cpu利用率
方法一:
100 - (avg(increase(node_cpu_seconds_total{mode="idle"}[1m])) by (instance) / 60) * 100
方法二:
100 - avg(rate(node_cpu_seconds_total{mode="idle"}[1m])) by (instance) * 100
方法三:
100 - avg(irate(node_cpu_seconds_total{mode="idle"}[1m])) by (instance) * 100
计算cpu是通过/proc/stat中第四列的idle的cpu时间片计算的
root@Prometheus:~# cat /proc/stat
cpu 148499 3877 89516 481390579 39919 0 1641 1151 0 0
cpu0 42643 1845 26582 120310710 36391 0 447 215 0 0
cpu1 31605 729 18455 120360192 757 0 426 200 0 0
cpu2 43326 353 26240 120349498 1838 0 371 434 0 0
cpu3 30924 948 18237 120370177 931 0 397 301 0 0 intr 136119739 3 9 0 0 0 0 3 0 0 1 0 120504 15 0 0 0 0 0 0 0 0 0 0 0 0 21 0 192930 2 360048 2 0 1055623 0 105 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 ctxt 237129237 btime 1567583772 processes 103191 procs_running 1 procs_blocked 0 softirq 67537036 0 26595157 1 2152054 0 0 24 26667933 0 12121867

cpu饱和度
node_load1 > on (instance) count (node_cpu_seconds_total{mode="idle"}) by (instance) *2
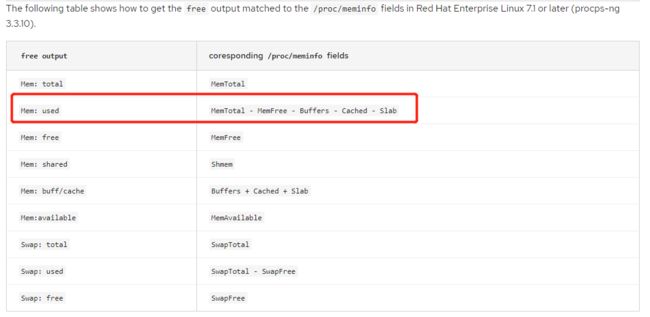
内存使用率
参考链接:https://access.redhat.com/solutions/406773
关注node_memory度量的一个子集,以提供我们的利用率度量:
• node_memory_MemTotal_bytes - 主机上的总内存
• node_memory_MemFree_bytes - 主机上的空闲内存
• node_memory_Buffers_bytes - 缓冲区缓存中的内存
• node_memory_Cached_bytes - 页面缓存中的内存。
所有这些指标都以字节表示
表达式:
(node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Cached_bytes + node_memory_Buffers_bytes)) / node_memory_MemTotal_bytes * 100
内存饱和度
- node_ vmstat_ pswpin: 系统 每秒 从 磁盘 读到 内存 的 字节数。
- node_ vmstat_ pswpout: 系统 每秒 从内 存 写到 磁盘 的 字节数。
sum (rate(node_vmstat_pgpgin[1m]) + rate(node_vmstat_pgpgout[1m])) by (instance) * 1024
磁盘使用率
表达式;
(node_filesystem_size_bytes - node_filesystem_free_bytes) / node_filesystem_size_bytes * 100
文件描述符inodes
(node_filesystem_files{fstype="ext4"} - node_filesystem_files_free{fstype="ext4"}) / node_filesystem_files{fstype="ext4"} * 100
Prometheus提供了一种机制,通过名为predict_linear的函数,可以预示磁盘增长率,在未来多长时间可以将磁盘占满。
predict_linear(node_filesystem_free_bytes{mountpoint="/"}[1h], 10*3600) < 0
服务状态
| node_systemd_unit_state{instance="10.10.0.101:9100",job="node",name="grafana-server.service",state="activating",type="simple"} | 0 |
| node_systemd_unit_state{instance="10.10.0.101:9100",job="node",name="grafana-server.service",state="active",type="simple"} | 1 |
| node_systemd_unit_state{instance="10.10.0.101:9100",job="node",name="grafana-server.service",state="deactivating",type="simple"} | 0 |
| node_systemd_unit_state{instance="10.10.0.101:9100",job="node",name="grafana-server.service",state="failed",type="simple"} | 0 |
| node_systemd_unit_state{instance="10.10.0.101:9100",job="node",name="grafana-server.service",state="inactive",type="simple"} | 0 |
查看服务状态为active状态的服务
node_systemd_unit_state{state="active"}
或
node_systemd_unit_state{job="node"} == 1
向量匹配
一对一匹配
一对一配置从每一侧找到唯一匹配的条目对。如果两个条目具有完全相同的标签值,则它们是一对一匹配的。你可以考虑使用ignoring修饰符忽略掉特定标签,或者使用on修饰符来减少显示的标签列表。例如:
node_systemd_unit_state{name="grafana-server.service"} == 1 and on (instance,job)metadata{datacenter!="BJ"}
查询所有node_systemd_unit_state指标中name标签为grafana-server.service并且值为1的指标。然后使用on修饰符将返回的标签列表减少到metadata指标的instance和job标签。并且datacenter标签的值为BJ