链家网租房信息数据分析——从爬虫到房租预测
链家网租房信息数据分析——从爬虫到房租预测
- 前言
- 数据爬取
- 思路
- 爬虫代码
- 数据洞察
- 通过百度api获取地址经纬度
- tableau可视化
- 词云制作
- 房租预测
- 数据预处理
- 拆分测试集
- 数值型变量标准化
- 分类变量OneHotEncoder编码
- 文本特征抽取
- 转化流水线
- 模型训练
- 随机森林
- xgboost
- 预测数据
- 测试集
- 迭代
- 自己的房屋数据
- 小结
前言
只身一人来到异地工作,首当其冲考虑的是住宿问题。如果公司有提供住宿当然最好,但大多时候还是需要我们自己去租房子。可是作为人生地不熟的异乡人,往往对当地租房市场难以有清晰的洞见,也担心自己被房东或中介当了猪宰。现在你可以稍安勿躁了,本文将运用python爬虫,sklearn包,以及tableau可视化工具,从数据获取到最终的结果呈现,对当地的租房价格做深入浅出的分析和预测,助你找到称心如意的房子。同时也是我自己数据分析学习的一个小结。
数据爬取
思路
由于链家网的反爬手段比较温和,只要不太过分地爬取,一般不会被ban(本文写作阶段博主还没被其ban过),我们选择链家网进行租房信息的爬取。
由于博主现住上海,就以上海的信息为例。这是上海的网址链接:
https://sh.lianjia.com/zufang/
如果我们切换成其他城市,比如北京,html会变成:
https://bj.lianjia.com/zufang/
可以发现html只有很小的改变,由sh变成了bj,也就是城市的拼音缩写
继续观察,不出意外,我们应该位于链家租房页面的第一页,而拉到底后会发现,一共有100页,那么我们随便点一页,看看网址的变化。
没错,网址变成了:
https://sh.lianjia.com/zufang/pg{你点击的页数}/#contentList
我们将末尾的#contentList去掉后,网址依然可以使用
同理,https://sh.lianjia.com/zufang/pg1/ 也能进入我们最开始的首页
那么我们可以得知,链家租房网页的html结构基本就是这样:
https://{city}.lianjia.com/zufang/pg{number}/
但是还有一个很严重的问题,相信细心的同学已经发现了,链家租房信息一共只有100页,而每页的信息只有30条,一共也就是3000条。而上海的租房信息首页上却显示一共有20000+条。那么怎么把这20000多条全部爬下来呢。这时候我们看看首页的上面还有什么,没错,区域!。对区域加以限制后可以发现,各个区域的租房信息依然最多能有100页信息,也就是3000条。而只有浦东区是超过3000条的,竟然达到了6890条!看来近几年浦东的发展势头很好呀。
结合起来,包含区域的网址结构则为:
https://{city}.lianjia.com/zufang/{region}/pg{number}/
所以我们可以依不同区域,将各区域的100页网址信息全部爬取下来,再对每一页网址信息进行处理,将每一页网址30条信息(if reaching)的网址爬下来。
对于超过3000条的浦东区,可以再进一步,同按区域爬取的思路一样,按租金进行爬取。这样不同租金的网址结构就变成了:
https://{city}.lianjia.com/zufang/{region}/rp{number}/pg{number}/
获取到所有网址信息后,在进入每一个网址,获取该住房的详细信息。好了,废话不多说,show u my code.
爬虫代码
这里只用了requests和BeautifulSoup库,而且是简单的单线程爬取,跟博主类似的新手应该也能看懂。
# -*- coding: UTF-8 -*-
# 导入需要的各种库
import re
import time
import requests
from random import uniform
from bs4 import BeautifulSoup
import pandas as pd
from sqlalchemy import create_engine
import pymysql
# 设置一个请求头,不然无法通过链家的验证
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36'}
def get_parent_url(city):
"""
获取选定城市的所有父母网址
:param city:
:return:
"""
url = 'http://{city}.lianjia.com/zufang'.format(city=city)
html = requests.get(url, headers=headers) # 获取网址html
Soup = BeautifulSoup(html.text, 'lxml') # 解析html
Selector = Soup.select('ul[data-target="area"] > li.filter__item--level2') # 找出html中的区域文本
Selector = Selector[1:] # 排除第一个区域“不限”
url_parent_all = [] # 初始化最终的父母网址列表
for i in Selector: # 对每一个区域进行loop
url_region = "https://sh.lianjia.com" + i.select('a')[0]['href'] # 找出区域网址
html_region = requests.get(url_region, headers=headers) # 获取区域网址html
Soup_region = BeautifulSoup(html_region.text, 'lxml') # 解析html
number_data = int(Soup_region.select('span.content__title--hl')[0].text) # 获取该区域信息条数
if number_data <= 3000: # 信息条数少于3000直接开始爬取
index = Soup_region.select('div.content__pg')[0] # 找出页数文本
index = str(index) # 将bs4对象转换为str,否则无法进行正则提取
re_set = re.compile(r'data-totalpage="(.*?)"')
index = re.findall(re_set, index)[0] # 正则表达式提取出页数
for j in range(1, int(index)+1): # 对每一页网址进行循环
url_parent = url_region + "pg{}".format(j)
url_parent_all.append(url_parent) # 得到该区域每一页的网址,并添加至父母网址列表中
print(url_parent)
t = uniform(0, 1)
time.sleep(t) # 每爬一个区域,稍作等待,避免被ban
else: # 信息条数大于3000按租金分层
for i in range(1, 8):
url_region_rp = url_region + "rp{}/".format(i)
html_region_rp = requests.get(url_region_rp, headers=headers)
Soup_region_rp = BeautifulSoup(html_region_rp.text, 'lxml')
index = Soup_region_rp.select('div.content__pg')[0] # 操作同上
index = str(index)
re_set = re.compile(r'data-totalpage="(.*?)"')
index = re.findall(re_set, index)[0]
for j in range(1, int(index) + 1):
url_parent = url_region + "rp{}/".format(i) + "pg{}".format(j)
url_parent_all.append(url_parent)
print(url_parent)
t = uniform(0, 1)
time.sleep(t)
return url_parent_all
def get_detail_url(url_parent_all):
"""
对每一个父母网址进行操作,获取最终详尽的子网址列表
:param city:
:return:
"""
url_detail_all = [] # 创建最终的子网址列表
for url in url_parent_all: # 对每一个父母网址进行for loop
html = requests.get(url, headers=headers)
Soup = BeautifulSoup(html.text, 'lxml')
Selector = Soup.select('div a.content__list--item--aside') # 解析并找出子网址bs4对象
for i in Selector:
i = i['href']
i = 'http://{city}.lianjia.com'.format(city=city) + i # 对每一个bs4子网址对象循环,构建最终的子网址
url_detail_all.append(i) # 添加到子网址列表
print(i)
t = uniform(0, 0.01)
time.sleep(t) # 每处理一条父母网址暂停t秒
return url_detail_all
def get_data(url_detail_all):
"""
从子网址列表中网址获取数据
:param url_detail_all:
:return:
"""
data = [] # 初始化一个爬虫数据列表
num_error = 0 # 记录错误数
for i in url_detail_all: # for loop对每一个网址进行爬取操作
try: # 使用try...except...方法防止循环中途出错退出
info = {}
url = i
html = requests.get(url, headers=headers)
Soup = BeautifulSoup(html.text, 'lxml')
info['房源编号'] = Soup.select('i.house_code')[0].text
info['链接'] = i
info['标题'] = Soup.select('p.content__title')[0].text
info['价格'] = Soup.select('p.content__aside--title')[0].text
Selector1 = Soup.select('p.content__article__table')[0].text.split('\n')
info['租赁方式'] = Selector1[1]
info['户型'] = Selector1[2]
info['面积'] = Selector1[3]
info['朝向'] = Selector1[4]
info['发布时间'] = Soup.select('li[class^="fl oneline"]')[1].text[3:]
info['入住'] = Soup.select('li[class^="fl oneline"]')[2].text[3:]
info['租期'] = Soup.select('li[class^="fl oneline"]')[4].text[3:]
info['看房'] = Soup.select('li[class^="fl oneline"]')[5].text[3:]
info['楼层'] = Soup.select('li[class^="fl oneline"]')[7].text[3:]
info['电梯'] = Soup.select('li[class^="fl oneline"]')[8].text[3:]
info['车位'] = Soup.select('li[class^="fl oneline"]')[10].text[3:]
info['用水'] = Soup.select('li[class^="fl oneline"]')[11].text[3:]
info['用电'] = Soup.select('li[class^="fl oneline"]')[13].text[3:]
info['燃气'] = Soup.select('li[class^="fl oneline"]')[14].text[3:]
info['采暖'] = Soup.select('li[class^="fl oneline"]')[16].text[3:]
info['房源标签'] = Soup.select('p.content__aside--tags')[0].text[1:-1].replace('\n', ', ')
Selector2 = Soup.select('li[class^="fl oneline"]') # 获取配套设施的bs4对象
info['配套设施'] = []
for i in Selector2: # 对每一个对象进行处理
if len(i['class']) > 2:
if i['class'][2][-2:] != 'no': # 仅保留有的配套设施
info['配套设施'].append(i['class'][2])
info['配套设施'] = ",".join(info['配套设施']) # 列表转换为str
if info['配套设施'] == '': # 配套设施为空的情况
info['配套设施'] = None
if not Soup.select('.threeline'): # 房源描述为空的情况
info['房源描述'] = None
else:
info['房源描述'] = Soup.select('.threeline')[0].text
info['城区'] = Soup.select('p.bottom__list--item__des > span:nth-of-type(1) > a:nth-of-type(1)')[0].text
info['小区地址'] = Soup.select('p.bottom__list--item__des > span:nth-of-type(1)')[0].text.replace(' ', '').replace('\n', '')
data.append(info) # 将爬取的信息以字典形式添加到数据列表中
print(info)
t = uniform(0, 0.01)
time.sleep(t) # 爬一条数据暂停t秒
except:
num_error += 1
print("oops, some errors occured")
continue
print("出错数据行数: %d" % (num_error))
df = pd.DataFrame(data) # 将数据转换为DataFrame
return df
def to_mysql(df, table_name):
"""
将爬取的数据保存到mysql中
:param df:
:param table_name:
:return:
"""
# 创建连接mysql的engine,以pymysql为driver
engine = create_engine('mysql+pymysql://root:yu7233991yu@localhost:3306/lianjia', encoding='utf-8')
# 将传入的df保存为mysql表格
df.to_sql(name='{}'.format(table_name), con=engine, if_exists='replace', index=False)
def to_csv(df, table_name):
"""
将爬取的数据保存到csv文件中
:param df:
:param table_name:
:return:
"""
df.to_csv('{}'.format(table_name), index=False) # 不保留行索引
if __name__ == '__main__':
city = input("输入要爬取的城市拼音缩写(小写): ")
# city = 'sh'
url_parent_all = get_parent_url(city)
url_detail_all = get_detail_url(url_parent_all)
all_url = pd.DataFrame(url_detail_all, columns=['url'])
to_mysql(all_url, '{}_all_url'.format(city))
to_csv(all_url, '{}_all_url'.format(city))
home_df = get_data(url_detail_all)
to_mysql(home_df, '{}_home_data'.format(city))
to_csv(home_df, '{}_home_data'.format(city))
运行后,会提示输入需要爬取的城市,这里我们输入上海的缩写'sh',就可以开始爬取链家网上20000+条关于上海租房的信息了。

图1. Pycharm中正在爬取的数据
根据网速不同,20000+数据全部爬下来大约需要3~6小时,时间有点长,我们可以喝杯冰阔乐慢慢等着。无奈,博主目前还不会分布式爬虫这类高级技术,不然应该可以大大加快爬取速度,只能以后再学习吧。
这里我一共爬取了27000+条信息,每条信息收集了24个详细数据。按照惯例,给大家展示一下我爬好的数据。
 图2. 爬取好的20000+条数据
图2. 爬取好的20000+条数据
数据洞察
获取数据后,第一件事就是对数据进行清洗。这里繁琐的清洗过程就不赘述了,主要讲讲怎么通过百度地图api获取每条租房信息的经纬度。
通过百度api获取地址经纬度
首先我们要去百度地图官网获取百度api的授权,具体申请细节就不介绍了,百度上都有。建议最好申请一个开发者认证,这样我们每天转换的地理编码的配额可以得到很大提升,基本可以满足小型数据分析的要求。
接下来就是使用这个api接口的代码。
# 利用百度地图api将小区地址信息转换为经纬度,方便我们后续的作图和预测
from urllib.request import urlopen, quote
import json
# 转换的小函数
def address2lnglat(address):
url = 'http://api.map.baidu.com/geocoder/v2/'
address = quote(address) # 防止中文地址导致乱码,先用quote方法编码
output='json'
ak = 'GF0WNG******************8KwATPvb' # 你申请的ak
uri = url + '?address=' + address + '&output=' + output + '&ak=' + ak
req = urlopen(uri)
res = req.read().decode()
temp = json.loads(res)
lng = temp['result']['location']['lng']
lat = temp['result']['location']['lat']
return lng, lat
比如,我随意地传入一个地址
address = '杨浦-中原明丰阳光苑'
lng, lat = address2lnglat(add)
print(lng, lat)
返回的结果为:
121.5357165996346 31.304510479541904
tableau可视化
收集完住房地址的经纬度并完成繁琐的数据清洗后,我们先大致看看都有哪些数据。
df = pd.read_csv('E:/develop_python/lianjia/sh_home_data_wrangled')
df.info()
RangeIndex: 24856 entries, 0 to 24855
Data columns (total 28 columns):
价格 24856 non-null int64
入住 24856 non-null object
发布时间 24856 non-null float64
城区 24856 non-null object
小区地址 24856 non-null object
户型 24856 non-null object
房源描述 13713 non-null object
房源标签 5631 non-null object
房源编号 24856 non-null object
朝向 24856 non-null object
标题 24856 non-null object
楼层 24856 non-null int64
燃气 24856 non-null object
用水 24856 non-null object
用电 24856 non-null object
电梯 24856 non-null object
看房 24856 non-null object
租期 24856 non-null object
租赁方式 24856 non-null object
车位 24856 non-null object
配套设施 5608 non-null object
链接 24856 non-null object
面积 24856 non-null int64
室数 24856 non-null int64
厅数 24856 non-null int64
卫数 24856 non-null int64
经度 24856 non-null float64
纬度 24856 non-null float64
dtypes: float64(3), int64(6), object(19)
memory usage: 5.3+ MB
接下来直接打开tableau软件,用它的仪表盘(Dashboard)组合图表,对数据进行可视化探索。

图3. 房租、面积、房间数的分布和关系图
首先想想我们的目标是什么?没错,房租!那么,与房租最相关的一个特征是什么呢?有的同学会认为是地域,比如说北上广的房价上天,而三线内陆省市则相对便宜,这也有一定道理。但我们今天只爬取了上海市这一个地区的租房信息,就先不考虑地域因素了。剩下来首当其冲的,小伙伴们一定很容易想到,就是住房的大小,也就是面积了。面积越大的房子卖的越贵,这是常识,租房也同理。先看看面积和房租的分布和相关性图(绿色部分),很明显房租和面积间呈显著正相关,在tableau做出的趋势线上显示其决定系数R^2 = 0.44。
另一方面,爬取的数据中还存在各房屋室、厅、卫房间数,很自然可以联想到房间数越多的屋子面积也越大,右下角的折线图正好反映了这一趋势。从这一点可以洞见,房间数和住房的面积有很强的正相关性,导致两种特征间难以相互独立,在对房租进行建模预测时存在较大的特征重合。这虽然不会影响最终的性能,但可能会拖慢模型训练速度。好在我们的特征并不太多,数据集也不是很大,可以不对这种存在较强相关性的特征进行预处理(如果需要,可以对特征进行PCA降维,但最终会损失少量的模型性能)。

图4. 经纬度、楼层、发布时间的分布和关系图
除了面积,跟房价息息相关的还有地段。好的地段比如东方明珠塔下,外滩沿儿上,那房租定是高不可攀。而较远离市中心的入松江、嘉定一带,房租则相对便宜。而经纬度就起到了精确定位房屋地段的功能。从经纬度的分布来看,并不是很连续,而是呈离散抱团趋势,这与日常生活中的居民区,生活小区概念不谋而合,一块地段适宜居住,住房就倾向在这里成团出现,其他位置则相对较稀疏。而经纬度和房租的散点图整体上成金字塔形,说明在经纬度较集中的位置,估计就在黄浦、静安附近的市中心位置,房租价格有一个较大的攀升。
此外,另外两个数值型变量,楼层和发布时间也做了简单的探索。楼层分布在5-6楼处有一个较小的峰值,说明该楼层的租房提供量较大。而发布时间则是近一个月内发布的租房数最多,随时间缓慢下降,这很好理解,发布时间较长的房屋都已经被租出去了嘛。但在发布时间上还有一个小细节,就是时间较长的房屋房租相对较高,原因正是它本身的高租金,使得难以租出,滞留时间变长,这也对房租预测有一定意义。而房租在整体上随楼层增加有上升趋势,推测是高楼层多是新修,带电梯,本身造价就高的精品房。
估计看了这么多dot, line and bar,同学们可能有点犯困了,反正我做这些图的时候是困的不行。但是接下来才是重头戏,一副漂亮的热力地图!
图5. 上海市区内房租热力地图
看到这张图的第一眼我就爱上了她,热力地图真是人类伟大的发明!
图中的方块大小表示该地区的租房数量,颜色表示房租高低。很直观地可以看出,黄浦、静安的房子多是辣眼睛的红色,房租中值就达到了13000。而偏绿色这些区域房租中值在4000~6000范围内徘徊。最便宜的奉贤只要2400,但代价是,你在这张市区内的地图上根本看不到它。
可惜blog里只能插入这种静态图片,如果能直接在tableau软件内进行交互式操作,可以得到更好的体验。比如,这里我点击房屋数量最多的浦东。
图6. 浦东新区房租热力地图
可以看到,浦东地区被高亮显示,其他地区则被隐藏。从浦东的房屋位置分布来看,靠近东方明珠的地段房租成红色,较远的川沙和周浦地段则成绿色。同时,房屋也大多分布在沿江一带,其他地段值有少量的聚落。

图7. 分类变量与房租的关系(条形图中颜色深浅与蓝色柱高度表示价格中值,数字和灰色柱高度表示房屋数量;气泡图中大小表示房屋数量,数字表示价格中值)
除了数值型变量外,数据中还包含许多分类变量,比如房屋朝向,租期,看房限制等。通过条形图和气泡图可以洞见不同类别的数量和与房租的关系。例如西南朝向的房租最高,但朝南的房屋数量最多;2~3年的长租租金最贵而1年以内的短租数量最多;大部分房屋看房需要提前预约,而只能在周末看房的房源租金最贵,从心里学上来分析,只能在周末看房的房东大多工作繁忙,忙着挣钱,因此想要在房租上获取更高的收益也就顺理成章。其他二分类的特征,数量上占多数的分类在租金上也都更贵。这些变量都对后续预测模型的建立有或多或少的影响。
词云制作
除却数值变量和分类变量之外,还有一类变量称之为文本变量,大多为含多个单词或句子的字符串。这里体现在房源描述,房源标签和配套设施3个特征上。在机器学习预处理中,对较简单的房源标签和配套设施做TF-IDF矢量化处理,而房源描述由于处理较困难,在预处理中暂时只做分类,分为有描述和无描述两类。从图7的气泡图中可见,有描述的房源租金中值为7000,而无描述的则为5100,存在和房租的相关性。
说了这么多,我们不可能只把辛苦爬下来的占空间最大的房源描述就只当作分类变量处理吧,那也太浪费了。由于长文本是制作词云的良好素材,这里我们可以将房源描述制作成漂亮的词云,从中获得直观的洞见。直接先上成果吧。
图8. 房源描述词云
地铁,采光,超市,方便,医院,公交,广场······这些文字会在第一时间映入你的脑海,给你一个直观的感觉——they are important!
没错,词云中最显眼的单词就是文本中出现频率最高的单词,在我们的房源描述里,是房东最想让租客了解到的信息。换句话说,也就是房源最吸引租客的一些关键词。地铁,公交,步行说明房源的交通方便与否,生活,便利,超市,菜市场,银行,公园,广场是房源的生活便利程度,采光,朝南,精装修,楼层这些则涉及房源的户型,装修等本身质地,其他更多的词,不一而足。这些信息都是租客最关注的,或者说最优先考虑的。条件满足得越多的房源,租住的价值也就越高。
那么怎么制作这样一份词云呢?这里主要使用了wordcloud包来绘制,jieba包来进行中文分词,代码如下。
# -*- coding: UTF-8 -*-
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from wordcloud import WordCloud
import jieba
class ellipse(object):
## 绘制词云mask使用的椭圆背景,使用numpy和椭圆函数绘制椭圆形栅格矩阵
def __init__(self, a, b):
self.a = a
self.b = b
def get_ellipse(self):
y, x = np.ogrid[:800, :800]
mask = (x-400)**2/self.a**2 + (y-400)**2/self.b**2 > 400**2
mask = 255 * mask.astype(int)
return mask
def get_image(self, style=plt.cm.gray):
mask = self.get_ellipse()
plt.axis('off')
plt.imshow(mask, cmap=style, interpolation='bilinear')
plt.show()
class house_desc(object):
def __init__(self, df_path, column):
self.df_path = df_path
self.column = column
def get_jieba_txt(self):
df = pd.read_csv(self.df_path)
Series = df[self.column]
list_txt = Series.dropna().tolist()
pre_txt = ' '.join(list_txt).replace(',', ' ').replace(',', ' ')
add_words = ['拎包入住', '南北通透', '看房方便', '随时看房', '家具家电', '生活便利', '世纪大道', '家电齐全', '干净整洁',
'设施齐全', '生活广场', '人民医院', '联华超市', '生活方便', '主卧朝南', '人车分流', '采光通风', '视野开阔',
'看房随时', '购物商场', '多条公交线路', '南京西路', '购物方便', '居住舒适', '巴黎春天', '一厨一卫', '一室一厅',
'一家人居住', '多路公交', '仁济医院', '所在位置繁华', '家电家具', '方便生活', '公交线路经过', '万达广场',
'长寿公园', '体育公园', '生活设施', '小吃一条街', '欢迎入住']
for word in add_words:
jieba.add_word(word)
jieba.del_word('地铁站')
seg_list = jieba.cut(pre_txt)
jieba_txt = ' '.join(seg_list)
print(jieba_txt)
return jieba_txt
def paint_word_cloud(self, mask):
image = mask
jieba_txt = self.get_jieba_txt()
font = 'C:/Windows/Fonts/simkai.ttf'
stop_words = {'房源', '亮点', '描述', '此房', '介绍', '原因', '房东', '号线', '就是', '东门', '北门', '旁边', '业主',
'房子', '出租', '周边', '配套', '装修', '交通', '出行', '上海', '可以', '即可', '到达', '数据', '来源于',
'一兆', '韦德', '租客', '到期', '来自', '百度', '所以', '位于', '公里', '内部', '希望', '城市', '有限公司',
'适合', '出来', '地下', '便是', '直接', '小时', '两个', '充足', '小区', '出门', '距离', '户型', '两房',
'一房', '比较', '高德', '地图', '百度', '中间', '提供', '直达', '同意', '里面', '十分', '门口', '欢迎',
'二房', '正气', '一个', '满足', '各种', '多条', '一条街', '自己', '米左右', '三房', '之前', '目前', '以及',
'左右', '本房', '不错', '等等', '需求', '现在', '上海市', '自带', '路上', '选择', '入住', '属于', '号口'}
wordcloud = WordCloud(font_path=font, scale=6, stopwords=stop_words, mask=image,
background_color='white', max_words=200, collocations=False,
max_font_size=None, min_font_size=10
)
wordcloud.generate(jieba_txt)
wordcloud.to_file('房源描述词云_single.png')
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()
if __name__ == '__main__':
ellipse = ellipse(a=1, b=.8).get_ellipse()
path = 'E:/develop_python/lianjia/sh_home_data_wrangled'
column = '房源描述'
house = house_desc(df_path=path, column=column)
house.get_jieba_txt()
house.paint_word_cloud(mask=ellipse)
房租预测
一切准备妥当,终于可以开始房租预测模型的训练了。在训练开始之前,必须对数据进行预处理,转换为sklearn包内的模型可以"吃"进去的数据类型,也就是ndarray。
数据预处理
本文对于数据的预处理主要包括4部分。在开始之前,先看看房租,面积与各数值特征间的线性相关系数。
corr_matrix = df.corr()
corr_matrix['价格'].sort_values(ascending=False)
价格 1.000000
面积 0.696700
卫数 0.581905
室数 0.463068
厅数 0.395391
楼层 0.284681
发布时间 0.166492
经度 0.024470
纬度 -0.011403
Name: 价格, dtype: float64
corr_matrix['面积'].sort_values(ascending=False)
面积 1.000000
卫数 0.803072
室数 0.760961
价格 0.696700
厅数 0.602565
发布时间 0.304255
楼层 0.074779
经度 0.032451
纬度 -0.014304
Name: 面积, dtype: float64
与我们之前的分析类似,价格与面积线性相关系数较高,而面积则与房间数息息相关。
拆分测试集
为了减少抽样的不均匀,采用分层随机抽样。由于房租与面积最相关,按照面积将数据集拆分为4层。
def save_fig(fig_name, tight_layout=True, fig_extension="png", resolution=600):
path = os.path.join('C:/Users/Yc/Desktop', fig_name + "." + fig_extension)
print("Saving figure", fig_name)
if tight_layout:
plt.tight_layout()
plt.savefig(path, format=fig_extension, dpi=resolution)
sns.set(style='whitegrid', font=['KaiTi', 'Arial'], palette='muted', color_codes=True)
plt.hist(df['面积'], bins= 200)
plt.xlim(0, 200)
plt.show()
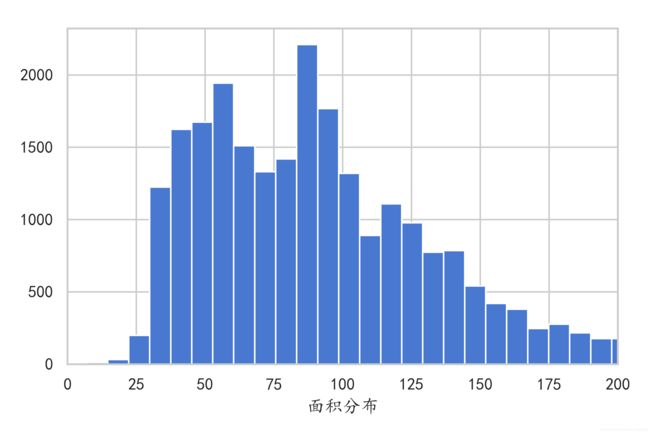
图9. 住房面积分布
df['area_cat'] = np.ceil(df['面积']/50)
df['area_cat'].where(df['area_cat']<4, 4, inplace=True) # 超过200平米的均分为第4层
plt.hist(df['area_cat'])
plt.xlabel('面积分层')
plt.show()

图10. 按面积分层数据集
# 按面积分层抽样拆分测试集
from sklearn.model_selection import StratifiedShuffleSplit
split = StratifiedShuffleSplit(n_splits=1, test_size=.2, random_state=27)
for train_index, test_index in split.split(df, df['area_cat']):
strat_train_set = df.loc[train_index]
strat_test_set = df.loc[test_index]
for set in (strat_train_set, strat_test_set):
set.drop(['area_cat'], axis=1, inplace=True)
df.drop(['area_cat'], axis=1, inplace=True)
# 删去分层项
X_train = strat_train_set.drop(['价格'], axis=1)
y_train = strat_train_set['价格'].copy()
X_test = strat_test_set.drop(['价格'], axis=1)
y_test = strat_test_set['价格'].copy()
数值型变量标准化
# 训练集拆分为数值型,分类型,文本型三类特征
X_num = X_train[['面积', '室数', '厅数', '卫数', '经度', '纬度', '发布时间', '楼层']]
X_cat = X_train[['城区', '朝向', '租赁方式', '房源描述', '入住', '燃气', '用水', '用电', '电梯', '看房', '租期', '车位']]
X_txt = X_train[['房源标签', '配套设施']]
# 将数值型数据标准化
from sklearn.preprocessing import StandardScaler
std = StandardScaler()
X_std = std.fit_transform(X_num)
分类变量OneHotEncoder编码
from sklearn.preprocessing import OneHotEncoder
hotter = OneHotEncoder(sparse=False)
X_hot = hotter.fit_transform(X_cat)
文本特征抽取
from sklearn.feature_extraction.text import TfidfVectorizer
tfi1_vector = TfidfVectorizer()
X_tfi1 = tfi1_vector.fit_transform(X_txt['房源标签'])
tfi2_vector = TfidfVectorizer()
X_tfi2 = tfi2_vector.fit_transform(X_txt['配套设施'])
转化流水线
以上对三种变量的转换其实可以用流水线一步解决。
from sklearn.pipeline import Pipeline
from sklearn.compose import ColumnTransformer
num_attribs = ['面积', '室数', '厅数', '卫数', '经度', '纬度', '发布时间', '楼层']
cat_hot_attribs = ['城区', '朝向', '租赁方式', '房源描述', '入住', '燃气', '用水', '用电', '电梯', '看房', '租期', '车位']
txt_tfi_attribs = ['房源标签', '配套设施']
tfi1_vector = TfidfVectorizer()
tfi2_vector = TfidfVectorizer()
full_pipeline = ColumnTransformer([
('num', StandardScaler(), num_attribs),
('1hot', OneHotEncoder(sparse=False), cat_hot_attribs),
('tfi1', tfi1_vector, txt_tfi_attribs[0]),
('tfi2', tfi2_vector, txt_tfi_attribs[1]),
])
构建流水线后,只需对待转换数据进行transform操作即可。
X_train_pre = full_pipeline.fit_transform(X_train)
X_train_pre.shape
(19884, 82)
我们最终得到的待训练数据共有19884行,82个特征。看看这些数据长什么样?
X_train_pre
array([[-0.74136774, -0.2880371 , -2.41066209, ..., 0. ,
0. , 0. ],
[ 2.08989315, 1.6623561 , 0.76543153, ..., 0. ,
0. , 0. ],
[ 0.85829466, 0.6871595 , 0.76543153, ..., 0. ,
0. , 0. ],
...,
[ 1.77845445, 0.6871595 , 0.76543153, ..., 0.31542954,
0.31732538, 0.31666146],
[-0.06186513, -0.2880371 , 0.76543153, ..., 0. ,
0. , 0. ],
[-0.79799296, -1.2632337 , -0.82261528, ..., 0. ,
0. , 0. ]])
模型训练
训练数据准备就绪,马上就可以开始令人兴奋的模型训练辣!
(博主仿佛闻到了2700x满载的香气)
博主作为机器学习新人,经验不多,只能摸着石头过河,中间也走了许多弯路,碰了许多壁,最终才勉强训练出两个像样的模型。中间对其他模型的取舍太过繁琐,感受最深是poly核的SVR模型,训练速度实在令人发指(慢),这里不再赘述,直接上最终两个模型的训练代码。
随机森林
# 直接用随机搜索对模型参数进行粗暴地尝试
from sklearn.model_selection import RandomizedSearchCV
from sklearn.ensemble import RandomForestRegressor
from scipy.stats import randint
from sklearn.externals import joblib
params = {
'n_estimators': randint(100, 300),
'max_features': randint(10, 40),
'max_depth': randint(10, 40)
}
forest_reg = RandomForestRegressor(oob_score=True, random_state=27, n_jobs=-1)
rnd_search_forest = RandomizedSearchCV(forest_reg, param_distributions=params, n_jobs=-1, verbose=2,
n_iter=250, cv=4, scoring='neg_mean_squared_error', random_state=27)
rnd_search_forest.fit(X_train_pre, y_train)
rfr_model = rnd_search_forest.best_estimator_
joblib.dump(rfr_model, "rfr_model.pkl") # 保存训练好的模型
rfr_model
RandomForestRegressor(bootstrap=True, criterion='mse', max_depth=37,
max_features=37, max_leaf_nodes=None, min_impurity_decrease=0.0,
min_impurity_split=None, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
n_estimators=110, n_jobs=None, oob_score=True, random_state=27,
verbose=0, warm_start=False)
# 查看包外检验分数,返回的是R^2分数
rfr_model.oob_score_
0.7993653827925424
emmmm,大约是0.8,接下来对测试集进行检测。
from sklearn.metrics import r2_score
X_test_pre = full_pipeline.transform(X_test) # 用先前建立的流水线处理测试集特征
y_pred = rfr_model.predict(X_test_pre)
r2 = r2_score(y_test, y_pred)
r2
0.8135492632947361
最终的随机森林模型R^2 = 0.8135,和包外检验分数相当,性能中规中矩。
xgboost
另一个模型是xgboost,总体流程和随机森林差不太多,只在参数设置上有所出入,直接上代码。
from xgboost import XGBRegressor
from scipy.stats import uniform, randint, reciprocal
params ={'n_estimators': randint(100, 300),
'max_depth': randint(3, 10),
'gamma': uniform(0, .2),
'min_child_weight': randint(1, 7),
'subsample': uniform(.5, .4),
'learning_rate': reciprocal(.05, .3)}
xg = XGBRegressor(random_state=27, n_jobs=-1)
rnd_search_xg = RandomizedSearchCV(xg, param_distributions=params, n_jobs=-1, verbose=2, n_iter=250,
cv=4, scoring='neg_mean_squared_error', random_state=27)
rnd_search_xg.fit(X_train_pre, y_train)
xg_model = rnd_search_xg.best_estimator_
joblib.dump(xg_model, "xg_model.pkl")
xg_model
XGBRegressor(base_score=0.5, booster='gbtree', colsample_bylevel=1,
colsample_bytree=1, gamma=0.1676707349877542,
learning_rate=0.06446131915732367, max_delta_step=0, max_depth=7,
min_child_weight=2, missing=None, n_estimators=231, n_jobs=-1,
nthread=None, objective='reg:linear', random_state=27, reg_alpha=0,
reg_lambda=1, scale_pos_weight=1, seed=None, silent=True,
subsample=0.6200910997148384)
X_test_pre = full_pipeline.transform(X_test)
y_pred = xg_model.predict(X_test_pre)
r2 = r2_score(y_test, y_pred)
r2
0.8041480021447124
模型的决定系数R^2:
| 模型 | R^2 |
|---|---|
| 随机森林 | 0.80415 |
| xgboost | 0.81355 |
最终得到的两个模型R^2分数都在0.8,性能一般,这将导致在之后的房租预测中可能会出现较大的偏差。在性能调参上我为了节省时间,只使用了简便直接的随机搜索,得到的模型参数比较粗糙。同学们如果有时间或计算资源,可以进行更细粒度的GridSearchCV来进行模型调参,相信应该能得到一定的性能提升。但想要在质上实现飞跃,比如到达0.95左右(痴心妄想 ),还是需要更多的数据量以及更好的特征工程来实现。
预测数据
好容易训练好了模型,不拿来用一用怎么甘心呢?先拿测试集来趁趁手。
测试集
## 随机森林模型
## 随机选取5条数据
X_some = X_test.sample(5, random_state=27)
X_some_pre = full_pipeline.transform(X_some)
y_some_pred = rfr_model.predict(X_some_pre)
print("真实房租为: ", y_test.sample(5, random_state=27).values)
print("房租预测为:", y_some_pred)
真实房租为: [5500 2000 7000 4300 1900]
房租预测为: [6886.36 2877.27 7195.62 5270.91 2630.49]
## xgboost模型
## 随机选取5条数据
X_some = X_test.sample(5, random_state=27)
X_some_pre = full_pipeline.transform(X_some)
y_some_pred = xg_model.predict(X_some_pre)
print("真实房租为: ", y_test.sample(5, random_state=27).values)
print("房租预测为:", y_some_pred)
真实房租为: [5500 2000 7000 4300 1900]
房租预测为: [5746.31 3906.47 7000.49 5485.71 2767.68 ]
xgboost和随机森林的预测结果差异不大,都存在一定的偏差。
随机选取的5条测试集数据显然不具有代表性,下面对整个测试集进行预测。同时调用训练模型的feature_importances_找出各特征重要性。

图11. 测试集上的预测精度与各特征重要性
通过训练模型得到的特征重要性显示(图11右侧),面积确实是预测房租最重要的特征,其他特征也有不同程度的影响。而相比于随机森林模型,xgboost对面积特征的依赖性较弱,分配了更多权重给其他特征。
测试集上真实值和预测值的曲线显示(图11左侧,上图为预测值的曲线,下图为预测值和真实值百分比例),两个模型的预测趋势相当。在<50k的区间预测结果波动较大,普遍偏高,<2k的区域严重偏高,超过50k的高价区域波动较小,但预测值严重偏低。对高价区的预测整体偏低说明高价房在除了面积,经纬度等模型包含的特征之外,还存在其他未获知的影响因素,比如品牌溢价,奢侈品属性?或未可知。同时,高价区的异常很可能会影响低价区的预测结果。因为考虑到与其各项特征不匹配的高价,模型会调高各项特征权重去拟合高价区域,导致最终的模型对低价区域的预测结果偏高。<2k的极低价区同理,效果相反。
迭代
由于预测模型在不同价位区间的预测有较明显的分化,高价区预测结果偏低,低价区则偏高。可以通过将数据集按价格分层,只关注感兴趣的价格区间(对于无产阶级的博主来说当然就是低价区啦 ),进行针对性训练,几乎可以肯定(safe but not certain)能够提高模型性能。
说干就干!这里博主选择了房屋数量相对集中,价格也适合外来工作者的区间(2k<价格<10k),再贵住不起了, 同时排除极低值和高价区对预测模型的影响。
df = df.query('价格 <= 20000')
df = df.query('价格 >= 2000')
df = df.reset_index(drop=True)
在整个机器学习流水线的前端过滤掉价格大于10000和小于2000的房子,然后重新跑一遍预处理和模型训练过程,得到预测模型。
直接来看最终的预测结果吧。
## 随机森林模型
## 随机选取5条数据
X_some = X_test.sample(5, random_state=27)
X_some_pre = full_pipeline.transform(X_some)
y_some_pred = rfr_model.predict(X_some_pre)
print("真实房租为: ", y_test.sample(5, random_state=27).values)
print("房租预测为:", y_some_pred)
真实房租为: [ 6500 14600 9000 3800 2300]
房租预测为: [ 6772.54 13702.60 9347.11 5129.08 2213.78 ]
## xgboost模型
## 随机选取5条数据
X_some = X_test.sample(5, random_state=27)
X_some_pre = full_pipeline.transform(X_some)
y_some_pred = xg_model.predict(X_some_pre)
print("真实房租为: ", y_test.sample(5, random_state=27).values)
print("房租预测为:", y_some_pred)
真实房租为: [ 6500 14600 9000 3800 2300]
房租预测为: [ 6918.61 13565.48 9949.25 5590.76 2222.55]
| 模型 | R^2 |
|---|---|
| 随机森林 | 0.85038 |
| xgboost | 0.86037 |
Bravo!过滤价格后的预测模型R^2提高了大约0.05,预测误差也有所减小。
 图11. 过滤数据后测试集上的预测精度与各特征重要性
图11. 过滤数据后测试集上的预测精度与各特征重要性
这一次的预测曲线就好看多了,但总体上仍有低价偏高,高价偏低的趋势,中间价位比较平稳。同时,面积作为最重要的特征在权重上有所降低,在随机森林模型中从超过0.4跌到不足0.3,分配了更多的权重给其他特征,这种变化或许正是模型精度提高的关键。此外,在不满4k的价格区间处有两个明显的异常波峰,推测是某些尚未可知的因素导致了房屋的真实价格远低于预测价格,例如房东急用钱,环境不好,房屋有缺陷等等(甚至是凶宅,闹鬼······ )。一般来说商人只会描述商品的优点,不太会提及其缺陷。链家网也是同理,对于房屋的缺陷信息几乎没有提供,我们也无从获取,除非一一实地考察,但这也有点魔幻现实了。
自己的房屋数据
总的来说,通过过滤数据的价格,预测模型性能得到了较大的提升。但光测试别人的数据怎么过瘾,自己的数据怎么样呢,房子租贵了吗?看中的房子又值多少?同学们可以将自己房子的数据代入模型,得到房租的预测值。这里博主以自己租的房子为例,选用性能稍好一点的xgboost模型来进行预测。
X_mine = pd.DataFrame(
[[37, 1, 1, 1, 121.42782961658139, 31.219239252096727, 0.5, 6, '随时入住', '有燃气', '民水', '民电', '没电梯', '需提前预约', '1年以内',
'租用车位', '长宁', '朝南', '整租', '有描述', '精装, 季付价, 近地铁', '冰箱, 空调, 天然气, 衣柜, 洗衣机, 床, 电视']],
columns=['面积','室数','厅数','卫数','经度','纬度','发布时间', '楼层', '入住','燃气', '用水', '用电','电梯','看房',
'租期', '车位', '城区','朝向','租赁方式', '房源描述', '房源标签','配套设施']
)
y_mine = [5200]
X_mine_pre = full_pipeline.transform(X_mine)
y_mine_pred = rfr_model.predict(X_mine_pre)
print("真实房租为: ", y_mine)
print("房租预测为: ", y_mine_pred)
真实房租为: [5200]
房租预测为: [5673.4375]
博主的真实房租低于模型预测470元左右!不过不要高兴得太早,除了模型带来的误差外,还要考虑到该房并不是在链家网上租赁的,渠道不同,价格也会有差异,这里只是作为参考。一般来说,租房同买菜一样,是可以讲价的,导致最终的成交价格低于网上挂售的价格(当初博主租的房子也是杀过价的)。所以同学们可以以预测价格作为基础,适当的杀价,最终达成合理的成交价格。
小结
通过对链家网租房信息的爬取和分析,获得以下结论:
-
通过词云可知,交通和生活的便利程度是租客们最优先考虑的问题,其次是住房的户型,采光,楼层等房屋属性。根据集成的思想,大多数人做出的选择往往比一个最精明的人具有更好的泛化性。所以这时候我们从从众也无妨,在租房时优先考虑交通和生活的方便与否,其次考虑户型等其他因素。
-
房租高低与房屋面积的相关性最大,与地理位置(经纬度)、楼层等特征也有一定相关性。同学们应根据自己的经济水平,量力而行。比如同时考虑对价格影响较大的面积、地理位置,和对价格影响较小的交通、配套设施等属性,选择远离市区,小户型,但交通、生活和装修都不错的房子,做到品质和价格的兼顾。
-
最终得到的xgboost预测模型决定系数R^2=0.86037,性能还不错。测试集发现该预测模型的预测结果有低价区偏高,高价区偏低的趋势,总体比较平稳。使用该模型预测得博主的房租为5673,高出真实房价5200,考虑到误差及其他因素,基本可以确定(safe but not certain)博主没有被宰,但愿吧。
本文还有许多可以改进的地方:
-
爬虫由于只使用了
requests和BeautifulSoup两个包,单线程爬取,效率较低。有能力可以考虑分布式爬取或scrapy框架,在待爬数据更大时很有用。 -
最终得到的预测模型性能虽然不错,但还有提高空间。一方面在模型的调参上可以使用网格搜索进一步细化参数,找出最优参数,理论上还能提升少量的性能。另一方面观察到住房发布时间大多集中在一个月内,可以每个月爬取一次数据,增大训练数据量,从而提高性能。
-
在房源描述的处理上还是过于粗糙。有条件的同学可以对房源描述做特征抽取,对最终的预测结果可能会有所帮助。