【图文详细 】Hive 函数、Hive 函数、Hive 函数
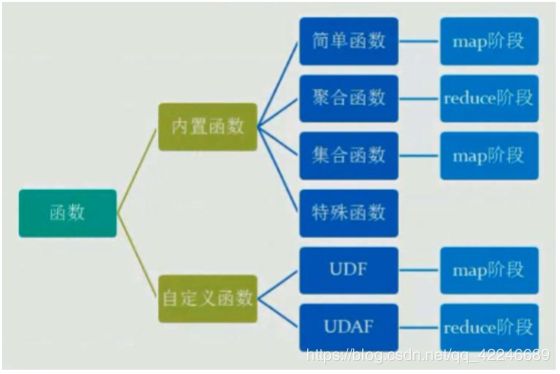
1.hive内置函数
1.1、内容较多,见《Hive 官方文档》
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF
1.2、测试内置函数的快捷方式:
第一种方式:直接使用,例如:select concat('a','a') ? aa
第二种方式:
- 创建一个 dual 表 create table dual(id string);
- load 一个文件(一行,一个空格)到 dual 表
- select substr('huangbo',2,3) from dual;
1.3、查看内置函数:
show functions;
显示函数的详细信息: desc function abs;
显示函数的扩展信息: desc function extended concat;
1.4、内置函数列表
| 一、关系运算: 1. 等值比较: = 2. 等值比较:<=> 3. 不等值比较: <>和!= 4. 小于比较: < 5. 小于等于比较: <= 6. 大于比较: > 7. 大于等于比较: >= 8. 区间比较 9. 空值判断: IS NULL 10. 非空判断: IS NOT NULL 11. LIKE 比较: LIKE 12. JAVA 的 LIKE 操作: RLIKE 13. REGEXP 操作: REGEXP 1. 加法操作: + 2. 减法操作: – 3. 乘法操作: * 4. 除法操作: / 5. 取余操作: % 6. 位与操作: & 7. 位或操作: | 8. 位异或操作: ^ 9.位取反操作: ~ 1. 逻辑与操作: AND 、&& 2. 逻辑或操作: OR 、|| 3. 逻辑非操作: NOT、! 1. map 结构 2. struct 结构 3. named_struct 结构 4. array 结构 5. create_union 1. 获取 array 中的元素 2. 获取 map 中的元素 3. 获取 struct 中的元素
六、数值计算函数 1. 取整函数: round 2. 指定精度取整函数: round 3. 向下取整函数: floor 4. 向上取整函数: ceil 5. 向上取整函数: ceiling 6. 取随机数函数: rand 7. 自然指数函数: exp 8. 以 10 为底对数函数: log10 9. 以 2 为底对数函数: log2 10. 对数函数: log 11. 幂运算函数: pow 12. 幂运算函数: power 13. 开平方函数: sqrt 14. 二进制函数: bin 15. 十六进制函数: hex 16. 反转十六进制函数: unhex 17. 进制转换函数: conv 18. 绝对值函数: abs 19. 正取余函数: pmod 20. 正弦函数: sin 21. 反正弦函数: asin 22. 余弦函数: cos 23. 反余弦函数: acos 24. positive 函数: positive 25. negative 函数: negative 1. map 类型大小:size 2. array 类型大小:size 3. 判断元素数组是否包含元素:array_contains 4. 获取 map 中所有 value 集合 5. 获取 map 中所有 key 集合 6. 数组排序 1. 二进制转换:binary 2. 基础类型之间强制转换:cast 1. UNIX 时间戳转日期函数: from_unixtime 2. 获取当前 UNIX 时间戳函数: unix_timestamp 3. 日期转 UNIX 时间戳函数: unix_timestamp 4. 指定格式日期转 UNIX 时间戳函数: unix_timestamp 5. 日期时间转日期函数: to_date 6. 日期转年函数: year 7. 日期转月函数: month 8. 日期转天函数: day 9. 日期转小时函数: hour 10. 日期转分钟函数: minute 11. 日期转秒函数: second 12. 日期转周函数: weekofyear 13. 日期比较函数: datediff 14. 日期增加函数: date_add 15. 日期减少函数: date_sub 1. If 函数: if 2. 非空查找函数: COALESCE 3. 条件判断函数:CASE 1. 字符 ascii 码函数:ascii 2. base64 字符串 3. 字符串连接函数:concat 4. 带分隔符字符串连接函数:concat_ws 5. 数组转换成字符串的函数:concat_ws 6. 小数位格式化成字符串函数:format_number 7. 字符串截取函数:substr,substring 8. 字符串截取函数:substr,substring 9. 字符串查找函数:instr 10. 字符串长度函数:length 11. 字符串查找函数:locate 12. 字符串格式化函数:printf 13. 字符串转换成 map 函数:str_to_map 14. base64 解码函数:unbase64(string str) 15. 字符串转大写函数:upper,ucase 16. 字符串转小写函数:lower,lcase 17. 去空格函数:trim 18. 左边去空格函数:ltrim 19. 右边去空格函数:rtrim 20. 正则表达式替换函数:regexp_replace 21. 正则表达式解析函数:regexp_extract 22. URL 解析函数:parse_url 23. json 解析函数:get_json_object 24. 空格字符串函数:space 25. 重复字符串函数:repeat 26. 左补足函数:lpad 27. 右补足函数:rpad 28. 分割字符串函数: split 29. 集合查找函数: find_in_set 30. 分词函数:sentences 31. 分词后统计一起出现频次最高的 TOP-K 32. 分词后统计与指定单词一起出现频次最高的 TOP-K 1. 调用 Java 函数:java_method 2. 调用 Java 函数:reflect 3. 字符串的 hash 值:hash 1. xpath 2. xpath_string 3. xpath_boolean 4. xpath_short, xpath_int, xpath_long 5. xpath_float, xpath_double, xpath_number 1. 个数统计函数: count 2. 总和统计函数: sum 3. 平均值统计函数: avg 4. 最小值统计函数: min 5. 最大值统计函数: max 6. 非空集合总体变量函数: var_pop 7. 非空集合样本变量函数: var_samp 8. 总体标准偏离函数: stddev_pop 9. 样本标准偏离函数: stddev_samp 10.中位数函数: percentile 11. 中位数函数: percentile 12. 近似中位数函数: percentile_approx 13. 近似中位数函数: percentile_approx 14. 直方图: histogram_numeric 15. 集合去重数:collect_set 16. 集合不去重函数:collect_list 1.数组拆分成多行:explode(array) 2.Map 拆分成多行:explode(map) |
2.hiva自定义函数UDF
当 Hive 提供的内置函数无法满足业务处理需要时,此时就可以考虑使用用户自定义函数
UDF(user-defined function)作用于单个数据行,产生一个数据行作为输出。(数学函数,字 符串函数)
UDAF(用户定义聚集函数 User- Defined Aggregation Funcation):接收多个输入数据行,并产 生一个输出数据行。(count,max)
UDTF(表格生成函数 User-Defined Table Functions):接收一行输入,输出多行(explode)
2.1.一个简单的 UDF 示例
2.1.1、先开发一个简单的 java 类,继承 org.apache.hadoop.hive.ql.exec.UDF,重载 evaluate 方法
| Package com.ghgj.hive.udf import org.apache.hadoop.hive.ql.exec.UDF; // 必须是 public,并且 evaluate 方法可以重载 public String evaluate(String field) { String result = field.toLowerCase(); return result; } } |
2.1.2、打成 jar 包上传到服务器
2.1.3、将 jar 包添加到 hive 的 classpath hive>add JAR /home/hadoop/hivejar/udf.jar; 查看加入的 jar 的命令: hive> list jar;
2.1.4、创建临时函数与开发好的 class 关联起来
| hive>create temporary function tolowercase as 'com.ghgj.hive.udf.ToLowerCase'; |
2.1.5、至此,遍可以在hql在使用自定义的函数
select tolowercase(name),age from student;
2.2、Json 数据解析 UDF 开发
现在原始json数据(rating.json)如下,


现在需要将数据导入到 hive 仓库中,并且最终要得到这么一个结果:

2.3、Transform 实现
Hive 的 TRANSFORM 关键字提供了在 SQL 中调用自写脚本的功能。适合实现 Hive 中没有的 功能又不想写 UDF 的情况
具体以一个实例讲解。
Json 数据: {"movie":"1193","rate":"5","timeStamp":"978300760","uid":"1"} 需求:把 timestamp 的值转换成日期编号 。
1、先加载 rating.json 文件到 hive 的一个原始表
crate_json create table rate_json(line string) row format delimited; load data local inpath '/home/hadoop/rating.json' into table rate_json;
2、创建 rate 这张表用来存储解析 json 出来的字段:
create table rate(movie int, rate int, unixtime int, userid int) row format delimited fields terminated by '\t';
解析 json,得到结果之后存入 rate 表:
insert into table rate select get_json_object(line,'$.movie') as moive, get_json_object(line,'$.rate') as rate, get_json_object(line,'$.timeStamp') as unixtime, get_json_object(line,'$.uid') as userid from rate_json;
3、使用 transform+python 的方式去转换 unixtime 为 weekday 先编辑一个 python 脚本文件


保存文件 然后,将文件加入 hive 的 classpath:

// 创建最后的用来存储调用 python 脚本解析出来的数据的表:
lastjsontable create table lastjsontable(movie int, rate int, weekday int, userid int) row format delimited fields terminated by '\t';
最后查询看数据是否正确: select distinct(weekday) from lastjsontable;