NJ',
10: 'ND',
11: 'PG',
12: 'PC',
13: 'NA',
14: 'PF',
15: 'NC',
16: 'NH',
17: 'PE',
18: 'NI',
19: 'NK',
20: 'NL'
}
word_map_class_exquisite_classes_en = {
"快乐" : "PA",
"安心" : "PE",
"尊敬" : "PD",
"赞扬" : "PH",
"相信" : "PG",
"喜爱" : "PB",
"祝愿" : "PK",
"愤怒" : "NA",
"悲伤" : "NB",
"失望" : "NJ",
"疚" : "NH",
"思" : "PF",
"慌" : "NI",
"恐惧" : "NC",
"羞" : "NG",
"烦闷" : "NE",
"憎恶" : "ND",
"贬责" : "NN",
"妒忌" : "NK",
"怀疑" : "NL",
"惊奇" : "PC"
}
word_map_class_rough_classes = {
"快乐" : "乐",
"安心" : "乐",
"尊敬" : "好",
"赞扬" : "好",
"相信" : "好",
"喜爱" : "好",
"祝愿" : "好",
"愤怒" : "怒",
"悲伤" : "哀",
"失望" : "哀",
"疚" : "哀",
"思" : "哀",
"慌" : "惧",
"恐惧" : "惧",
"羞" : "惧",
"烦闷" : "恶",
"憎恶" : "恶",
"贬责" : "恶",
"妒忌" : "恶",
"怀疑" : "恶",
"惊奇" : "惊"
}
classes_map_word_exquisite_classes = {
'PA': '快乐',
'PE': '安心',
'PD': '尊敬',
'PH': '赞扬',
'PG': '相信',
'PB': '喜爱',
'PK': '祝愿',
'NA': '愤怒',
'NB': '悲伤',
'NJ': '失望',
'NH': '疚',
'PF': '思',
'NI': '慌',
'NC': '恐惧',
'NG': '羞',
'NE': '烦闷',
'ND': '憎恶',
'NN': '贬责',
'NK': '妒忌',
'NL': '怀疑',
'PC': '惊奇'
}
MAX_LEN = 128
n = 8
# 加载分词工具
sp = AutoSplitWords.AutoSplitWords()
splited_sentence_list = sp.split(sentence)
sentence_word_ids = texts_to_sequences(vocab, splited_sentence_list)
sentence_padded_seqs = pad_sequences([sentence_word_ids], maxlen=MAX_LEN,padding='pre',truncating='pre')
sentence_padded_seqs_split = split_seq(sentence_padded_seqs, n)
sentence_padded_seqs_split = np.array(sentence_padded_seqs_split)
sentence_classes = np.argmax(model.predict(sentence_padded_seqs_split), axis=1)
class_num = int(sentence_classes)
class_EN = value_map_classes_dict[class_num]
class_cn_exquisitly = classes_map_word_exquisite_classes[class_EN]
class_cn_rough = word_map_class_rough_classes[class_cn_exquisitly]
return_dict={
"splited_sentence_list": splited_sentence_list,
"sentence_word_ids" : sentence_word_ids,
"sentence_padded_seqs_split" : sentence_padded_seqs_split,
"orgin_text" : sentence,
"class_num": class_num,
"class_EN" : class_EN,
"class_cn_exquisitly" : class_cn_exquisitly,
"class_cn_rough" : class_cn_rough
}
return return_dict
from keras.models import load_model
sentcence = "今天的天气是真的很好!"
model= load_model("Model/save_model/SRNN(8,2)_cn_predata_45e.h5")
vocab_file_path = "vocab.json"
result_dict= predict(sentcence, vocab_file_path=vocab_file_path, model_obj=model)
其中,result_dict返回的信息如下:
| 原句 | ‘orgin_text’ | ‘今天的天气是真的很好!’ |
|---|---|---|
| 分词 | ‘splited_sentence_list’ | [‘今天’,‘的’,‘天气’,‘是’,‘真的’,‘很’,‘好’,’!’] |
| 词汇id | ‘sentence_word_ids’ | [170, 2, 817, 5, 322, 65, 63, 21], |
| 填充后的数据 | ‘sentence_padded_seqs_split’ | array([[[[……, [0,0],[170,2], [817,5], [322,65], [63,21]]]]) |
| 分类序号 | ‘class_num’ | 5 |
| 分类代号 | ‘class_EN’ | ‘PB’, |
| 所属情感大类 | ‘class_cn_rough’ | '好 |
| 情感细分 | ‘class_cn_exquisitly’ | ‘喜爱’ |
可以看出,在给定的句子下,模型的分类器给出了正确的分类,虽然在整体的数据集中只有不到70%的准确率,但是就现在的情况而言,分类器还没有把句子的大致极性情感判断失误。
第4章 总结
最近这几年自然语言处理变得越来越热门,但是相关算法在很多年以前就已经有了,热门主要的原因在于机器性能的提升、数据爆炸等等一系列相关因素。本文在文本数据量剧增的背景下探讨了使用深度学习判定文本的情感的可行性以及国内外前辈们所做的研究工作,举例说明了深度学习在情感分析上有哪些应用案例,研究了标准RNN模型、RNN单元、长短时记忆单元(LSTM)、门控循环单元(GRU)、切片循环神经网络(SRNN)的结构以及算法,使用了切片循环神经网络来构建此项目并应用在情感分类上。
本项目的不足点在于:
-
数据集上,由于分类标签很少、数据量不足、数据噪声的存在,这注定在测试中无法达到很高的准确率。
-
模型的选择上,在表3.9参数总结表上可以看出可训练的参数只有159,471个,仅仅占据全部参数的15.85%,这与动辄达到上百万千万的参数模型相比,此模型的能力确实是有限的。
受时间的限制,本项目的研究与设计也存在着一定的不足,对于本项目中的方法也缺少更多的摸索与探究。例如:如果数据集的每一条数据都有完全正确的标签是否会提高表现性能?如果把词嵌入也并入训练范畴会怎样?如果构建更深的网络效果会不会更好?
参考文献
[1] Pang B, Lee L, Vaithyanathan S. Thumbs up?: Sentiment Classification using
Machine Learning echniques[C]//Proceedings of Annual Conference of the
Association for Computational Linguistics, 2002:79-86.
[2] 任远,巢文涵,周庆,李舟军,等. 基于话题自适应的中文微博情感分析[J].
计算机科学.2013,40(11):231-270.
[3] 曹宇慧.基于深度学习的文本情感分析研究[D].深圳:哈尔滨工业大学,2015:1
[4] Pang B, Lee L. Opinion Mining and Sentiment Analysis[J]. Foundations and
Trends in Information Retrieval, 2008, 2(1-2): 1-135.
[5] Rumelhart D E, Hinton G E, Williams R J. Learning Representations by
Back-propagating Errors[J]. Cognitive Modeling, 1988, 5:533-536.
[6] Bengio Y, Ducharme R, Vincent P, Jauvin C. A Neural Probabilistic Language
Model[J]. The Journal of Machine Learning Research, 2003 , 3: 1137-1155.
[7] Collobert R, Weston J, Bottou L, Karlen M, Kavukcuoglu K, Kuksa P. Natural
Language Processing (almost) from Scratch[J]. The Journal of Machine Learning
Research, 2011, 12: 2493-2537.
[8] Mikolov T, Karafiát M, Burget L, et al. Recurrent neural network based
language model[J]. Interspeech. 2010: 1045-1048.
[9] Kim Y. Convolutional Neural Networks for Sentence Classification[J]. Eprint
Arxiv, 2014.
[10] 梁军,柴玉梅,原慧斌,等. 基于极性转移和 LSTM 递归网络的情感分析[J].
中文信息学报. 2015(05): 152-159.
[11] 刘龙飞,杨亮,张绍武,等. 基于卷积神经网络的微博情感倾向性分析[J].
中文信息学报. 2015(06): 159-165.
[12] Yu Z , Liu G . Sliced Recurrent Neural Networks[J]. 2018.
[13] 徐琳宏,林鸿飞,潘宇,任惠,陈建美,等
情感词汇本体的构造[J].情报学报,2008, 27(2)
[14] 樊小超. 基于机器学习的中文文本主题分类及情感分类研究[D].南京理工大学,2014. network based
language model[J]. Interspeech. 2010: 1045-1048.
[9] Kim Y. Convolutional Neural Networks for Sentence Classification[J]. Eprint
Arxiv, 2014.
[10] 梁军,柴玉梅,原慧斌,等. 基于极性转移和 LSTM 递归网络的情感分析[J].
中文信息学报. 2015(05): 152-159.
[11] 刘龙飞,杨亮,张绍武,等. 基于卷积神经网络的微博情感倾向性分析[J].
中文信息学报. 2015(06): 159-165.
[12] Yu Z , Liu G . Sliced Recurrent Neural Networks[J]. 2018.
[13] 徐琳宏,林鸿飞,潘宇,任惠,陈建美,等
情感词汇本体的构造[J].情报学报,2008, 27(2)
[14] 樊小超. 基于机器学习的中文文本主题分类及情感分类研究[D].南京理工大学,2014.
致谢
行文至此,不免有唏嘘感慨。回想自己在成都东软学院的这4年时间,无论是生活还是学习上都颇有收获,点点滴滴历历在目,离开校园之际,谨在此向在我学习与生活中给予我无私帮助的老师、同学、朋友即及家人表示最诚挚的谢意与祝愿。
本文是在我的指导老师童浩老师的悉心指导下完成的,他严谨认真的教学态度让我受益匪浅以及敬佩万分,遇到困难与挫折时会细心地指导我。在他的关心和指导下,我顺利完成了毕业设计,在此对童老师表示由衷的谢意!
其次要感谢的是我的好友李彦宏,他潜移默化地引导了我的人生方向,无论是学习的态度还是学习的方向,我们曾一起欢乐、努力与进步。感谢他对我的支持与帮助。
还要感谢的是我的家人,他们在我的背后默默地支持我,在生活上给我了极大地鼓励,家人对我的爱是我不断前进的动力。