C++的学习心得和知识总结 第八章(完)
本章:C++的重点:C++ STL
文章目录
- 本章:C++的重点:C++ STL
- standard template libaray 标准模板库
- 一、标准容器
- 二、近容器
- 三、迭代器
- 四、函数对象(类似C的函数指针)
- 五、泛型算法(约 70多个)
- 顺序容器之vector:
- 顺序容器之deque 双端队列:
- 顺序容器之list 链表:
- 顺序容器之三种容器的对比:
- 容器适配器
- 无序关联容器之set
- 无序关联容器之map
- 有序关联容器之set
- 有序关联容器之map
- 迭代器iterator
- 函数对象
- 泛型算法和绑定器
standard template libaray 标准模板库
无论是安装C++的哪一种编译器,以下类库都会被包含进去后安装到本地的操作系统上。使用时候,include相应头文件即可。所谓模板:这些类库(和算法库)都是用模板实现的。其优点在于一套代码实现 指定类型然后去实例化模板即可得到处理某一类型的一套具体代码。
一、标准容器
(C++11里面还提供了array forward_list)
1.顺序容器 (底层其数据结构 顺序表:数组、链表、栈、队列等)
vector(向量):
deque(双端队列)
list(链表)
2.容器适配器
stack
queue
priority_queue(基于大根堆)
3.关联容器 (基于高级数据结构实现的容器,非常重要)
无序关联容器 => 链式哈希表 增删查趋近于O(1)
(哈希表里面的元素只追求速度,而对元素本身并没有排序的操作)
set:集合 key map:映射表 [key,value]
unordered_set 单重集合
unordered_multiset 多重集合
unordered_map 单重映射表
unordered_multimap 多重映射表
有序关联容器 => 红黑树 增删查O(log2n) 2是底数(树的层数,树的高度)
set
multiset
map
multimap
二、近容器
数组,string,bitset(位容器:处理位运算)
(大数据之位图法、哈夫曼编码、位编码解码上很重要)
三、迭代器
iterator和const_iterator(普通和常量 迭代器)
reverse_iterator和const_reverse_iterator(正向和反向 迭代器)
四、函数对象(类似C的函数指针)
greater,less
(在类模板 类库 算法里面使用很多,非常重要)
五、泛型算法(约 70多个)
sort,find,find_if,binary_search,for_each
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
顺序容器之vector:
底层数据结构:以原来空间大小2倍进行扩容的动态开辟数组。
扩容:1 根据原来空间大小,2倍开辟更大的内存。2 原空间上的对象在新空间上进行拷贝构造,生成新的对象。3 把原空间上的对象析构, 再把原来空间的内存释放。

扩容对于容器而言是一种 消耗。因此 提高vector的内存利用效率很重要!!!
vector底层是一个数组,在中间的某一位置insert 数据的时候,插入点及其后面的元素都要后移,移动时间正比于移动元素的个数。同时erase 数据的时候,删除点及其后面的元素都要后移,移动时间正比于移动元素的个数。

对于查询:
第一点是通过【】运算符重载,实现在O(1)时间复杂度内实现 查询
第二点是通用的查询方式(建议使用)
第三点是使用泛型算法进行完成的
第四点foreach底层的实现 也是iterator实现的

#include 运行截图:
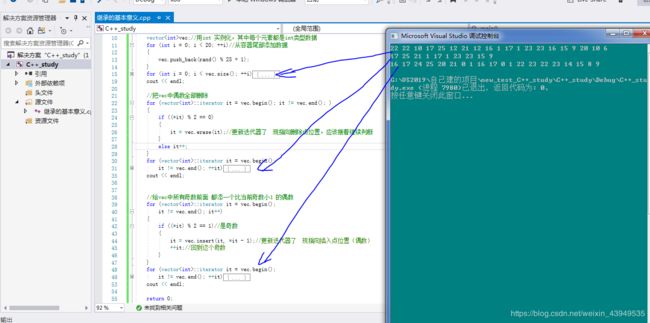
vectorvec;//用int 实例化,其中每个元素都是int类型数据
for (int i = 0; i < 20; ++i)//从容器尾部添加数据
{
vec.push_back(rand() % 25 + 1);
}
这里定义的vec 还没有开辟空间。当第一次push_back的时候,从
0 ——1——2——4——8——16-----
扩容的代价太高,以原来空间大小2倍的方式进行扩容。 原空间上的对象在新空间上进行拷贝构造,在新内存上生成新的对象。把原空间上的对象析构, 再把原来空间的内存释放。初始内存使用率太低,扩容太过频繁。
假如我们在处理数据的时候,就已经可以确定 数据量大概在20左右。用reserve非常好。


reserve 只是给vec预留空间,并没有往里面放元素。所以vec还是空的,且元素个数为0。 其作用在push_back的时候出来了,这个时候就不会再频繁的扩容了。已经预留20个空间了。这在很大程度上 效率上将是一个很大的提升。
![]()
resize

最后扩容 20——40 。
源代码如下:
#include 顺序容器之deque 双端队列:
两端都可以做队头队尾,队列(从队尾入,队头出)。因此这里可以从队头入,也可以从队头出。从队尾入,也可以从队尾出。
deque底层的数据结构:
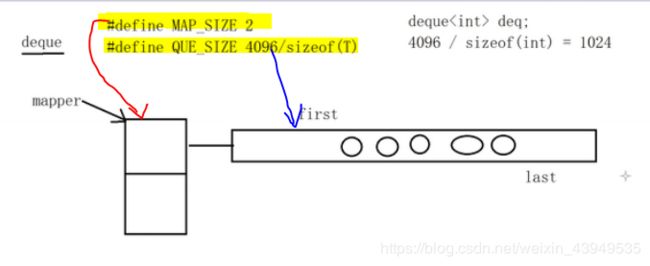
mapper指针指向一维的默认大小(MAP_SIZE 2) 第二维动态开辟的空间是多少个(与元素的类型有关 )假如此时 deque< int >deq; 则这里开辟的二维就是 4096/sizeof(int)=1024 个
在这里,只画出一个方向作为表示。deque< int >deq; 暂且把第二维的1024个空间都放成整数。first 与 last就处在中间位置(好处就是在于两头都预留足够的空间,因为这是双端队列啊,每一端都可以插入的)随着元素的增加,first last两个指针都会向左右移动。当元素满的时候 如下:
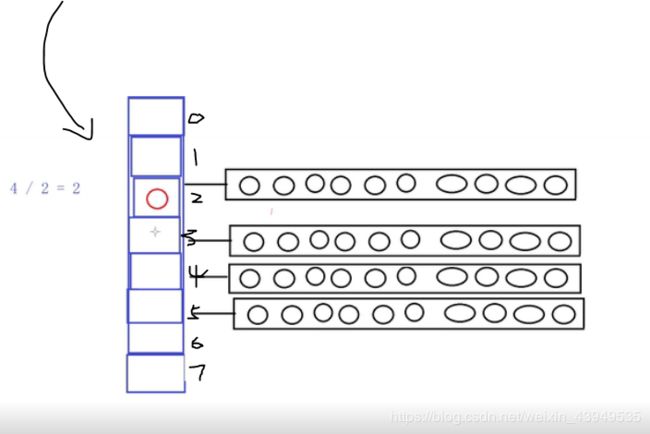
如果还需要入队,这个时候只能 去另外的二维的开辟。如下:

当元素继续增加,直至满了。

此时的deque就需要扩容了,这个扩的是第一维的。(2倍的扩容,MAP_SIZE 变成了4)此时的一维指针mapper指向了 新的空间,至于第二维的两行数据 最好的是放在中间两行。这是因为:这是双端队列,两端都可以进出(给两端都预留空间)

再需要入元素,则需要 第一行 第四行重新开辟 另外的二维(中间的两行 两维不再需要变动)如下:

总结:一维是按照2倍进行扩容的;扩容之后,第二维放在一维的中间(方便两端元素的添加)。那是怎么计算放的开始位置呢?oldsize/2 原来空间的一维的大小。比如是2,则最后MAP_SIZE 的大小都扩大到4 。所以原来的两行放在oldsize/2 即1的下标 开始存放原空间的二维的数据。(oldsize/2 保证可以放到新空间的正中间,方便下一次的元素进出)

比如 一维由4扩大到8。这样之后,上下仍旧留了两行。(原来数据居于正中间)
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
 deque的添加(从前 还是后)都不涉及其他数据的移动。前后都支持插入 O(1) 。
deque的添加(从前 还是后)都不涉及其他数据的移动。前后都支持插入 O(1) 。
而且也支持从中间的某一个位置添加,只是这样的话 会引起其他元素的移动 O(n)
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
顺序容器之list 链表:

每一个节点都有数据域 前驱指针 后继指针。它的操作和deque的可以说是一模一样。
而且list 的insert erase 这两个是O(1) 不涉及元素的移动,都是指针的改变而已。
但是其查询的效率比较低:每次都是从头结点 一个又一个的遍历才可以找到。

++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
相比较于vector 和deque list,后面两个比vector 多了一对增加删除 push_front和pop_front操作。vector不需要的原因:在头部操作,时间复杂度O(n)
顺序容器之三种容器的对比:
![]()
区别:优缺点以及各自的适用场景。(重点是:底层的数据结构,扩容方式等)
vector特点:底层是一个以2倍扩容的动态开辟的数组,内存是连续的,随着数据的增多 将会在内存上开辟一大块连续的空间。在默认定义vector< int >vec;的时候,容器底层没有开辟任何的空间,里面也没有元素。当使用push_back 或者 insert的时候,0 ——1——2——4——8——16-----
扩容带的结果:非常低的效率。原空间上的对象在新空间上进行拷贝构造,在新内存上生成新的对象。把原空间上的对象一一进行析构, 再把原来空间的内存释放。初始内存使用率太低,扩容太过频繁。 reserve 只是给vec预留空间,并没有往里面放元素。所以vec还是空的,且元素个数为0。 其作用在push_back的时候出来了,这个时候就不会再频繁的扩容了。已经预留20个空间了。这在很大程度上 效率上将是一个很大的提升。
deque的特点:动态开辟的二维数组空间,第二维是固定长度的数组空间。扩容的时候,第一维的数组进行了2倍的扩容。再把原来的第二维的数组 放在新空间的第一维数组的oldsize/2开始位置。(oldsize/2 保证可以放到新空间的正中间,方便下一次的元素进出)。其双端的 插入删除都是O(1)的操作。
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
deque的底层内存是否是连续的? 并不是
deque是一个动态开辟的二维数组,其第二维都是独立 new 出来的。每一个第二维是连续的,但是所有的第二维在一起 就不是连续的了。(分段连续的。)

++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
vector 和 deque 的区别?
(1)deque 头尾都可以插入,向上向下都可以进行扩展,O(1)。
(2)vector在元素个数越来越多的时候,会在内存上 产生一大块连续的内存空间。而且的确不需要全部的第二维空间 都在一起是连续的,只要有足够的空间块用来存放第二维空间即可把这个第二维 放在这个内存块里面,不需要太大的连续内存空间。deque的第二维默认大小 是QUE_SIZE 4096/sizeof(T)

(3)在中间进行insert erase的时候,vector和deque的效率那个会好一点?
虽都是O(n),但是相比之下 vector的移动稍微简单一些(因为其内存是完全连续的)。但是deque 删除的时候,两个第二维 的内存块不是连续的:必须先去访问一维上面的元素位(存的是要把元素移过去的第二维起始地址),然后加上一个合适的偏移量才可以到达这个元素的目标移动位置。
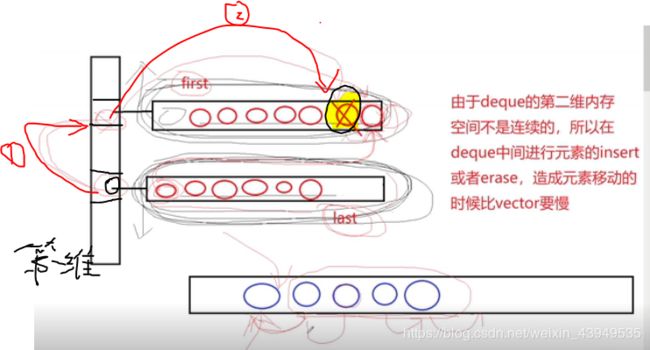
解决问题的应用场景:
前后都需要增加删除,选择deque会比较好。vector不擅长头部插入删除。

++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
vector 和 list的区别?
![]()
容器适配器
stack 其底层如下:

两个类型模板参数:第一个_Ty 表示的是 用户会传入的类型进行 实例化 stack 。第二个类型模板参数里面的container 需要我们来给它定制一个容器。当然用户什么也不传的话 默认使用deque。
其成员变量就是一个container 定义的一个容器(就是其底层的容器)。

而且这个stack的所有方法,用的都是底层容器的方法。默认情况下,就是deque的方法。这个stack的任何(栈的)方法逻辑都没有实现,只是在借助于底层容器的方法来实现 栈的逻辑。

基本上所有的适配器,都是类似于以下做法:

此时的stack ,借助于deque的在末尾增删实现栈的 出栈入栈。借助于deque的back()方法,获取尾部元素作为获取栈顶。等等(这里其实是使用到了 代理模式: stack只是代理了一下deque:stack的方法实现代理了deque的方法实现。)。

栈的常用方法如下:

队列(先进先出)的常用方法如下:队头出 队尾入

优先级队列(底层数据结构是一个 大根堆)的常用方法:
(优先级高 先出队)

出队顺序:从大到小的顺序
总结:

问题1 和 问题2:
1.vector的初始内存使用效率太低了!没有deque好 queue stack
vector 0-1-2-4-8 需要扩容
deque 4096/sizeof(int) = 1024 一次性在二维开辟的空间。deque的第二维默认大小 是QUE_SIZE 4096/sizeof(T) 不需要进行多次的内存扩容
2.对于queue来说,需要支持尾部插入,头部删除,O(1) 如果queue依赖vector,其出队效率很低:其头部删除,O(n)
3.vector需要大片的连续内存,而deque只需要分段的内存,当存储大量数据时,显然deque对于内存的利用率更好一些。
问题3:
优先级队列处理top k问题非常重要。
因为其底层数据处理为 一个大根堆结构(把这里的数据处理为 一棵树)
原因: 而且区分这个堆中的父子关系是 靠数组下标的关系进行计算的,通过下标计算之后 就可以用这个值在数组中进行访问元素。

大根堆(堆顶是根节点,其值最大)
如果要把一组数据处理为大根堆 或者 小根堆,则 父节点和子节点的关系是通过计算下标出来的,那么这就要求底层数据之间在内存上是绝对连续的(这样计算下标才有意义;如果在内存上不连续则计算下标也是无用的)。(也因为deque的内存只是分段连续,此时计算下标也没有什么用)
![]()
无序关联容器之set

set:集合(存的都是关键字)
map:映射(存的都是键值对)
无序关联容器底层是链式哈希表 ,数据是无序的;
有序关联容器底层是红黑树 ,数据是有序的
单重与多重:是否允许key重复。

这两种的操作都是一样的,只是他们的底层数据结构不一样。绝大多数使用的都是链式哈希表(无序关联容器)。但是在不仅要求快(log n),而且要求数据是有序的时候 需要使用到基于红黑树的有序关联容器。(例如:负载均衡的一致性哈希算法)
这个插入算法 insert不同于vector deque list的插入:后面三个的insert(it,val)需要两个参数:迭代器(指向的位置) 和 插入的值(在这三个数据结构中,必须指定插入位置,否则没法插入)。但是 对于关联容器而言:在hash表插入一个元素,插入位置是由hash函数决定的(不是由我们所决定的位置的)。红黑树的话,为了维护红黑树的性质,每一个元素会根据其元素的顺序都会有自己的插入位置。所以对于关联容器的insert,只需要给val即可,不需要我们指定一个指定位置的iterator,插在什么位置由数据结构决定。

size()是返回容器里面元素的个数(这里定义的是单重 集合,不允许值重复,所以插入50个数,最终只有18个是 不重复的。)
count是返回 15这个值在关联容器中的个数。(这里定义的是单重 集合,如果这个15存在的话 最多只会出现一次。如下图所示:)

如果是多重集合:则允许值重复,所以插入50个数,最终就有50个是可以重复的。如果这个15存在的话 存在几次就出现几次。如下图所示:

用iterator来遍历这个容器:

删除元素的时候:

第一种:直接通过给val值的办法 删除元素
第二种:通过iterator的方法遍历自己去找,找到之后删除。(这里连续删除的时候也需要注意iterator失效的问题)
关联容器的find()成员方法:

给定key值 20,在容器里面找看存在不存在。存在则返回指向它的iterator,不存在则返回容器的末尾iterator(即end 迭代器)。所以说 最后返回的iterator和容器的末尾iterator(即end)比较,就可以知道这个 给定key值 20存在不存在了。
C++11 的(底层也是根据iterator来实现的)

总结:

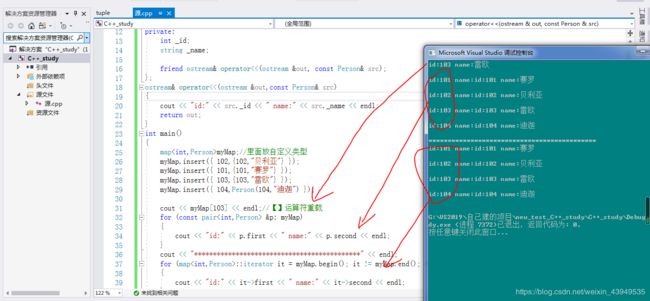
无序关联容器之map
map存的是键值对
所以在插入元素的时候,需要把这个键值对 打包成一个类型(整体 的类型)才可以(作为一个整体)插入到map中。
在这里的类型 常常是pair类型,如下:

假如此时 key是整型,val是string类型。使用make_pair方法,把键值对打包成一个pair对象整体。


struct定义的类 (其成员变量默认公有),这个类定义的对象的初始化也可以 使用
{1010,“李四”}这样的方式。于是也可以使用这个方式去进行insert。

单重映射表(也不允许key重复)。如果key重复,是不会插入到map里面的,键值对的个数也不会增加。(改成mutimap,则是可以的了 如果key重复,是会插入到map里面的,键值对的个数也会增加。) map里面存的都是一个一个的pair对象。
这里的map也提供了【】运算符的重载函数,传入一个key,就可以返回对应的val 。如下图所示:
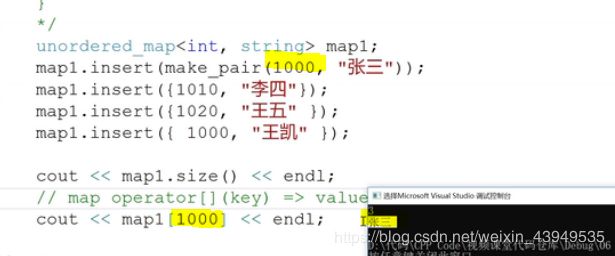


注:【】运算符重载的副作用是什么?

如最上面的那个图显示:在我查询map【2000】的时候,这个key为2000的是不存在的。但是【】运算符不只是具有查询操作的功能 ,如果这个key不存在的时候,则进行了一个 数据的插入:(这个数据的 key就是你所输入的key:2000,字符串的string类型则是默认值(调用string()构造函数,产生一个string对象))这个作为一个整体(键值对)插入到map表里面(这个可以看做是插入功能)如下图所示:。把这个插入的值val 返回值val的引用。

它还具有修改功能:如下:
例如:
![]()
这个2000 对应的不存在,于是则进行了一个 数据的插入:(这个数据的 key就是你所输入的key:2000,字符串的string类型则是默认值(调用string()默认构造函数,产生一个string对象))这个作为一个整体(键值对)插入到map表里面。 然后把那个产生的默认构造的val值:string对象的引用返还回来。 然后我们这里传入的字符串 “刘硕” 对其返回的val进行赋值。

相当于做了一个插入操作:key是2000 值是“刘硕”的键值对插入。

而上图则表示的是一个 修改 操作。因为1000 的key存在其值的对应的。然后它就把这个值val 的引用返回过来,我们用 张三2 给这个值val的引用重新赋值。相当于就把这个1000 的key对应的其值 给修改了。
于是再次查询1000 的key对应的其值 就是 张三2

find()成员方法也可以进行查询。存在则返回指向键值对的iterator,不存在则返回容器的末尾iterator(即end 迭代器)。所以说 最后返回的iterator和容器的末尾iterator(即end)比较,就可以知道这个 给定key值的键值对存在不存在了。
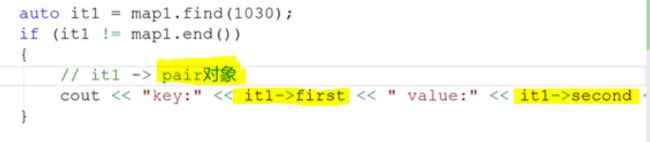
此时的 it1 指向的是pair对象(是把键值对打包起来的),把key写在 pair成员变量的first里面,把value写在pair成员变量的second里面。所以访问的时候如上图所示:。这个查询操作在O(1)。
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++什么时候用到这个hash表呢?
问题描述:

#include 
如果这里定义成普通变量,相当于把关联容器 myU_map里面的值给拷贝了一份。当然这里最好还是使用引用,但是只能定义成常引用 只能通过引用变量来遍历里面的pair对象,不可以进行对对象的修改。

使用iterator也可以进行遍历:
//使用iterator进行容器遍历
for (unordered_map<int, int>::iterator it = myU_map.begin();
it != myU_map.end(); ++it)
{
cout << "数字: " << it->first << " 出现的次数: " <<
it->second << endl;
}

更牛逼的来了:

刚才我已经介绍过了【】运算符重载函数。如果这个 k是第一次出现(我的map里面 没有出现过这个数字),则在这个map里面插入一个pair对象(key值就是传入的k,而value值 就是int()类型默认的 0)。然后把这个val值的引用返回,后置++ 则对这个引用进行+1 操作。也就是说 已经完成了map.insert({k,1}) 操作。如果这个 k不是第一次出现(我的map里面 已经存储过这个数字),则返回k对应的val值,也就是出现额次数,后置++ 则对这个val进行+1 操作。
海量数据查重,并统计重复次数的源代码如下:
#include ++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
是海量数据去重 的实现:
#include 
有序关联容器之set
有序 和 无序关联容器在实现上(代码使用上)基本上都是一样的。其差别在于 底层的数据结构不一样。有序主要是因为其底层数据结构是红黑树。

这里的insert,也是不需要指定位置的,因为红黑树知道插入位置(每一个传入的val都将会有一个合适的位置)。

输出的值个数 不足20 。原因在于: 这里是单重集合。
而且打印的数据是顺序的(生成的随机数肯定不是有序的):原因就是用中序遍历把红黑树遍历了一遍(得到了从小到大的顺序)。用迭代器iterator去遍历set容器时,是对红黑树的中序遍历的过程。对于set的元素删除 erase既可以给定it,也可以给值val,这和UNordered_set基本上差不多。
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
在set (单重集合)里面放自定义类型。
把这个Person类放到红黑树里面,怎么进行元素大小的比较呢?如何去排序呢?
可这个对象呢 编译器不知道怎么去比较小于呢?
所以必须要提供 < 运算符的重载函数。
源代码如下:
#include 运行截图:

有序关联容器之map
![]()
map的删除 可以是erase 指定位置,也可以传值删除
![]()
查询 可以使用【】运算符重载,但是【】运算符的使用会有副作用。当key不存在的时候,它会向map里面插入一个键值对。
此时这里是不需要提供 < 运算符的重载函数的,因为map排序是要 根据key排序的。这里是int 编译器知道怎么给int排序。

出错:error C2512: “Person::Person”: 没有合适的默认构造函数可用
![]()
map表需要 V有一个默认构造函数。
如上图所示:因为在key为2000 不存在的时候,会给容器插入一个key为2000 val为V()类型默认构造函数构造的V类型对象 的一个键值对。所以对于map表,V是自定义类型的时候 是需要提供一个默认的构造函数的。
本节源代码如下:
#include 运行截图:
总结:有序 和 无序操作的接口方法其实都是一样的,不同的是:从无序容器里面取数据是无序的,从有序容器里面取数据是有序的(默认 从小到大)。
迭代器iterator
迭代器都设计成了容器的嵌套类型
定义如下:

或者C++11的 auto
![]()
我们这里说的iterator是普通正向迭代器 :
正向 :打印元素的时候,从第一个直到最后一个。
普通 :可以通过 *it进行访问元素(读取it指向容器某一个位置的值),还可以进行迭代器指向的值的修改操作。
#include 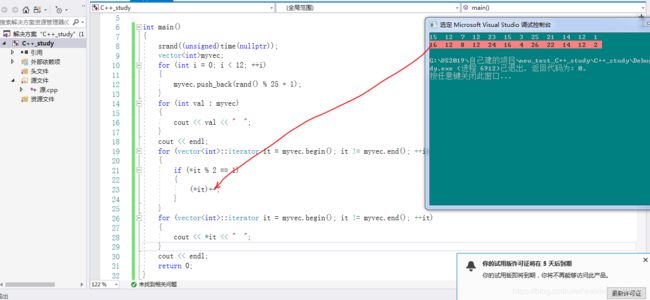
还有const_iterator 常量的正向迭代器:只能读不能写
修改上面的代码:

问题:为什么可以把右边的 iterator类型给 左边的const_iterator 类型?如下图所示:

答 : 在设计上,const_iterator 这个是基类,而iterator是从const_iterator 公有继承而来。他们之间是从上到下的继承关系。因此 用基类const_iterator 类型定义的对象当然是可以接收 派生类对象的。

返回的是常引用,当然不可以再进行赋值操作。如上图所示:

而派生类的 * 运算符重载返回的不是常引用当然可以进行赋值,可以去修改所指向元素的值。
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
反向迭代器:reverse_iterator


//反向迭代器
for (vector<int>::reverse_iterator rit = myvec.rbegin(); rit != myvec.rend(); ++rit)
{
cout << *rit << " ";
}
cout << endl;
正好可以看到 读取元素的顺序恰好是相反的。而且这个 rit也是可以进行 解引用修改指向元素的值的。
当然也有const_reverse_iterator 只能读的反向 常量迭代器
函数对象
![]()
函数对象可以完成的,C的函数指针也可以完成。那么为什么C++不继续使用函数指针而是去另外的函数对象呢?

在C中 :sum是一个地址:一个函数名。
在CPP中:sum是一个对象。

sum作为对象,调用自己的()运算符重载函数。把10 20作为实参传入这个sum对象调用的()运算符重载函数。

那么使用函数对象的优点在哪里?

上面两个都能正确进行,但是使用上不是很灵活
需求: 假如 现在要进行 小于的比较 那么
(1)直接修改源代码吗?
(2)再提供一份进行 小于的比较 的模板函数?
不太合适 也没必要
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
解决方案1:
#include 
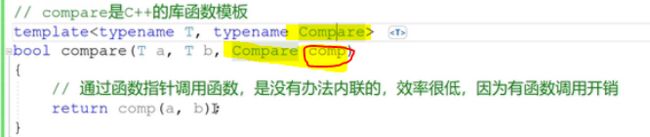
compare是C++的库函数模板,其功能是要随着用户传入的参数进行改变的。所以这里不可以直接把 小于的比较 大于的比较 给写死了。所以这里除了接收传入的类型,还要接受一个函数指针Compare。现在把a b作为当做是这两个函数指针的参数传进来。如下:
//compare是C++的库函数模板
template<typename T,typename Compare>
bool compare(T a, T b,Compare comp)
{
return comp(a, b);//现在把a b作为当做是这两个函数指针的参数传进来。
}
最后返回comp(a, b)的返回值。
在main函数里面调用的时候
less< int > 这个是函数名,于是就在上面代码里面 传进去了一个 函数地址。就在其中,(推导)配套出来一个函数指针类型(指向myless 和 mygreater),然后在:
return comp(a, b);
相当于用 函数指针 间接调用myless 和 mygreater函数。
![]()
内联是发生在编译阶段的,就算是myless 和 mygreater函数 处理为inline函数,在调用处:
return comp(a, b);
是不知道调用的是myless 和 mygreater这两个inline函数的,这里是用 函数指针 间接调用myless 和 mygreater函数的。编译器在编译过程中看见这个comp(a, b) 函数指针的时候,是不知道调用的哪个函数。只有在运行的时候,才会到comp(a, b) 所代表的函数地址上去 执行指令(运行函数)的。这里标准的函数调用开销是少不了的。

+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
解决方案2:
C++的函数对象
此时的Mygreater Myless 实例化以后,产生的对象叫做 函数对象。(类里面()运算符重载函数)
此时传入的是对象:如下

不再是两个函数的地址。Myless< int >()和Mygreater< int >()是函数对象。
那么此时推到出来的就是 Mygreater Myless 类型的对象。在return comp(a, b);
此时是知道调用的是函数,就是在用对象调用Mygreater Myless 类型的 operator()运算符重载函数。在编译阶段,在return comp(a, b); 处是已经可以知道 是在调用 具体对象的具体函数。这里使用inline是非常合适的,省去标准的函数调用开销,调用效率非常高。

总结:

在这里可以通过传入不同的函数对象(Mygreater或者 Myless 类型对象),可以改变这个泛型算法的操作(大于 小于)。
类里面()运算符重载函数的参数有几个:就可以叫做 几元函数对象。(例如上面:二元函数对象)
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
优先级队列 底层默认的数据结构是vector容器实现的大根堆操作。海量数据找 top k大的是用小根堆,海量数据找 top k小的是用大根堆。
需求:如果这里需要的优先级队列是个小根堆 怎么办?
例如:

默认是 大根堆(数据 从小到大。堆顶放的是最大的数据)
(小根堆:数值越小 优先级越高 先出队)
priority_queue的底层实现如下:三个类型模板参数
第一个:元素的类型
第二个:底层所依赖容器的类型(默认 vector)
第三个:函数对象(默认 less,得到的就是数值越大 优先级越高)
因为其底层(大小根堆)需要元素的比较,但是人家底层并没有写成(大于号 小于号)。而是通过 传入一个函数对象,可以更改底层排序的方式。
如果要改第三个函数对象,则需要把前两个也手动写上。
#include 
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
set 底层是红黑树,默认也是从小到大 进行元素的输出

第二个参数:
可以改变红黑树比较元素的方式,可以把这个参数改成greater

此时是 从小到大。
代码:
#include 泛型算法和绑定器
注:泛型算法的参数接收的都是迭代器:原因是泛型算法(用模板实现的)是给所有容器使用的(通用的),所以这个算法需要一个统一的方式把所有容器里面的元素遍历一遍。 而iterator可以把所有容器的元素遍历一遍,且代码风格还可以保持一致(用iterator遍历容器的方法都是一模一样的)。
注:泛型算法的操作结果取决于传入的不同的参数而有所不同(例如:它可以接收函数对象) 。因此 如下图所示:
![]()
这些泛型算法的使用 可以大量的节省代码量。很是方便。
#include find 和 binary_search的效率比较:前者O(n) 后者O(log n)
binary_search高。而find 是从找到尾,有则返回it,无则返回end()。

find_if是按照条件进行查询的
需求:
//当前顺序:从大到小 133 96 86 63 54 46 45 37 35 25 23 2
//现在要把55按照顺序插入到里面(从头找比 第一个 比55小的,即:54),然后插在54处
//这里传入的函数对象:greater对象一次 需要从容器里面取出1个元素进行比较
上面使用的 Mygreater< int >()或者使用greater< int >() 这都是二元函数对象,在排序时,greater对象每次比较 需要从容器里面取出2个元素进行比较 。

因为在greater 的()运算符重载函数需要传入两个参数。
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++而find_if是在容器中,找第一个小于55 的元素,这里使用到的函数对象则 需要从容器里面取出1个元素进行比较 ,这里需要容器传入1个参数即可(因为另一个 55 这是确定的)。可是库里面没有一元函数对象。
所以这里需要使用到 绑定器

这里把 第一个(第二个)参数给绑定起来(外面只需要传入一个实参即可),二元函数对象于是就成了一元的了。
![]()
这里 greater比较的是 大于,lessr比较的是 小于。现在需求是找到第一个小于55 的元素。 如果这里我们使用greater,应该把容器里面的元素传入b,把a给绑定起来(55)。 这里把greater的 第一个参数给绑定起来55 。


因此 相当于此时的a就是55,find_if 把每一个容器的元素依次都传给 这个绑定器绑定完成的一元函数对象上,即不断地传给b。find_if 找到则返回 iterator,没有则返回end()。find_if 其第三个参数需要的是一个一元的函数对象(这个函数对象调用自己的小括号运算符重载函数,每次从容器中取一个元素和这个55比较),上面的55 是固定的。

使用less 也是可以的。如果这里我们使用less,应该把容器里面的元素传入a,把b给绑定起来(55)。 这里把less的 第二个参数给绑定起来55 。
vector<int>::iterator it3 = find_if(myvec.begin(),
myvec.end(), bind2nd(less<int>(), 55));
myvec.insert(it3, 55);
for (vector<int>::iterator it = myvec.begin();
it != myvec.end(); ++it)
{
cout << *it << " ";
}
cout << endl;

++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
在C++ 11中,降低难度(绑定器和函数对象的)。lambda表达式:其底层就是一个函数对象的实现

vector<int>::iterator it3 = find_if(myvec.begin(), myvec.end(),
[](int val)->bool {return val < 55; });
这句 看似是在写lambda表达式,其实就是一个函数对象的实现。需要一个一元函数对象。【】的作用就是捕获外部变量,()相当于形参变量。bool相当于函数对象()运算符重载的返回类型。现在需求是找到第一个小于55 的元素。此刻的val 是find_if 传给lambda表达式(或者说 函数对象)的实参。和55 比较,找到了则返回true,就找到了第一个小于55 的元素位置的iterator。

for_each的第三个参数:是函数对象(或者传入lambda表达式)。相当于用iterator去遍历容器的每一个元素,然后把每个元素的值传给函数对象。所以这里面也需要一个一元的函数对象。

for_each(myvec.begin(), myvec.end(), [](int val)->void
{
if (val % 2 == 1)
cout << val << " ";
});
cout << endl;

使用lambda表达式的 一个好处就是:
为了解决这个需求:没必要为了 for_each 过滤这个奇数去 特意在外部写上一个类,然后在类里面写 ()运算符重载函数,然后创建一个函数对象使用。
注: 在泛型算法(算法调用过程中)传入一个lambda表达式 作为函数对象。lambda表达式比(绑定器+函数对象)好用多了
2019年7月20日 10:58